
在第一部分中,我们知道了为什么以及如何加载预先训练好的神经网络,我们可以用自己的分类器代替已有神经网络的分类器。那么,在这篇文章中,我们将学习如何训练分类器。
训练分类器
首先,我们需要为分类器提供待分类的图像。本文使用ImageFolder加载图像,预训练神经网络的输入有特定的格式,因此,我们需要用一些变换来调整图像的大小,即在将图像输入到神经网络之前,对其进行裁剪和标准化处理。
具体来说,将图像大小调整为224*224,并对图像进行标准化处理,即均值为 [0.485,0.456,0.406],标准差为[0.229,0.224,0.225],颜色管道的均值设为0,标准差缩放为1。
然后,使用DataLoader批量传递图像,由于有三个数据集:训练数据集、验证数据集和测试数据集,因此需要为每个数据集创建一个加载器。一切准备就绪后,就可以训练分类器了。
在这里,最重要的挑战就是——正确率(accuracy)。
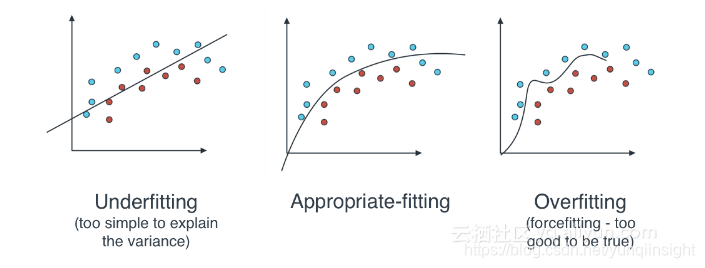
让模型识别一个已经知道的图像,这不算啥事,但是我们现在的要求是:能够概括、确定以前从未见过的图像中花的类型。在实现这一目标过程中,我们一定要避免过拟合,即“分析的结果与特定数据集的联系过于紧密或完全对应,因此可能无法对其他数据集进行可靠的预测或分析”。
隐藏层
实现适当拟合的方法有很多种,其中一种很简单的方法就是:隐藏层。
我们很容易陷入这样一种误区:拥有更多或更大的隐藏层,能够提高分类器的正确率,但事实并非如此。
增加隐藏层的数量或大小以后,我们的分类器就需要考虑更多不必要的参数。举个例子来说,将噪音看做是花朵的一部分,这会导致过拟合,也会降低精度,不仅如此,分类器还需要更长的时间来训练和预测。
因此,我建议你从数量较少的隐藏层开始,然后根据需要增加隐藏层的数量或大小,而不是一开始就使用特别多或特别大的隐藏层。
在第一部分介绍的《AI Programming with Python Nanodegree》课程中的花卉分类器项目中,我只需要一个小的隐藏层,在第一个完整训练周期内,就得到了70%以上的正确率。
数据增强
我们有很多图像可供模型训练,这非常不错。如果拥有更多的图像,数据增强就可以发挥作用了。每个图像在每个训练周期都会作为神经网络的输入,对神经网络训练一次。在这之前,我们可以对输入图像做一些随机变化,比如旋转、平移或缩放。这样,在每个训练周期内,输入图像都会有差异。
增加训练数据的种类有利于减少过拟合,同样也提高了分类器的概括能力,从而提高模型分类的整体准确度。
Shuffle
在训练分类器时,我们需要提供一系列随机的图像,以免引入任何误差。
举个例子来说,我们刚开始训练分类器时,我们使用“牵牛花”图像对模型进行训练,这样一来,分类器在后续训练过程中将会偏向“牵牛花”,因为它只知道“牵牛花”。因此,在我们使用其他类型的花进行训练时,分类器最初的偏好也将持续一段时间。
为了避免这一现象,我们就需要在数据加载器中使用不同的图像,这很简单,只需要在加载器中添加shuffle=true,代码如下:
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)Dropout
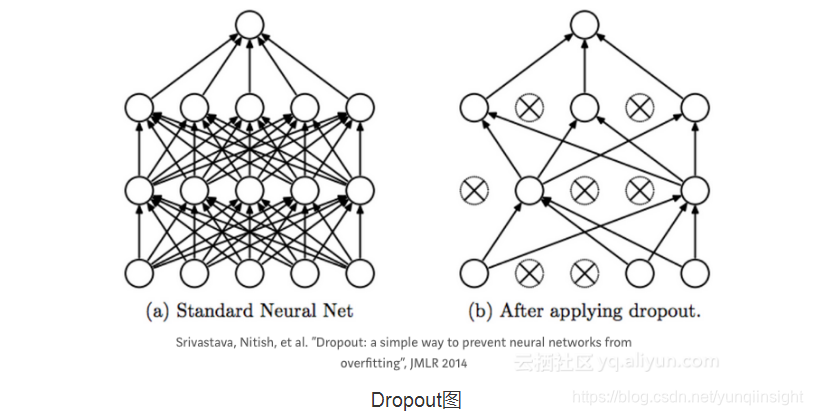
有的时候,分类器中的节点可能会导致其他节点不能进行适当的训练,此外,节点可能会产生共同依赖,这就会导致过拟合。
Dropout技术通过在每个训练步骤中使一些节点处于不活跃状态,来避免这一问题。这样一来,在每个训练阶段都使用不同的节点子集,从而减少过拟合。
除了过拟合,我们一定要记住,学习率( learning rate )是最关键的超参数。如果学习率过大,模型的误差永远都不会降到最小;如果学习率过小,分类器将会训练的特别慢,因此,学习率不能过大也不能过小。一般来说,学习率可以是0.01,0.001,0.0001……,依此类推。
最后,在最后一层选择正确的激活函数会对模型的正确率会产生特别大的影响。举个例子来说,如果我们使用 negative log likelihood loss(NLLLoss),那么,在最后一层中,建议使用LogSoftmax激活函数。
结论
理解模型的训练过程,将有助于创建能够概括的模型,在预测新图像类型时的准确度更高。
在本文中,我们讨论了过拟合将会如何降低模型的概括能力,并学习了降低过拟合的方法。另外,我们也强调了学习率的重要性及其常用值。最后,我们知道,为最后一层选择正确的激活函数非常关键。
现在,我们已经知道应该如何训练分类器,那么,我们就可以用它来预测以前从未见过的花型了!
原文链接
本文为云栖社区原创内容,未经允许不得转载。