参考链接:(https://blog.csdn.net/OnlyloveCuracao/art0icle/details/80768334)
原博主的代码可能因为单词发音的音频爬取有问题,导致无法将单词存入数据库,不过也非常感谢原博主,我根据源码做了一定删减和更改,下次可能会根据用户的需求,输入需求,爬取相应的单词。
主要步骤:
1.连接数据库
2.创建word单词表
3.获取网页主界面HTML代码
4.获取class(课程类型)界面HTML代码,如“考研课程”
5.获取course(课时内容,一门课程有多节课时)界面HTML,在course中得到word(单词)、pronunciation(发音)、translation(翻译)
ps:发音音频暂不考虑,好吧,博主我时间来不及了,老师在催了。。。
6.将数据存入数据库,over!
7.最后放主函数
ps:博主是个菜鸟,若有错欢迎指正。如果还有比博主还菜的同学,不知道某些变量是啥子,就print,代码里应该也有,只是注释掉了
1连接数据库:
输入相关数据,我数据库没有密码所以没写,db中的只是创建数据库时单词写错了,尬了
def conn(): # 连接数据库
db = pymysql.connect(host='localhost', user='root', password='', db='phython', port=3306)
print('已连接数据库')
return db
2创建word表
def create_table(db): # 创建一个单词表
cursor = db.cursor() # 创建游标
sql = 'CREATE TABLE IF NOT EXISTS word (id VARCHAR(255) NOT NULL,word VARCHAR(255) NOT NULL,' \
'trans VARCHAR(255) NOT NULL,word_type VARCHAR(255) NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql) # 执行sql语句
print('建表完成!')
db.close()
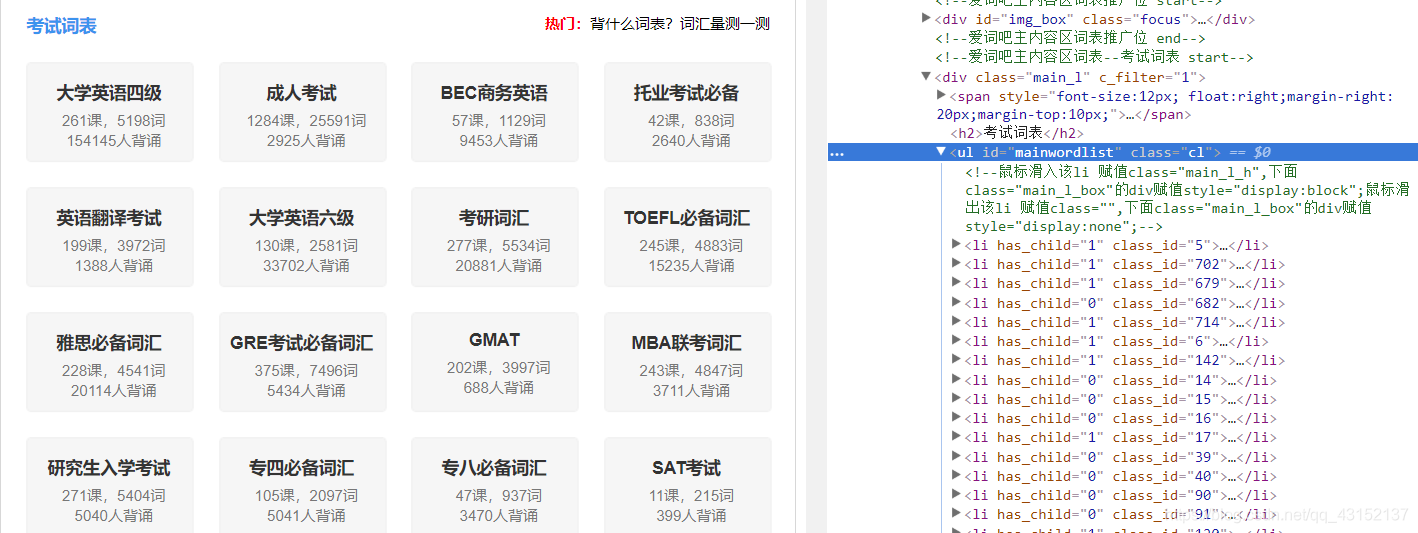
3获取网页主界面HTML
首先加一个请求头,有些网站会屏蔽爬虫的请求,所以加一个请求头起伪装作用
然后就看注释吧
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
def get_html(url): # 爬取主页
try:
html = requests.get(url, headers=header) # 使用requests库爬取
if html.status_code == 200: # 如果状态码是200,则表示爬取成功
print(url + '获取成功')
return html.text # 返回H5代码
else: # 否则返回空
print('获取失败')
return None
except: # 发生异常返回空
print('获取失败')
return None
4获取class的HTML,有效信息为class_id
class_id在div(类名‘main_l’)下的ul(类名‘cl’)标签里面的li中
ps:一门课程可能有多个class_id, 比如大学英语四级,就分为‘四级必备词汇’和‘四级救命词汇’, 它们的class_id不同
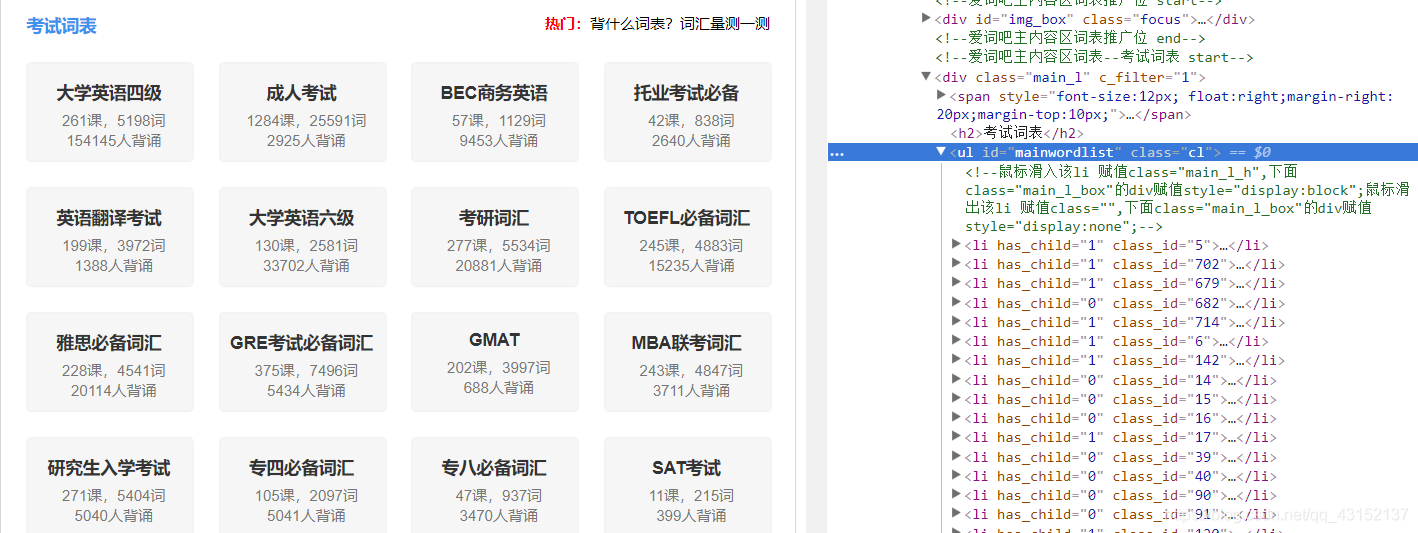
def get_url(html): # 解析首页得到所有的网页和课程id
class_list = [] # 定义存放class_id的列表
class_info = BeautifulSoup(html, "html.parser")
class_div = class_info.find('div', {'class': 'main_l'}) # 找到存放class_id的div
class_li = class_div.find('ul', {'class': 'cl'}).find_all('li') # 找到div下的ul标签内的所有li
for class_id in class_li:
class_list.append(class_id.get('class_id')) # 得到class_id
return class_list
5获取course的HTML,有效信息为:单词、发音、翻译
字典后面会有简略介绍,看注释或者百度一手嘛
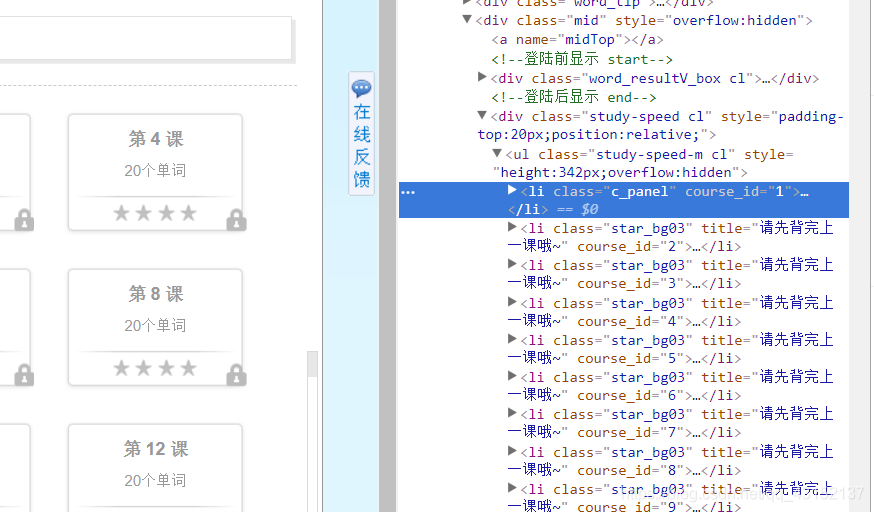
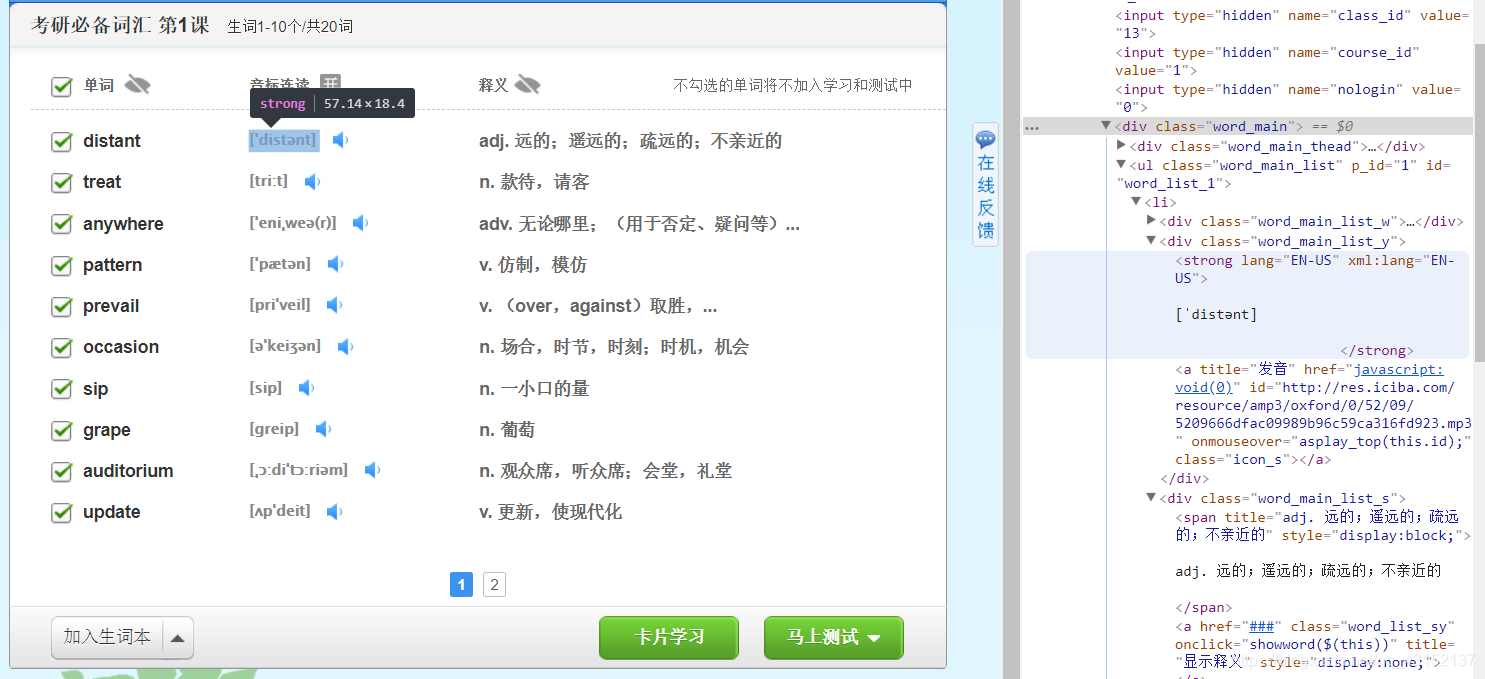
def get_info(word_html, type_name): # 爬取所有的单词、发音、翻译
word_all = {} # 字典,存放词汇所有相关内容
word_info = BeautifulSoup(word_html, "html.parser")
word_div = word_info.find_all('div', class_="word_main_list_w") # 单词div内容
pronunce_div = word_info.find_all('div', {'class': 'word_main_list_y'}) # 发音div内容
trans_div = word_info.find_all('div', {'class': 'word_main_list_s'}) # 翻译div内容
for i in range(1, len(word_div)):
key = word_div[i].span.get('title') # 获取单词
pronunce = pronunce_div[i].strong.string.split() # 获取发音
trans = trans_div[i].span.get('title') # 获取翻译
if len(pronunce) < 1: # 无发音则跳过本次循环
continue
word_all[key] = [pronunce[0], trans, type_name] # 字典结构:字典名={'key': ['value_1','value2_',....,'value_n'],}
print('创建数据成功')
return word_all
6将数据存入数据库
注释里有单词存储到字典的结构:字典名={key:[value1,value2,value3]}, key在本项目中就是word单词,value1为发音,value2为翻译,value3为词汇类型。如果要获取字典中的value,则为:字典名【key】【下标】,如word_dict【key】【0】就是value1的值(博客里不能连用2个英文方括号,便用中文的代替了)
构造sql语句,Python里占位符为%s
def insert_words(word_dict, db): # 爬取数据到数据库
cursor = db.cursor() # 创建一个游标
# print(word_dict)
# word_dict是一个字典,模型:{'distant': ['[ˈdistənt]', 'adj. 远的;遥远的;疏远的;不亲近的', '考研必备词汇']}
for key in word_dict:
sql = 'INSERT INTO word(word, pronunciation, trans, word_type) values(%s, %s, %s, %s)' # 构造sql语句
try:
cursor.execute(sql, (key, word_dict[key][0], word_dict[key][1], word_dict[key][2]))
# key就是单词,word_dict[key][0]就是发音...
db.commit() # 插入数据
except:
db.rollback() # 回滚
print('数据插入成功')
db.close() # 关闭数据库
print('数据库成功关闭')
7主函数:
for循环中if语句可以改的,13是考研必备词汇,可以换成其他id,但是六级id的好像不可以,我也不知道什么问题,希望有大神能指教一下
就看注释吧
def main():
db = conn()
create_table(db) # 创建一个表
base_url = 'http://word.iciba.com/' # 主页网址
base_html = get_html(base_url) # 得到首页的H5代码
class_id = get_url(base_html) # 得到所有class_id值
#print(class_id)
print('爬取主页')
for id in class_id: # word_all为class_id所有可能的取值
# print(id)
if id == '13': # 考研词汇class_id
class_url = 'http://word.iciba.com/?action=courses&classid=' + str(id) # 利用字符串拼接起来,得到URL网址
html = get_html(class_url)
class_info = BeautifulSoup(html, "html.parser") # 课程信息
# 获取课程中所有课时,其中li的长度就是课时的数量
course_li = class_info.find('ul', {'class': 'study-speed-m cl'}).find_all('li')
name_info = class_info.find('div', {'class': 'word_h2'}) # 得到显示单词类型的div内容
# print(name)
r = re.compile(".*?</div>(.*?)</div>") # 从div中匹配单词类型
name = re.findall(r, str(name_info)) # 得到单词类型:六级必备词汇, 并存入name列表
name = name[0] # 由于列表的值都相同,所以取第一个就好啦
print('开始爬取' + name)
# 课时的数量即li标签的数量,就是course的值,考研词汇为1到274
for course_id in range(1, len(course_li) + 1):
# 拼接单词的URL
course_url = 'http://word.iciba.com/?action=words&class=' + str(id) + '&course=' + str(course_id)
word_html = get_html(course_url)
print('开始爬取数据')
word_dict = get_info(word_html, name) # 得到数据字典
print('开始存储数据')
db = conn()
insert_words(word_dict, db) # 存储数据
#print(word_dict)
if __name__ == '__main__':
main()
欢迎指正!“能用代码解决的问题,怎么能直接用软件喃”,装b多好!over!