满二叉树:只要是有节点的层,每一层节点都是满的的树。
完全二叉树:在满二叉树的基础上,从最右的叶子节点向左删除形成的树。
我们先看对于一个树上的几点来说的四种基本情况:
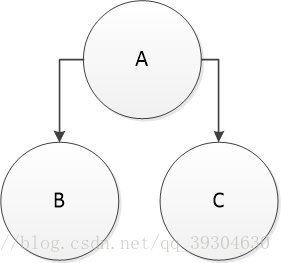
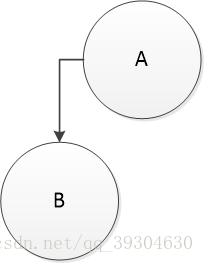
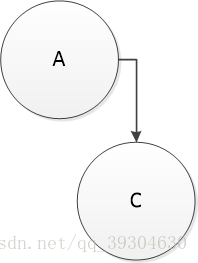

通过完全二叉树的性质我们可以知道第三种情况是绝对不可能出现的,因此对于第三种情况直接false。
第四种情况就是叶子节点。
第一种情况是内部节点。
第二种情况:就比较amazing,当你在进行BFS的时候,如果出现了这种情况,你可以自信的认为后续遍历到的节点必须是叶子节点。


如图,当遍历到E的时候,由于E的节点性质符合情况二,故而后续的节点应该都是叶子节点。如果满足,则是完全二叉树,否则不是。
ok了?no。对于满二叉树来说,它也是完全二叉树,可是它只有情况一和四。
我们先整理一下算法:
1)BFS这棵树
2)如果碰到某个节点没有左孩子却有右孩子,直接false
3)如果碰到某个几点有左孩子没有右孩子,进入到判断后续节点是否全部为叶子节点的阶段
那么如何将满二叉树给加进去呢?我们知道,不管是满二叉树还是完全二叉树,BFS下来他们访问的节点一定是先内部节点,后叶子节点。
经由2)步骤后,剩下的节点状态只可能是左右都有,有左无右,叶子,上述分析后可知,对于有左无右和叶子,他们都可以开启判断阶段,统筹他们的方法:if(Node.left==NULL||Node.right==NULL)state=true; 注:这段代码的前提是先判断过程2)!!
求完全二叉树的节点个数?O(logn)的时间复杂度。
弱化约束:不要求时间复杂度,那么可以BFS,时间复杂度O(n)。
强化约束:很显然,完全二叉树是一个足够特殊的结构,特殊到有些性质可以用来优化算法。
完全二叉树内最特殊的节点就是:
当遇到这种节点之后,我们可以直接回答,在B节点同一层的左边以及A节点同一层的右边,全都是叶子节点。
E、G节点符合上述所说,观察后可以知道,A节点的右子树是满二叉树。于是右子树以及A节点的个数总量为2^hight。
然后我们现在的任务是求左子树的节点数量,对于一棵完全二叉树来说,他的任意一个节点都可以作为一个小的完全二叉树的根节点:我们看到了递归性质。
B节点,左子树和右子树的高度一致,那么左子树必定是满二叉树,又是一个2^hight'。
递归来到E节点。右子树是一棵满二叉树,高度为0。
递归来到G节点,左子树是一棵满二叉树,高度为0。
递归成null,返回0。
算法概述:
从根节点开始,通过遍历左子树左链长度和右子树左链长度得到两棵树的高度L,R,由于完全二叉树的性质,L、R必满足abs(R-L)==1。
A.当前遇到的节点为NULL,return 0。
B.高度一致,则左子树为满二叉树,return (1<<L)+process(Node->right);
C.高度不一致,则右子树为满二叉树,return (1<<R)+process(Node->left);
复杂度分析:总复杂度也就是遍历树上某一条链,为O(logn)。