有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本。
工具:python3.7+selenium+任意一款编辑器
前期准备:可以正常使用的浏览器,这里推荐chrome,一个与浏览器同版本的驱动,这里提供一个下载驱动的链接https://chromedriver.storage.googleapis.com/77.0.3865.40/chromedriver_win32.zip
首先我们来看一下百度文库中这一篇文章https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html
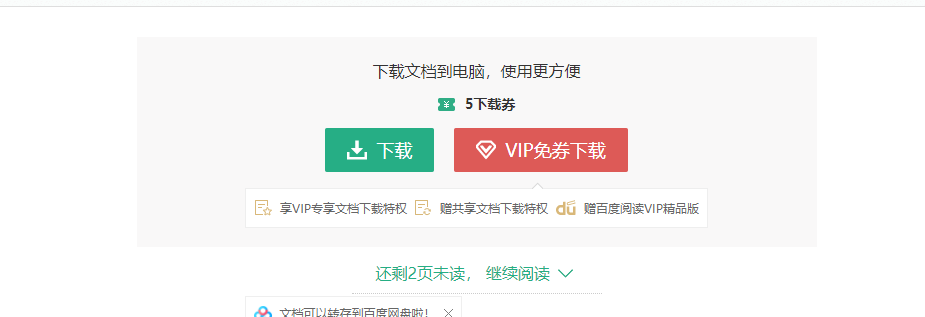
可以看到,在文章的最末尾需要我们来点击继续阅读才能爬取到所有的文字,不然我们只能获取到一部分的文字。这给我们的爬虫带来了一些困扰。因此,我们需要借助selenium这一个自动化工具来帮助我们的程序完成这一操作。
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup import re driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
我们先通过驱动器来请求这个页面,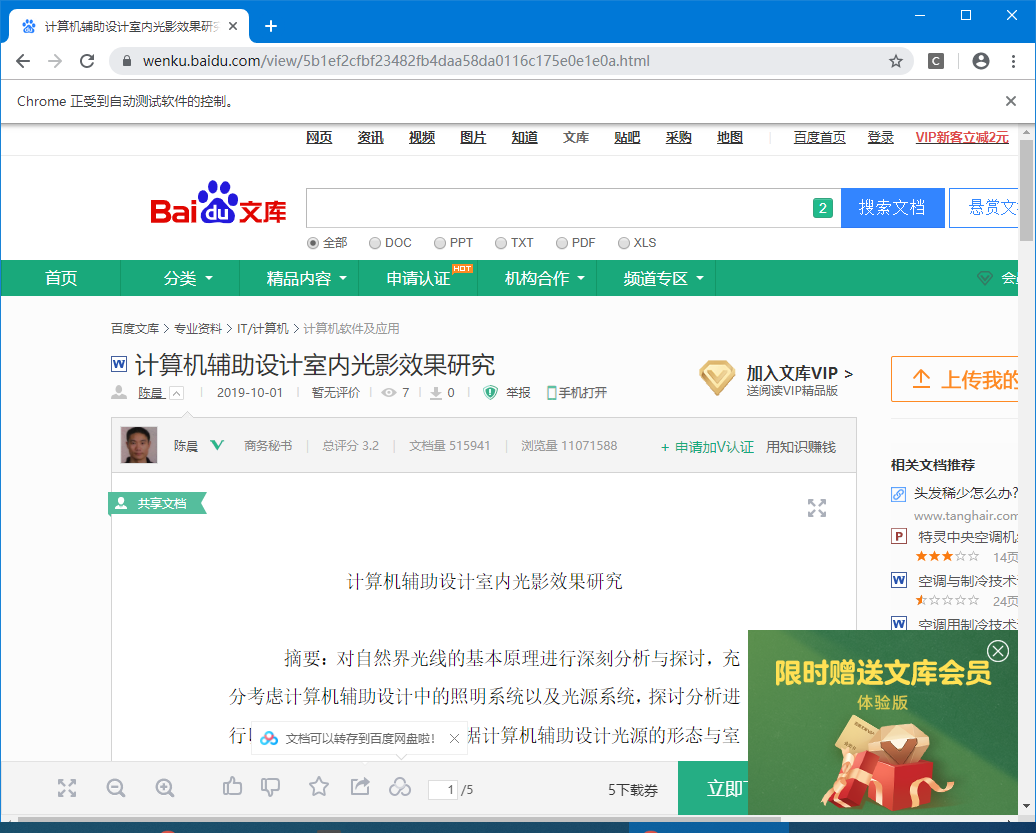
可以看到,已经请求成功这个页面了。接下来需要我们通过驱动来点击继续阅读来加载到这篇文章的所有文字。我们通过f12审查元素,看看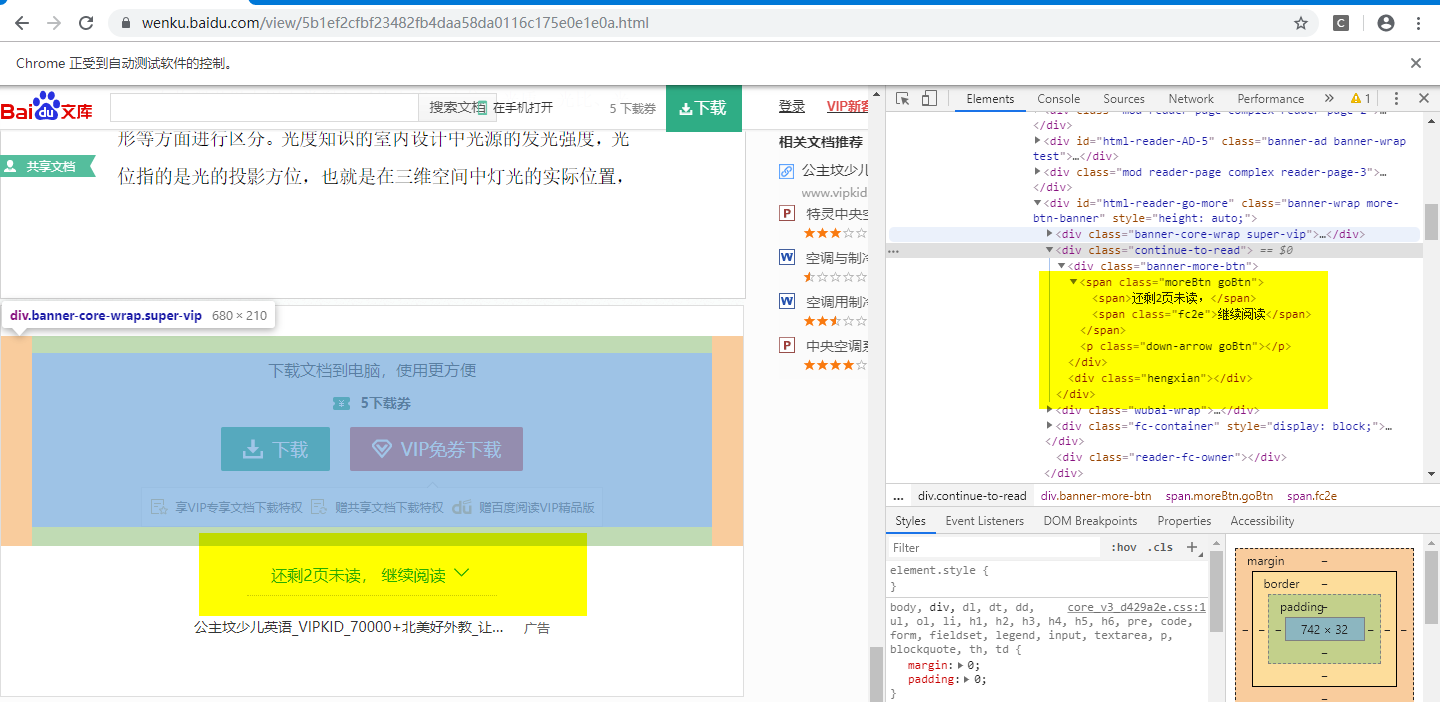
然后通过selenium的定位功能,定位到左边黄色区域所在的位置,调用驱动器进行点击
driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html") driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后执行看看
 黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup import re driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html") page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p") driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去 page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
先获取到继续阅读所在页面的位置,然后使用
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去方法将页面滚动到可以点击的位置
这样就获取到了整个完整页面,在使用beautifulsoup进行解析
html=driver.page_source bf1 = BeautifulSoup(html, 'lxml') result=bf1.find_all(class_='page-count') num=BeautifulSoup(str(result),'lxml').span.string count=eval(repr(num).replace('/', '')) page_count=int(count) for i in range(1,page_count+1): result=bf1.find_all(id="pageNo-%d"%(i)) for each_result in result: bf2 = BeautifulSoup(str(each_result), 'lxml') texts = bf2.find_all('p') for each_text in texts: main_body = BeautifulSoup(str(each_text), 'lxml') s=main_body.get_text()
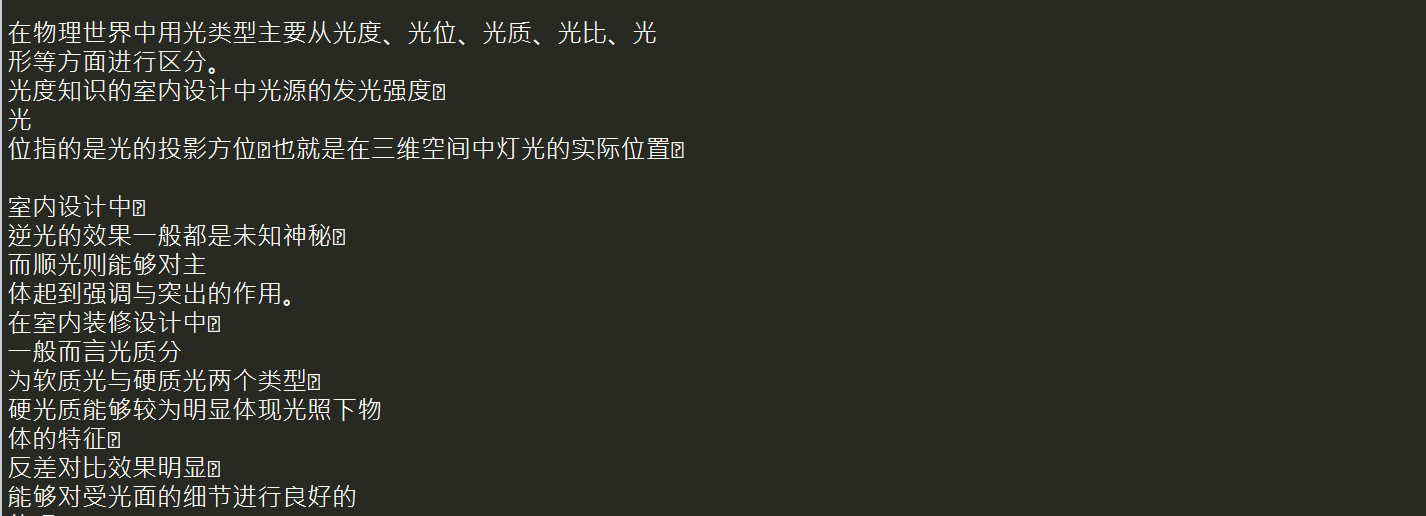
最后在写入txt文档
f=open("baiduwenku.txt","a",encoding="utf-8") f.write(s) f.flush() f.close()