百度文库爬取
前言
相信很多小伙伴在网上摘抄论文的时候都曾经受过百度文库无法复制的苦吧,那么我们是真的没办法把这些文字复制下来了吗?
答案是否定的,博主的观点是,竟然是出现在我们浏览器上面的内容了,当然就可以拿下来啦,下面以爬取全国大学生同上一堂思政课观后感为例。
网页分析
我们对下面的网页进行分析:
同上一堂思政课观后感
首先查看网页源代码,我们发现并没有论文上的文字内容,那么说明这些文字并不在源html文件上,那么很有可能是浏览器加载js文件渲染出来的,我们打开开发者模式,选择network,同时只保留js
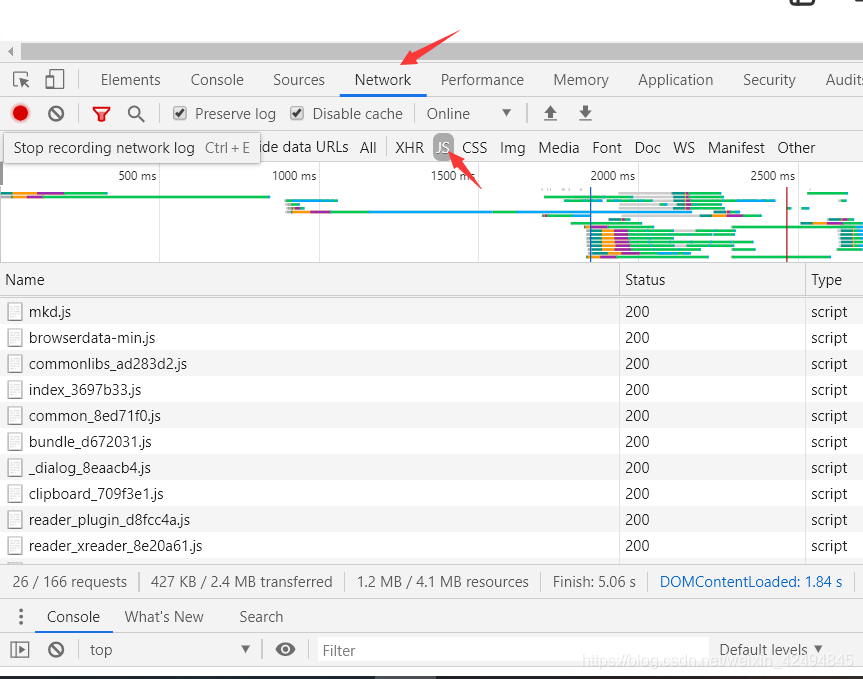
往下找,我们果然发现了包含有文字的js文件
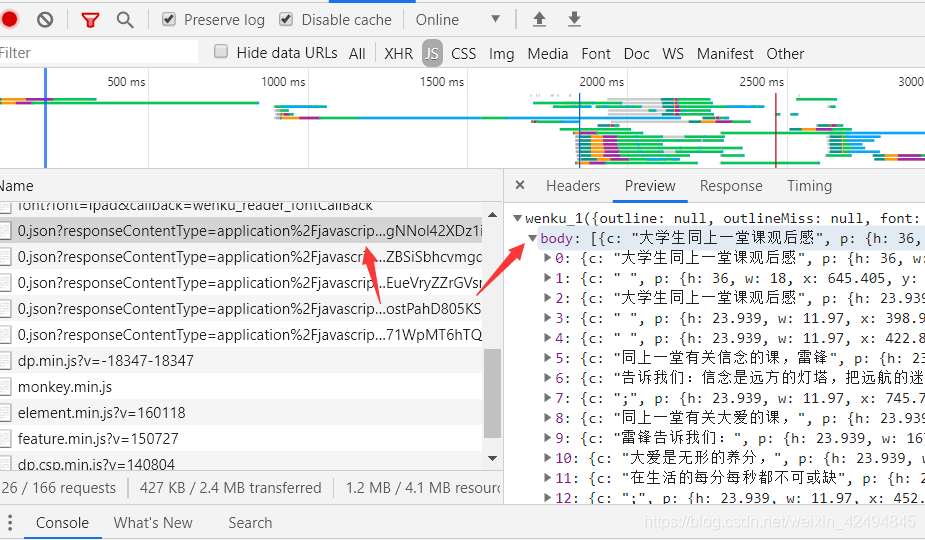
打开该js文件的url,我们却并没有看到这些文字

这是怎么回事呀?不要惊慌,这些文字其实是在这里的,只不过我们不认识,这是由于编码的问题,这也是下面我们写程序时需要注意的一个点,下图框起来的地方其实就是我们需要拿下的文字了。
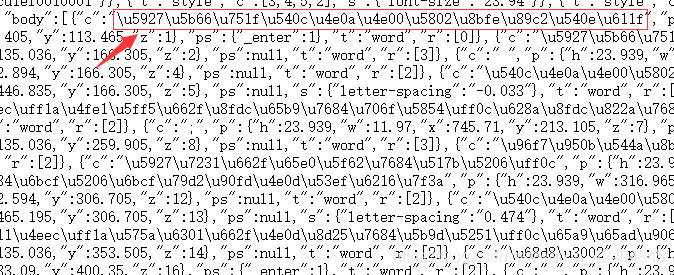
网页分析完成了,准备工作都做好了,下面我们开始写程序吧!
软件要求
- python3
- 第三方库requests
- python内置的re模块
requests介绍
requests是使用Apache2 licensed 许可证的HTTP库,是用python编写的,它比urllib2模块更简洁。
Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码。
在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作。
requests会自动实现持久连接keep-alive。
感兴趣的朋友可以去requests官方文档浏览相应内容。
程序编写
首先我们需要导入我们需要的模块:
re模块是python内置的,requests模块需要安装,考虑到一些朋友没有安装requests,下面简单地介绍下安装。
安装过程非常简单,只需要在shell下输入:
注:-i参数是更换安装源,这里我们更换成豆瓣的源,安装更快。
pip install requests -i "https://pypi.doubanio.com/simple/"
下面正式进入程序的编写:
首先我们需要导入我们所需要的模块:
# 导入requests和re模块
import requests
import re
定义请求url和请求头,这里的url为我们找到的js文件的url。
url = "https://wkbjcloudbos.bdimg.com/v1/docconvert9065/wk/a3c4685a32e9f1bb2f27fcd900944bcb/0.json?responseContentType=application%2Fjavascript&responseCacheControl=max-age%3D3888000&responseExpires=Sat%2C%2009%20May%202020%2020%3A32%3A45%20%2B0800&authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2020-03-25T12%3A32%3A45Z%2F3600%2Fhost%2F751fc100a09cf16a189717caad7780f4ce8b3621ab69c2ec475565ecfa478dcc&x-bce-range=0-8759&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU4NTE0MzE2NSwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDb250ZW50VHlwZSIsInJlc3BvbnNlQ2FjaGVDb250cm9sIiwicmVzcG9uc2VFeHBpcmVzIiwieC1iY2UtcmFuZ2UiXX0%3D.mpGXXDwegNNol42XDz1iaEv6YUxgKggkR6ycrt8con8%3D.1585143165"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/76.0.3809.100 Safari/537.36"
}
对服务器进行请求:
content = requests.get(url=url,headers=headers)
这里我们需要设置requests的编码格式,上文也提到了js里面的内容由于编码的问题,我们拿到的并不是文字,那么如何转换成汉字呢?其实很简单,我们可以直接设置requests的编码方式
content.encoding = "unicode_escape"
然后使用正则表达式提取我们需要的内容
content_list = re.findall('"c":"(.*?)","p"',content.text)
然后就可以利用一个循环打印出这些文字啦
for sentence in content_list:
print(sentence,end="")
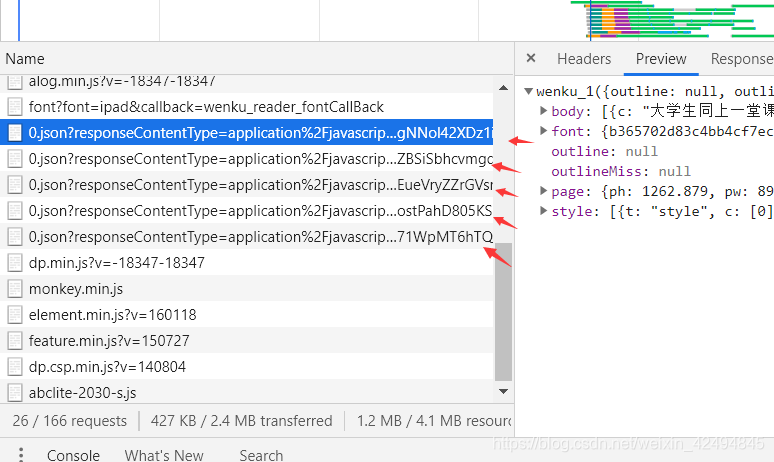
运行程序,我们可以看到汉字已经被我们拿下来了

这里看到我们其实只拿到了一部分内容,那是因为一个js文件中的内容就这么多,我们需要把浏览器收到的js文件全部拿下来才能得到完整内容。
完整程序如下:
#导入模块requests,re
import requests
import re
#定义请求url
url = "https://wkbjcloudbos.bdimg.com/v1/docconvert9065/wk/a3c4685a32e9f1bb2f27fcd900944bcb/0.json?responseContentType=application%2Fjavascript&responseCacheControl=max-age%3D3888000&responseExpires=Sat%2C%2009%20May%202020%2020%3A32%3A45%20%2B0800&authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2020-03-25T12%3A32%3A45Z%2F3600%2Fhost%2F751fc100a09cf16a189717caad7780f4ce8b3621ab69c2ec475565ecfa478dcc&x-bce-range=0-8759&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU4NTE0MzE2NSwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDb250ZW50VHlwZSIsInJlc3BvbnNlQ2FjaGVDb250cm9sIiwicmVzcG9uc2VFeHBpcmVzIiwieC1iY2UtcmFuZ2UiXX0%3D.mpGXXDwegNNol42XDz1iaEv6YUxgKggkR6ycrt8con8%3D.1585143165"
#定义请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/76.0.3809.100 Safari/537.36"
}
#请求内容
content = requests.get(url=url,headers=headers)
#设置编码方式
content.encoding = "unicode_escape"
#正则提取所需要的内容
content_list = re.findall('"c":"(.*?)","p"',content.text)
#循环打印
for sentence in content_list:
print(sentence,end="")
以上就是博主今天和大家分享的内容了,希望能给大家带来一定的收获。
ps:现在是全国防疫特殊时期,希望大家健健康康的,注意自己的身体,祝大家学习进步,蒸蒸日上。