本次继续给大家带来的是表情识别这个问题。我们将从四个方向给大家进行分享。
首先,我们会给大家科学地定义一下表情是什么?表情实际上包含了我们平常所说的表情以及微表情。
其次,我们会简单地介绍一下传统方法的研究思路。传统的方法主要从静态图和动态视频两个方面进行讲述。
然后,我们再给大家介绍一下深度学习的方法。
最后,我们对表情分类这个问题的应用和它的难点做一个完整的介绍。
下面开始我们第一部分的分享:什么是表情?
所谓表情其实指的是面部的肌肉的运动。我们平常所说的表情包含七种基本的表情,主要是包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶以及蔑视等。
上面这张图是一个表情常用的数据集,这个数据集包含了八种表情,实际上就是对应我们左边所说的七种表情以及中性,也就是无表情。当然这个图的顺序跟我们前面的文字没有一一对应。总之这七种表情就是我们平常最常见的表情。

但是表情实际上并不仅仅如此。科学上还有一种表情叫做微表情。微表情的研究常常被心理学家和犯罪科学家用于相关的研究。
那什么是微表情呢?所谓微表情,其实就是持续时间非常短,它只是某种无意识地使人类在隐藏某种情感。无意识的一个行动,它的持续时间通常不到一秒钟。
举个例子,当我们有的时候表现出微笑,但其实我们表示的是蔑视这样的一种感情。大家平时应该有这样的感受。所以表情其实分为基本表情和微表情这两大类。当然还有更多更丰富的表情,是我们所研究的问题的复杂性来定,我们可以去进行更多的分类。
那表情它是怎么形成的呢?前面我们说了表情实际上是面部的肌肉运动,而面部的肌肉运动虽然是一个整体,但是这个肌肉运动实际上也可以分离开几个区域,主要包含这么一些区域:
a)眉毛。眉毛主要包含皱眉、抬眉等等。它分别可以表示一些惊讶以及一些蔑视的表情。
b)眼睑。眼睑包含抬眼睑以及闭眼睑这样一个动作。它实际上包含的可能是惊讶、无聊这样的一些表情。
c)眼睛。眼睛可以包含愤怒、蔑视等等。
d)嘴唇。嘴唇的表情非常的丰富,它可以包含微笑、嘟嘴、惊讶等等。
e)鼻子。鼻子它相对来说要简单一些。比如我们常说的耸鼻等等,它可以表示一种蔑视的表情。
f)下巴。下巴也可以表示一些嘟嘴之类的表情,甚至一些惊讶之类的表情。
总的来说,人脸的面部包含了上面列举的这几大区域,由这几大区域各自就组成了表情基,也就是action uints。一般我们在研究的时候,表情基会有20个左右。这里我们展示了28个技术的表情基,由这些基本的表情基就可以组成人脸的丰富的表情。
表情的研究方法也是分两类:传统的方法和深度学习方法。
传统的方法主要是两个方面来进行研究:
一方面是静态的图。所谓静态图就是一张人脸的图片。通常我们会使用一张对齐好的人脸图片。那么对于静态图,我们来研究的表情通常就采用一些传统的人脸的特征,包含一些纹理啊等等一些特征。
另一方面是动态图。所谓动态图就是一个视频,因为人脸的表情他天生是一个运动的动作,也就是肌肉的运动,所以用动态的图或者视频来表征是一个更好的方案。
那么动态图主要有两种研究思路:
一种是光流法。光流法本身就是用于运动的跟踪的,所以我们可以用光流+梯度场来跟踪我们的表情的运动区域。前面我们可以分为了一句表情基,可以对人脸的区域进行几个区域的划分,我们可以用光流+梯度场来进行跟踪。当我们跟踪到这个区域之后,我们就可以用这些区域运动的方向的变化来表示人脸肌肉的运动,表征到人脸肌肉的运动之后,我们就可以得到相应的人脸的表情。
第二个是用ASM等模型。ASM等模型也就是主动形状模型。它本身就是提取的面部的关键点,而我们人脸的表情实际上可以用面部关键点来进行表征。因为面部关键点它有序号的信息,所以我们基于面部关键点,还可以分区域的对人类的表情进行表征,基于动态图的思路会取得更好的研究效果。
这就是传统的方法。
如今,在深度学习已经遍地开花的时代,我们更多的是采用深度学习的方法来研究人类表情这样的问题。
深度学习的方法,它主要包含两个问题:
一个是分类的问题。前面我们说了,人脸的表情包含了非常多的表情基,所以对于每一个区域的表情基,我们可以进行分别的分类。那么人脸的表情,对于输入这样一张图,这就是一个多标签分类的问题。所谓多标签分类,我们在前面也给大家介绍过,就是说一张图它不仅仅对应一个唯一的标签,它可能包含了多个维度,我们要判断每一个维度上是否存在它的信息。
上图是一个常见的pipeline框架。我们可以看到它将人脸的图分成了8×8这样的一个区域,将每一个图像块都经过一个单独的卷积,一个单独的卷积通道,然后获取到它的一个特征图的表示。然后我们可以把特征图的特征向量进行串接起来,然后再进行分类。这就是一个典型的多分类的问题。
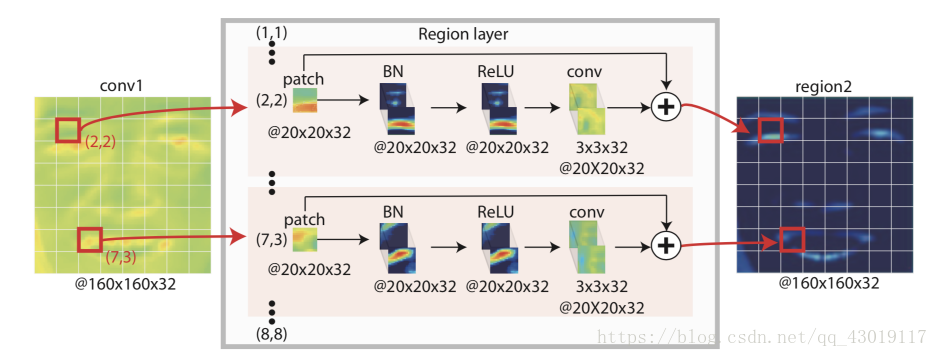
分类问题我们可以得到一个表情基是否存在。但是当我们在应用表情的时候,我们知道一个表情的存在还不能完美的解决我们的问题,有时候我们希望知道这个表情的幅度是多大,所以又带来另一个问题,即回归的问题。
回归的问题估计的就是表情的幅度。
比如上面这张图,从左到右它是一个微笑的过程,但是微笑的幅度是不一样的。最右边微笑的幅度最大,最左边基本上已经看不到微笑,或者说他不是微笑。有的时候很多的时候我们需要对表情做迁移,或者对表情进行编辑,那么我们需要估计表情的幅度,估计表情的幅度相对于表情分类来说,它更加困难。因为人脸面部的表情基之间并非是完全独立的,比如嘴巴的运动会牵动下巴的运动,鼻子的运动也会牵动嘴巴的运动,所以我们无法单独地对表情基进行估计。

通常意义上常用的研究方法是对各个表情基之间建立了一个图,然后我们会去优化这样的一个图,利用CRF等方法来进行优化。更多的具体细节,大家可以线下去关注。
表情幅度的估计问题的常用方法就是前面所说的这样的几种思路。
最后我们来看看表情的应用,表情可以应用在哪些地方?
首先,游戏。我们可以用表情在玩很多的游戏,比如主播之间利用表情来作PK,然后来玩类似于消消乐这样的一些游戏。
其次,人机交互。可以利用表情来做很多的人机的控制交互。
最后,表情迁移。如下图:
这张图就是一个avatar,我们利用人脸来实时的做一些表情,从而将这些表情驱动到我们这样的一个3D的模型上面来做一些展示,这样的一个应用在电影里面,在CG制作里面是非常非常有商业前景的。

不过表情估计它也有很多的难点:
第一个难点是表情非常的复杂多变。前面我们说了人脸的表情有七个基本表情,但实际上表情还包含非常非常多,甚至表情都不一定是面部带来的,它甚至还有其他的图像,非面部区域以外也能带来一些表情。它的变化非常复杂,再加上人脸又是一个柔性的模型。
第二个难点是表情幅度的量化问题。像我们上面展示的这样一张图,我们要用人脸来驱动这样的一个avatar、这样的一个3D模型来做一些表情的动作,那么我们不可避免的要估计人脸,也就是真人他的表现的幅度是多大,而对他的幅度进行量化,就面临了几个挑战:
1)我们要对我们的幅度进行标注,这是一个非常大的问题。因为我们需要用系数来量化我们的幅度,它并不是那么直观。
2)我们要利用方法,前面我们所说的利用深度学习的方法来估计我们这样的表情的幅度,它也面临着很多的困难。
好了,以上就是我们人脸表情相关的分享。
感谢您的阅读,更多精彩尽在蜂口小程序~了解一下?
获取免费内容,欢迎V信fengkou-IT勾搭~