这是笔者爬取的第一个动态加载的网页,使用的IDE是Pycharm,选择的是百度文库的一篇16年六级卷子的文档。若直接使用requests模块去得到网页源码,会发现所得非所见,不能获取到文档中的内容。看了网上数篇博文的思路,最后还是尝试了使用selenium模块模拟安卓设备使用chrome浏览器访问,这样访问可以获得网页的完整源码。这篇文档默认加载了不到20%,点击“继续阅读”字样,之后内容加载到20%,这时若想要阅读更多内容需要点击的字样变成了“点击加载更多”,连续点击“点击加载更多”直到所有文档内容都已加载,此时再使用selenium的page_source方法获取完整的网页源码,得到源码后的操作就轻松了很多,使用BeautifulSoup模块从源码中获取需要的文档内容,之后用python-docx模块将获取的文档内容存到本地文档中。虽然代码不长,但还是踩到了不少坑,先放代码吧,然后再填坑。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import lxml
from bs4 import BeautifulSoup
import time
import docx
import re
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
#模拟移动设备使用chrome打开指定页面
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome(r"C:\Users\hhp\AppData\Local\Google\Chrome\Application\chromedriver.exe",chrome_options=options)
driver.get('https://wenku.baidu.com/view/83dd3c6f6bec0975f565e29f.html')
#模拟鼠标点击“继续阅读”
time.sleep(2)
pos = driver.find_element_by_xpath("//div[@class='foldpagewg-root']")
ActionChains(driver).move_to_element(pos).click(pos).perform()
#模拟鼠标点击“点击加载更多“
pos2 = driver.find_element_by_xpath("//div[@class='btns-warp']")
pos3 = driver.find_element_by_xpath("//div[@class='pagerwg-button']")
loop = 1
while loop <= 5:
time.sleep(1)
ActionChains(driver).move_to_element(pos2).perform()
ActionChains(driver).click(pos3).perform()
loop = loop + 1
#从得到的完整页面源码提取数据并存储
html = driver.page_source
bf = BeautifulSoup(html,'lxml')
get_docx_name = bf.find(class_='doc-title').get_text()
docx_name = re.sub('\s','',get_docx_name)+'.docx'
pages = bf.find_all(class_='content singlePage wk-container')
file = docx.Document()
with open('2016-6-I-six.txt', 'w',encoding = 'utf-8') as f:
for page in pages:
para = page.find_all(class_ = 'txt')
for p in para:
text = p.get_text()
f.write(text+'\n')
file.add_paragraph(text)
file.save(docx_name)使用到的模块
BeautifulSoup模块用来从html中提取数据,这里使用lxml HTML解析器,引入了lxml模块
time模块在代码中使用到延时函数,这里就是为了暂缓一下程序的执行,能更清楚的看到chrome浏览器被调用后整个操作流程,可有可无
re模块用到了sub函数处理字符串
docx模块踩到了连环坑,安装python-docx模块就好了
selenium模块用来操纵chrome浏览器,当然其功能不止于chrome
驱动问题
使用selenium操纵chrome浏览器先确定要有chromedriver驱动,没有的话会报错,可以从
http://npm.taobao.org/mirrors/chromedriver/下载驱动
下载时要注意自己浏览器的版本,驱动与浏览器版本对应关系可以在http://npm.taobao.org/mirrors/chromedriver/2.40/notes.txt中找到,截图如下。

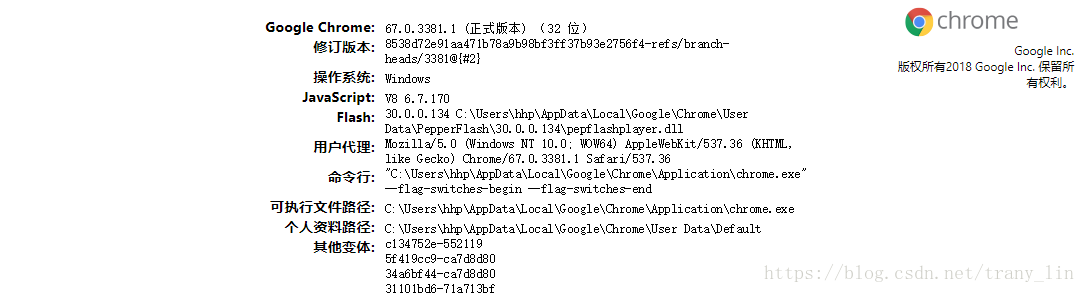
如果不清楚自己浏览器的版本,可以在chrome地址栏中输入 chrome://version
打开的界面如图,笔者的chrome是v67,没有更新到最新版,下载驱动要看好版本间对应关系
下载好的chromedriver.exe驱动要放置到自己安装的chrome浏览器的安装目录下,笔者驱动的路径是
C:\Users\hhp\AppData\Local\Google\Chrome\Application\chromedriver.exe
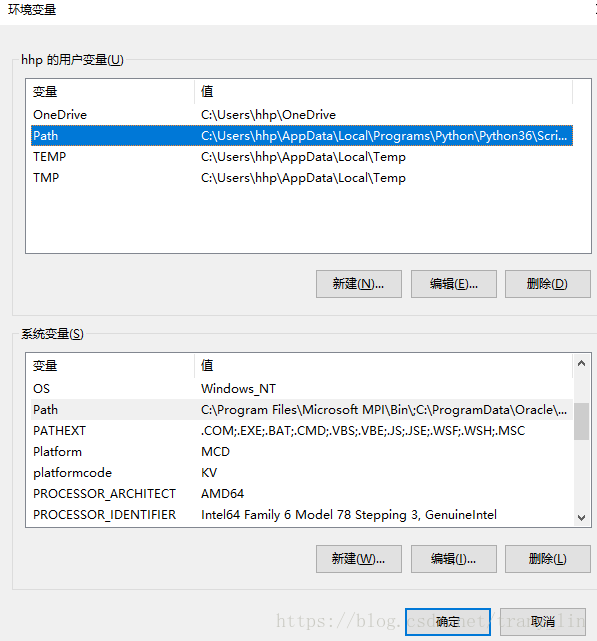
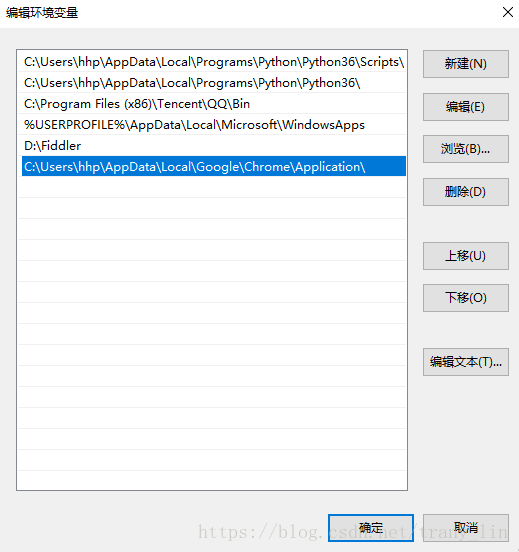
设置环境变量:
通过 我的电脑-属性-高级系统设置-高级-环境变量-Path 添加chromedriver.exe所在位置
具体代码
- 打开网页
options = webdriver.ChromeOptions()
设置启动chrome时的选项,这里的用途是设置user-agent选项模拟移动设备
driver = webdriver.Chrome(r"C:\Users\hhp\AppData\Local\Google\Chrome\Application\chromedriver.exe",chrome_options=options)
driver.get('https://wenku.baidu.com/view/83dd3c6f6bec0975f565e29f.html')这两句会打开chrome浏览器并打开指定的那篇文档的页面
笔者这里webdriver.chrome()的写法是没有配置chromedriver的环境变量,其中加的r是为了规避反斜杠的转义
如果配置过环境变量,可以写成
webdriver.Chrome(chrome_options=options)
如果你在设置环境变量时IDE是正在运行的,需要重启IDE后设置的环境变量才生效,否则直接运行程序会报错:
selenium.common.exceptions.WebDriverException: Message: 'ChromeDriver executable needs to be available in the path.
- 模拟鼠标获取完整网页
pos = driver.find_element_by_xpath("//div[@class='foldpagewg-root']")
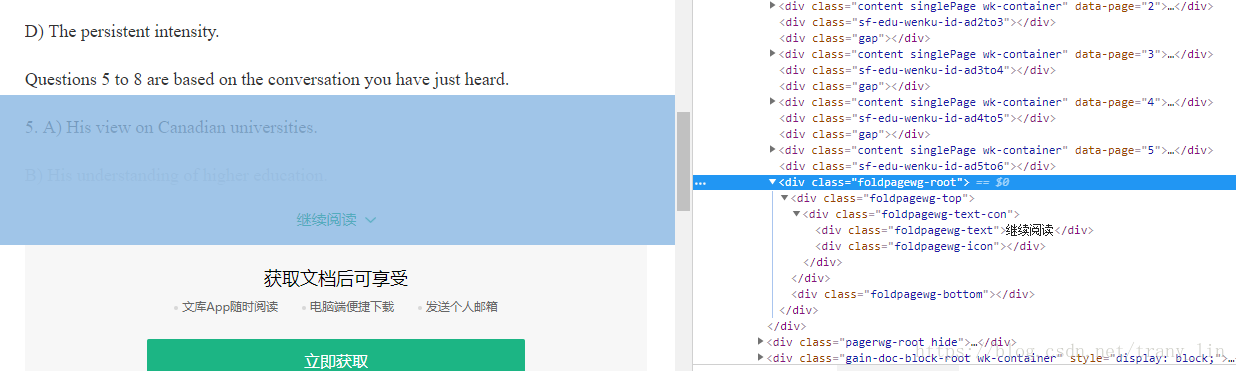
如上图,通过xpath的相对定位方式选择具有'foldpagewg-root'样式的div标签,在此div应用到的区域内,点击鼠标均可加载更多,如图左半部分阴影所示。关于xpath方法查找元素,笔者水平很有限,还不能作很好的总结,大家可以查阅网上的详细讲解。
这里只用到了相对定位,即'//'开头,与之对应便有绝对定位。可以看如下例子
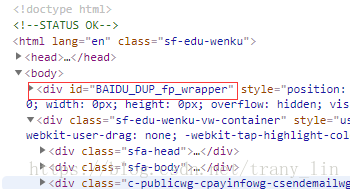
如果要定位到圈中的位置,绝对定位以'/'表示,且从根节点开始,写法是/html/body/div[@id='BAIDU_DUP_fp_wrapper']
相对定位更为简短 //div[@id='BAIDU_DUP_fp_wrapper']
ActionChains(driver).move_to_element(pos).click(pos).perform()是模拟鼠标操作,之后可以看到文档加载到20%
其中的move_to_element()将鼠标移动到之前定位的pos位置,click()函数模拟鼠标左键单击,perform()将操作执行
pos2 = driver.find_element_by_xpath("//div[@class='btns-warp']")
pos3 = driver.find_element_by_xpath("//div[@class='pagerwg-button']")
loop = 1
while loop <= 5:
time.sleep(1)
ActionChains(driver).move_to_element(pos2).perform()
ActionChains(driver).click(pos3).perform()
loop = loop + 1在内容加载到20%之后,想要加载更多需要点击“点击加载更多”,上面的pos2,pos3的定位就是为此
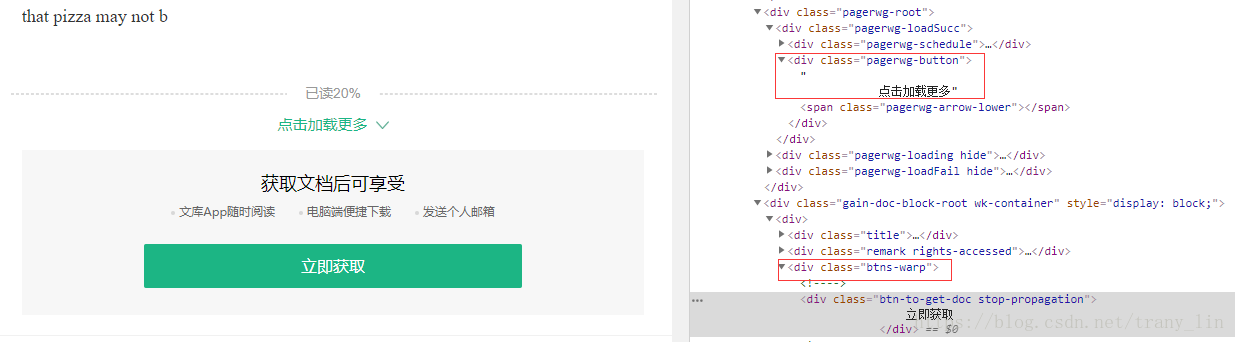
这里也遇到了小问题,一开始move_to_element()是直接移动到pagerw-button位置,之后的click()也是点击这里,但代码执行起来并没有加载更多,观察chrome的操作过程发现,这样的鼠标移动方式并没有将页面下拉到足以显示出“点击加载更多”字样,也就是说其被遮挡了,click()点击操作错误地指向网页的其他元素。move_to_element的效果类似于用鼠标滚轮下滑网页,把网页滑动到一个指定的位置便停止,修改代码为鼠标移动到div class='btns-warp'位置后,这时的网页中点击加载更多不再被遮挡,再用click()执行点击可以正常完成。这里循环五次是为了使网页内容全部加载完毕。
- 从获得的完整网页提取数据
html = driver.page_source
bf = BeautifulSoup(html,'lxml')经过上述模拟鼠标点击操作获得完整网页源码后,剩下的操作就更为简单,page_source获得网页源码,然后使用BeautifulSoup模块从html源码中提取数据。
get_docx_name = bf.find(class_='doc-title').get_text()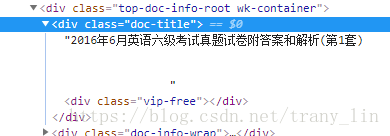
这句是为了获得文档名,使用BeautifulSoup的find方法找到包含文档名的div标签
docx_name = re.sub('\s','',get_docx_name)+'.docx'sub()将get_docx_name字符串中的所有不可显字符替换为 '',效果就是去除了这些不可显字符,如空格,换行符
pages = bf.find_all(class_='content singlePage wk-container')这句从网页代码中选取包含文档每一页的部分

file = docx.Document()
with open('2016-6-I-six.txt', 'w',encoding = 'utf-8') as f:
for page in pages:
para = page.find_all(class_ = 'txt')
for p in para:
text = p.get_text()
f.write(text+'\n')
file.add_paragraph(text)
file.save(docx_name)最后这部分代码提取文本的文字内容,存储到本地,这里同时存储为了docx和txt文件,这里用到的文件操作较为简单,很容易上手。
f.write(text+'\n')中的+'\n'是为了换行,否则存为的txt文件很乱。而docx模块还有很多很多功能,这里也只是用到了最为基础的插入文本。
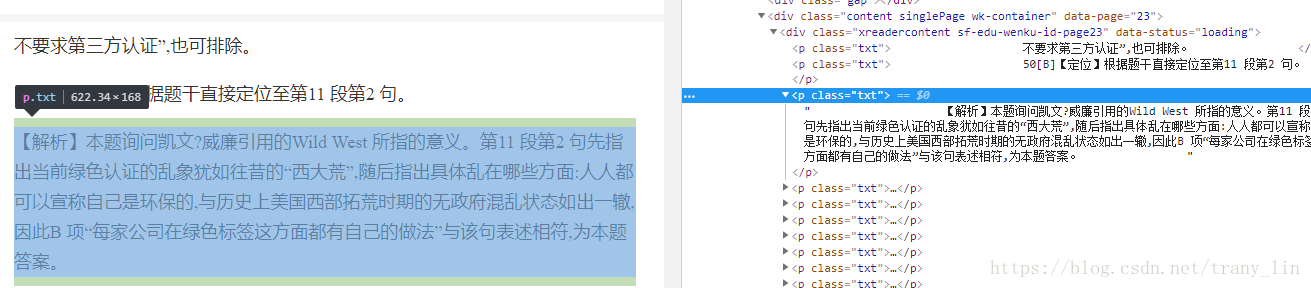
page.find_all(class_='txt')是获取到每页中的所有段落,下图有对应关系,函数返回值类型是列表
所以有了之后的for p in pages循环,p.get_text()提取到真正的文本
file.save()保存文件,路径可以自己指定,这里只写了一个docx_name,会保存到默认路径,即和这份代码同一路径,例如笔者这份代码test.py路径为G:\Pycharm\test.py 文件默认会保存到G:\Pycharm,也可以自己指定,比如file.save('C:test_docx.docx')
程序执行后得:
总结
这是我的第一篇博客,第一篇的内容选择了python爬虫,自己水平很有限,写起来还是挺有压力的。这里爬取的方法也只是设法获得包含有文档文本内容的html源代码,从中提取出文档内容后自己再生成文件,不过如果充分利用docx模块可以对得到的数据进行自由排布。网上很多爬虫文章的代码都失效了,这篇文章权当提供一份可以实际操作的代码去尝试。当然随着时间流逝,这份代码也会失效,如果以后有了好的思路,笔者会对这篇文章做些增删查改,或者推倒重来。最后添上一些文档或者博客的链接。
参考的文章: