序
本文主要聊一下开源主流产品的partition方式。
partition
一般来说,数据库的繁忙体现在:不同用户需要访问数据集中的不同部分,这种情况下,我们把数据的各个部分存放在不同的服务器/节点中,每个服务器/节点负责自身数据的读取与写入操作,以此实现横向扩展,这种技术成为分片,即sharding。
理想情况下,不同的节点服务于不同的用户,每个用户只需要与一个节点通信,并且很快就能获得服务器的响应。当然理想情况比较罕见,为了获得近乎理想的效果,必须保证需要同时访问的那些数据都存放在同一个节点上,而且节点必须排布好这些数据块,使得访问速度最优。
分片可以极大地提高读取性能,但对于要频繁写的应用,帮助不大。另外,分片对改善故障恢复能力并没有帮助,但是它减少了故障范围,只有访问这个节点的那些用户才会受影响,其余用户可以正常访问。虽然数据缺失了一部分,但是还是其余部分还是可以正常运转。
问题点
1.怎样分片/路由
怎样存放数据,才能保证用户基本上只需要从一个节点获取它。如果使用的是面向聚合的数据库而非面向元组的数据库,那么就非常容易解决了。之所以设计聚合这一结构,就是为了把那些经常需要同时访问的数据存放在一起。因此,可以把聚合作为分布数据的单元。
另外还要考虑的是:如何保持负载均衡。即如何把聚合数据均匀地分布在各个节点中,让它们需要处理的负载量相等。负载分布情况可能随着时间变化,因此需要一些领域特定的规则。比如有的需要按字典顺序,有的需要按逆域名序列等。
很多NoSQL都提供自动分片(auto-sharding)功能,可以让数据库自己负责把数据分布到各个分片,并且将数据访问请求引导到适当的分片上。
2.怎样rebalance
在动态增减机器或partition的情况下,如果重新rebalance,使数据分布均匀或者避免热点访问
分片方式
这里主要分为两大类,一类是哈希分片(
hash based partitionning),一类是范围分片(range based partitioning)
1.哈希分片(hash based partitionning)
通过哈希函数来进行数据分片,主要有Round Robbin、虚拟桶、一致性哈希三种算法。
A、Round Robbin
俗称哈希取模算法,H(key) = hash(key) mode K(其中对物理机进行从0到K-1编号,key为某个记录的主键,H(key)为存储该数据的物理机编号)。好处是简单,缺点是增减机器要重新hash,缺乏灵活性。它实际上是将物理机和数据分片两个功能点合二为一了,因而缺乏灵活性。
B、虚拟桶
membase在待存储记录和物理机之间引入了虚拟桶,形成两级映射。其中key-partition映射采用哈希函数,partition-machine采用表格管理实现。新加入机器时,只需要将原来一些虚拟桶划分给新的机器,只要修改partition-machine映射即可,具有灵活性。
C、一致性哈希
一致性哈希是分布式哈希表的一种实现算法,将哈希数值空间按照大小组成一个首尾相接的环状序列,对于每台机器,可以根据IP和端口号经过哈希函数映射到哈希数值空间内。通过有向环顺序查找或路由表(Finger Table)来查找。对于一致性哈希可能造成的各个节点负载不均衡的情况,可以采用虚拟节点的方式来解决。一个物理机节点虚拟成若干虚拟节点,映射到环状结构的不同位置。
哈希分片的好处是可以使数据均匀分布,但是可能造成数据无序不方便range
mongo2.4版本+支持hash partition
2.范围分片(range based partitioning)
这个是根据key排序来分布的,比如字典按24个首字母来分,这个的好处是方便range,但是容易造成数据分布不均匀以及热点访问问题(比如个别节点的数据访问量/查询/计算量大,造成负载特别高)。
Bigtable,hbase、2.4版本之前的mongo都使用此方式。
索引分片策略(secondary indexes)
除了数据本身要分片外,索引也需要分片。比较著名的两个反向索引分片策略就是document-based partitioning以及term-based partitioning。然后再此两个基本的策略之上衍生出了hybrid的方案。
1.local index(document-based partitioning)
也称作document-based partitioning.在每个partition本地维护一份关于本地数据的反向索引。这种方式的话,主要使用的是scatter/gather模式,即每次查询需要发送请求给所有的partition,然后每个partition根据本地的索引检索返回,之后汇总得出结果。
- 好处
简单好维护 - 缺点
查询比较费劲,比如有n个partition,要查top k,则每个partition都要查top k,总共需要n*k份文档被汇总。
mongo,cassandra,es,solr采用此方案
2.global index(term-based partitioning)
也称作term-based partitioning,这种方式的话,创建的索引不是基于partition的部分数据,而是基于所有数据来索引的。只不过这些全局索引使用range-based partitioning的方式再分布到各个节点上。
- 好处
读取效率高,因为索引是有序的,基于range parititioning,非常快速找到索引,而且这些索引是全局的,立马就可以定位到文档的位置。 - 缺点
写入成本比较高,每个文档的写入都需要维护/更新全局的索引。另外一个缺点就是range-partitioning本身的带来的缺点,容易造成数据分布不均匀,造成热点,影响吞吐量。
dynamodb,riak支持此方案
rebalance
当partition所在节点坏掉,或者新增机器的时候,这个时候就涉及到partition的rebalance。原来本应该请求这个node的,现在都需要转移请求另外一个node的过程叫做rebalancing。
rebalancing的目标
- 均分数据存储以及读写请求,避免热点
- rebalancing期间不影响正常读写
- 要尽量快而且尽量少的网络及IO负载来完成
rebalance策略
直接哈希(模数固定)
即key-machine的直接映射,这个的缺点就是:增减机器要重新hash,缺乏灵活性。
两级映射(partition hashing,固定partition数目)
为了提升直接哈希的灵活性,引入了两级映射,即key-partition,partition-matchine/node这样两级,通过partition来解耦key跟machine/node的关联。对于新加入机器时,只需要将原来各个node的一些partition划分给新的机器,只要修改partition-machine映射即可,具有灵活性。
- 好处
相对于直接哈希来讲,节点增减的时候,只需要调整partiton-matchine的映射关系,客户端无需重新路由。 - 缺点
固定partition的话,需要一个合理的数目,每个partition大小需要合理确定。相当于这些固定数目的partition要均分整个数据集。如果数据集不断增长的话,如果原来partition个数太少,则每个partition大小则不断增加,造成节点恢复/rebalance相对耗时。如果原来partition个数太多,而数据集后续增长不多,则可能造成有些partition的数据量过少,无法达到均分效果。
Elasticsearch采用此方案,在创建索引的时候需指定shard/partition数目以及replication的数目
Couchbase引入了vBucket的概念在这里可以理解为虚拟的paritition。
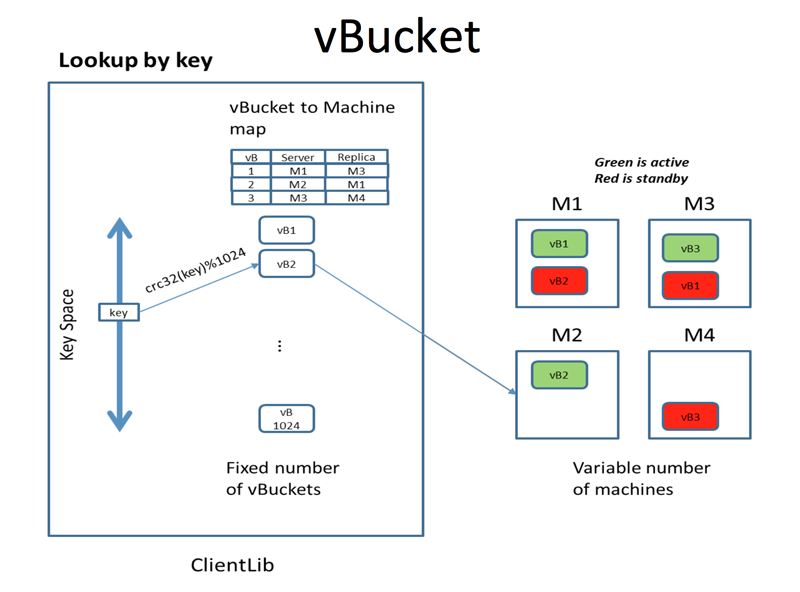
动态partition
partition的数目是动态变化的,根据设定的partition大小的阈值,来进行动态的分裂或合并。
hbase采用的就是这种方式
一致性哈希(hash ring)
一致性哈希与前两者有些不同,因为该算法把machine/node也一起进行了hash,然后与key的哈希值一起进行区间匹配,来确定key落在哪个machine/node上面。分布式缓存用到的比较多,比如redis就是用了一致性哈希。
具体如下:
- 将环形空间总共分成2^32个区
- 将key跟machine采用某种哈希算法转化为一个32位的二进制数,然后落到对应的区间范围内
- 每一个key的顺时针方向最近节点,就是key所归属的存储节点。
- 好处
节点增减的时候,整个环形空间的映射仍然会保持一致性哈希的顺时针规则,所以有一小部分key的归属会受到影响。当节点挂掉的时候,相当于缓存未命中,下次访问的时候重新缓存。 - 缺点
使用一般的hash函数的话,machine的映射分布非常不均匀,可能造成热点,对于这种情况,引入虚拟节点来解决。也就是借鉴了两级映射的模式,key-vnode,vnode-machine。将一个machine映射为多个vnode,然后分散到环形结构上,这样可以使得vnode分布均匀,然后最后每个machine的存储也相对均匀
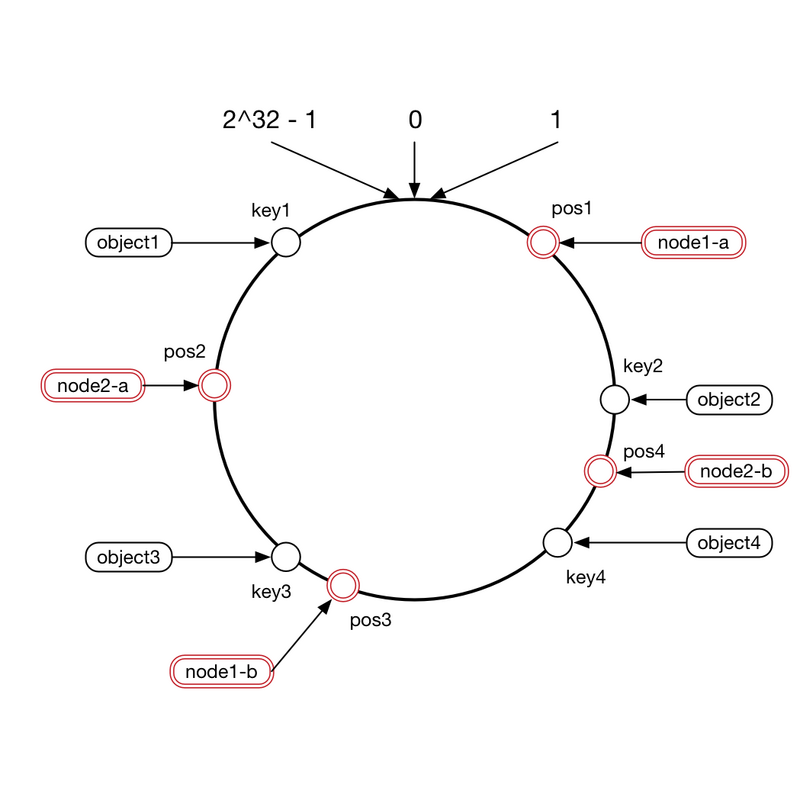
不过引入虚拟节点也会有问题,当新增machine的时候,也就相当于新增多个vnode分散到环上,但是这样子就会造成更多的范围的key需要rebalance。
1、提升单调性(通过环形算法减少增减节点时cache的迁移成本) 2、提升平衡性(通过虚拟节点,尽可能减少节点增减带来的cache分布不均匀问题)
小结
| 产品 | partition方式 | 索引分片策略 |
|---|---|---|
| redis | 一致性哈希 | - |
| elasticsearch | 固定partition两级映射 | local index |
| mongo | 2.4版本之前是范围分片,2.4+支持hash分片 | local index |
| kafka | 固定partition | - |
kafka的key到partition的映射高版本支持自定义策略,如果cluster增减node,对之前创建的topic不生效,需要调用reassign-partitions重新分布,避免热点
doc
- 大数据日知录--数据分片与路由
- 复制、分片和路由
- Inverted Index Partitioning Strategies for a Distributed Search Engine
- Comparison Between Document-based, Term-based and Hybrid Partitioning
- mongo sharding
- Elasticsearch Partitioning
- Partition Rebalance
- 漫画:什么是一致性哈希?
- 聊聊一致性哈希
- 一致性哈希
- 一致性哈希算法的理解与实践
- elasticseach日常维护之shard管理
- Cluster Level Shard Allocation
- The Authoritative Guide to Elasticsearch Performance Tuning (Part 3)
- elasticsearch源码分析之Allocation模块
- 缓存的进化之路—Couchbase的分布式架构
- How to Rebalance Topics in a Kafka Cluster
- Kafka Partitioning…
- kafka重新分配partition