我们接着上一节的分享,继续分享人脸检测的下半部分。这次的分享主要是深度学习相关的。我们会主要讲述当前深度学习在人脸检测这个领域的发展水平。主要从以下几个方向进行分享:
首先,我们会讲讲当前主流的基于深度学习的一个人脸检测的框架,包括两个框架,一个是级联CNN框架,一个是RCNN框架。
然后,我们会对深度学习的方法做一个简单的总结。
最后我们对整个的人脸检测这一领域做一个展望。对人脸检测现在面临的挑战以及未来的研究方向做一个全局的把握。
下面开始我们第一部分的分享,
1)级连CNN框架。
级连CNN框架是第一个用深度学习来进行人脸检测的一个框架。
我们首先看上面的一个流程图,可以看到,首先我们有一张测试图片,然后经过了一个12-net的这样的一个网络,这是一个人脸检测的网络,然后又经过了一个12-calibration-net的这样一个网络。他是一个对边框进行精细调整的一个网络。随后我们又经过了24-net 24-calibration-net,48-net 48-calibration-net,直到最后得到我们最终的检测结果。
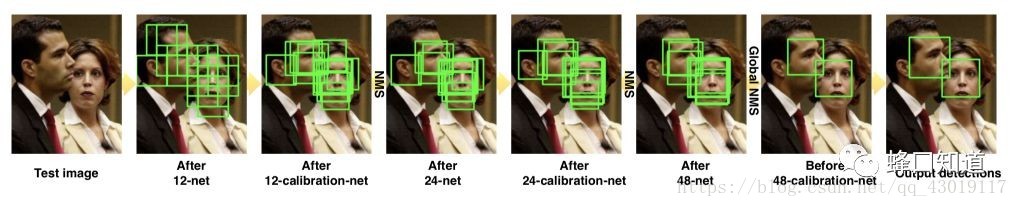
从以上的图我们可以看出来,它有几个特点:
a.这是一个级连CNN网络结构。它与我们在上一次分享的VJ算法有类似的思想,也就是通过多个网络的一个串接,从粗到精,最后得到我们最终的检测结果。
b.这是一个多尺度的网络结构。我们看到上面有12-net,24-net,48-net网络,实际上它在训练的时候,他们是采用了不同分辨率的图片进行训练的,这是一个多尺度的网络结构。
c.添加了一个边界改进网络,也就是我们上面的三个calibration-net。这三个calibration-net,是与他们初级的人脸检测网络对应的的人脸检测,比如说12-calibration-net,它就是针对12-net这个人脸检测网络,用于改进它的边界的位置,这是深度学习的方法与传统方法的一个比较大的区别,因为深度学习的方法可以非常方便地去改善它的边缘,这也是深度学习方法的精度高于传统方法的一个比较重要的原因。
如果大家对这个文章更多的细节感兴趣,可以去看一下这篇论文:
Li H, Lin Z, Shen X, et al. A convolutional neural network cascade for face detection[C]// Computer Vision and Pattern Recognition. IEEE, 2015:5325-5334.
接下来我们对下面的三个网络的流程图给大家做一个简单的分析。
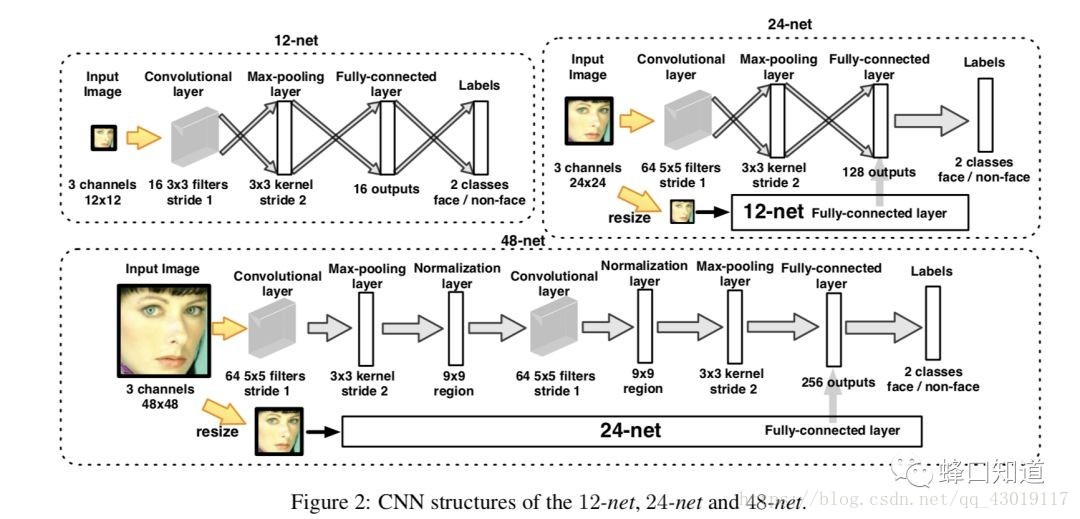
首先,我们看12-net。12-net我们可以看到它的输入是一张12×12×3这样的一个彩色图。这就是被称为12-net原因,它的分辨率是12×12。同样24-net ,48-net,它们的输入分辨率分别是24×48。
这三个网络分别起到什么样的作用呢?
因为我们前面可以看到整个网络的框架的流程是12-net,然后串接24-net,最后串接48-net这样的一个流程。他们这么设计的原因主要是首先我们利用前端也就是12-net这样的一个网络,它可以过滤掉大部分非人脸的区域,同时它也能够保证一个较高的召回率,但是它的精度会稍微的低一些,相应地,它的计算量也会小一些。随着24-net,48-net这样的一个分辨率的提升,它的分类器会更加的复杂,它的检测也会更加的精细。
总结一下,级联CNN它通过一个分类网络加定位网络串接以及多分辨率多尺度的这样一个设计思想,它真正的将CNN用于人脸检测,并取得了比较大的突破。当然,级连CNN是比较早期的一个框架了,它有它的一个弱点,就是他们采用的六个网络都需要分别单独进行训练,这实际上在使用过程中是非常麻烦的。
2)RCNN系列的发展。
到现在主流的人脸检测,鲁棒性最好的一个系列就是RCNN系列。实际上RCNN自身的发展就是一个人脸检测的方法,从非end to end的方法到end to end的方法这样的一个发展历史。
所谓end to end就是一个网络输入一张图片直接得到了我们最终的结果,而非end to end可能要包含了好几步,这几步在训练的过程中都是需要分别进行训练的。
最开始出现的是RCNN这样的一个网络。RCNN它实际上与传统的方法有很大的类似之处。比较不同的地方是RCNN采用的selective图像块,采用了selective的方法来提取了很多候选的图像块,然后利用CNN来进行图像特征的提取。这两块与传统方法不同,剩下的它仍然是通过一个SVM分类器来对候选的人脸区域进行分类,判断他是不是有人脸。RCNN这样的一个框架,它的计算量非常大,因为selective提取图像块是一个计算量很大的过程,同时对提取这么多的候选区域要分别用CNN的进行特征提取,又是一个非常大的计算量,所以限制了这个方法的实际的使用。
随后提出了Fast R-CNN这样的一个升级版本。Fast R-CNN相对RCNN的改进之处在于CNN提取图像块特征,他提出了一个RoIPooling的框架,RoIPooling这样的一个方法可以从整图对应的一个卷积特征图反投影回原图。也就是说我们只要得到了卷积特征图,我们就可以反投影回到原图中,获得任意区域的特征。所以它实现的只需要网络前向传播一次,就能够获得任意图像区域的一个特征。
这一点有点类似于传统方法中,前面我们所说的VJ方法中的积分图,积分图也是一样的,它只需要一次积分图的计算,就可以得到任意的候选区域的特征,它这样的思想,就可以大大地减少RCNN里面的CNN对大量重复图像区域和大量重叠图像区域进行特征提取的计算量。但是由于Fast R-CNN仍然免不了selective图像块的候选区域的选择,这个方法是非常耗时的,所以最终又出现了Faster R-CNN。
Faster R-CNN的贡献就是提出了Region Proposal框架。Region Proposal利用了很多的anchors,把一张图片划分成了n*n这样的区域,然后基于每个区域提出了ratio和scale不同的proposal。他的提出就已经完全地取消了selective方法,实现了用CNN来提取候选区域,由此大大地降低了计算量,达到Faster R-CNN这样的一个框架之后,它的实时性就得到了保证。真正的将这样一个系列方法用于人脸检测就有了可行性。
最后我们对深度学习的方法做一个简单的总结。
深度学习的方法实际上可以分为这么几大类:One-stage、Two-stage、Multi-stage。
One-stage这样的方法,包括YOLO系列、SSD系列等等。它的特点就是:
a)没有Region Proposal的过程,它直接回归出了一个图像目标的位置。它的特点就是它的检测精度相对来说会比较低。
b)它的检测速度是最快的。目前像YOLO系列、SSD系列都是非常具有竞争性的,它也在很多的工业应用中进行了落地。
不过综合效果最好的还是Faster R-CNN系列。也就是我们前面介绍的系列,它的特点就是它的检测精度是这几个方法里面是最高的,但是它的检测速度会稍微的慢一些。
最后是Multi-stage,就是最开始我们的R-CNN框架,包括SPPNet,它们基本上已经被淘汰了,因为它们包含了像利用传统的方法来提取候选区域这样一些非常耗时的操作。他们的检测精度也是这几个方法里面最低的,检测速度也是极慢的。
那深度学习与传统方法相比有什么特征呢?
1)深度学习的方法比传统方法总体来说是要慢一些。不过人脸检测的问题,它的速度实际上取决于我们输入网络进行检测的图像的大小,以及与我们最小检测的人脸尺寸有关系。当我们要求最小检测的人脸的尺度越小,那我们一般要求输入的图像就会越大,这样一来它的计算量就会越大。因为现在的网络都是基于全卷积的网络,然后深度学习的方法它的召回率是远高于传统方法的。
2)因为深度学习方法一般都会有专门一个定位的过程,所以它的定位精度也是远远高于传统方法,这是深度学习方法的一个比较大的优势。
接下来我们对人脸检测所面临的一些挑战,给大家做一个总结:
首先,是多尺度问题。

我们看这样一张图,这张图包含了各种各样的人脸,从离摄像头比较近的大的人脸到离摄像头非常远的人脸。我们如果想检测这样的一张图的话,它就面临多尺度的问题。
多尺度需要我们设计一个比较精巧的anchors机制。一般解决多尺度的问题是有两个思路:
a.)采用大尺度的输入。
当我们使用越大尺寸的一个图片,那么我们最后对应回小脸的那个feature map的区域也会越大,这样就能够保证召回。
b.)使用多尺度特征的融合。
这是两篇参考文献,大家有兴趣可以去参考:
Li H, Lin Z, Shen X, et al. A convolutional neural network cascade for face detection[C]// Computer Vision and Pattern Recognition. IEEE, 2015:5325-5334.
Hu P, Ramanan D. Finding Tiny Faces[J]. 2016.
其次,遮挡问题。
这种问题在现实生活中是广泛存在的,因为我们的人脸检测算法,很多时候我们应用这个算法的时候,它是一个被动式的,也就是人不会主动去配合一个摄像头来进行人脸的检测与识别。这个时候我们算法又要能够识别到这些遮挡,又要识别到一个遮挡的人脸。
他现在也包含了两个主要的思想:一个是我们对遮挡空间进行补全,另外一个是采用了Attention的机制。
同样我们提供两篇主流参考论文,大家可以去参考:
Ge S, Li J, Ye Q, et al. Detecting masked faces in the wild with lle-cnns[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017: 2682-2690.
Wang J, Yuan Y, Yu G. Face Attention Network: An effective Face Detector for the Occluded Faces[J]. arXiv preprint arXiv:1711.07246, 2017.
最后是大姿态问题。
大姿态是困扰人脸检测识别一个比较大的方向,因为我们的人脸在日常生活中,我们会有各种各样的角度,各种各样的侧脸,低头,抬头等等。由于大姿态会导致人脸的一些特征的缺失,所以我们对大姿态人脸检测也面临了很多困难。
现在对大姿态人脸的检测有一个主流的,或者非常有前景的方向,是利用三维人脸检测方法。
我们利用这样的一个三维人脸的重建,重建回一个图像的三维的模型,然后我们对三维的模型进行旋转矫正,从而实现我们的人脸检测问题。
好了,我们人脸检测的分享就到此为止,我们利用了两节的内容,来给大家对人脸检测的传统方法和深度学习的方法做了一个全面的总结。人脸检测现在仍然面临很多的问题,仍然在现实场景中有很多的可以改进的地方。
免费领取 技术大咖分享课,加蜂口V信: fengkou-IT
蜂口小程序将持续为你带来最新技术的落地方法,欢迎随时关注了解~