Clustering
K-Mean Algorithm
下图中已经有没有标签的点,现在需要分为两类
进行k-Mean算法
1、随机选取两个聚类中心,需要分为几类就选取几个聚类中心
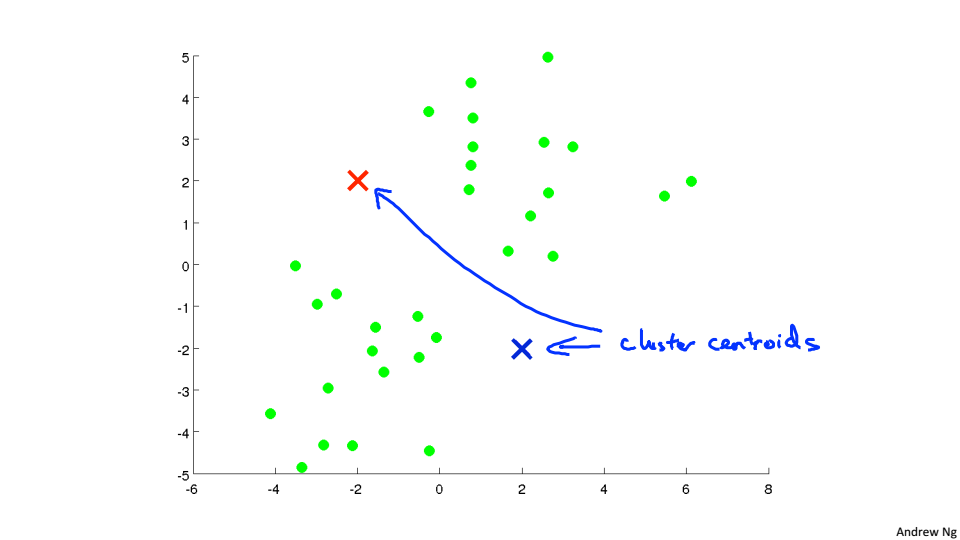
2、遍历所有的点,根据点到聚类中心的距离来判断将该点分到哪个聚类中
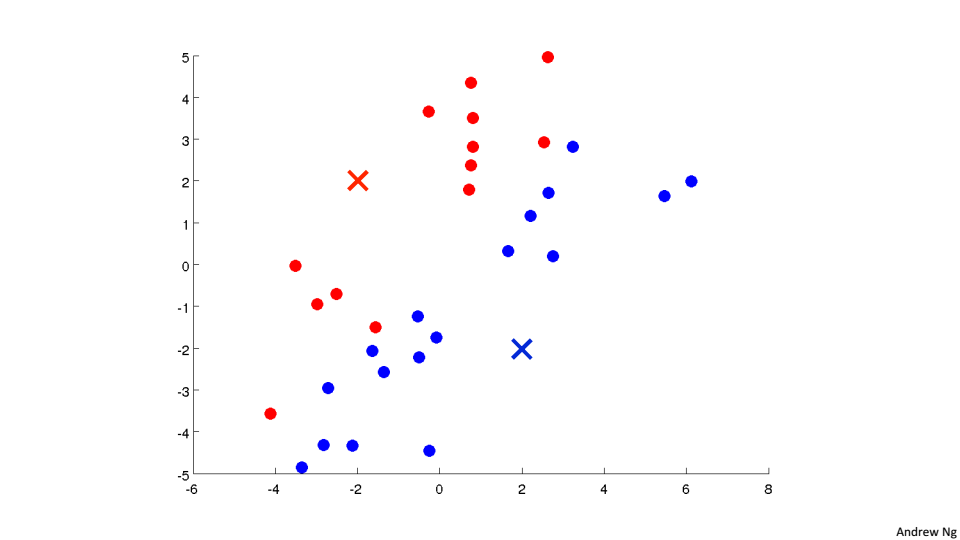
3、然后将红色的聚类中心移动到所有红色点的均值位置,蓝色的聚类中心移动到所有蓝色点的均值位置
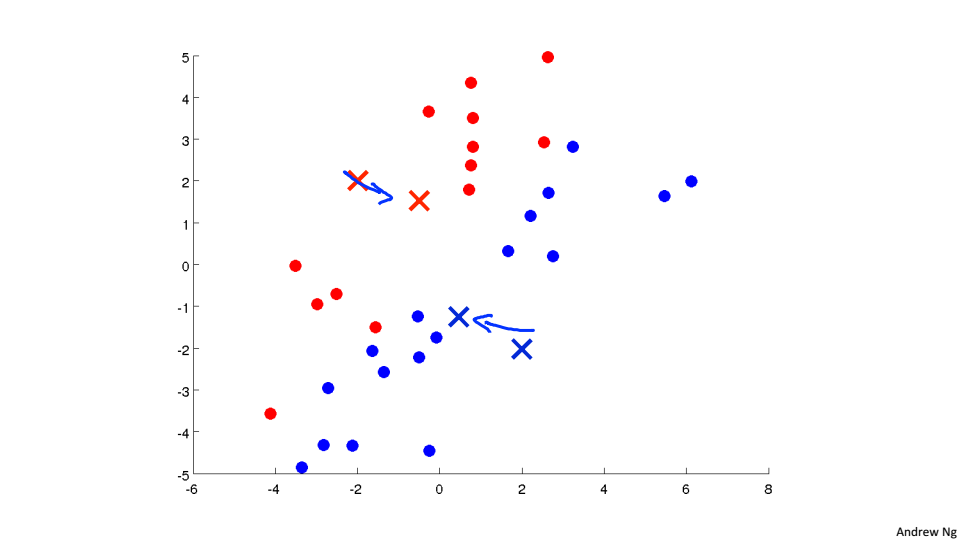
重复2、3过程直到收敛
K-Mean中的K就只的是要分为几类

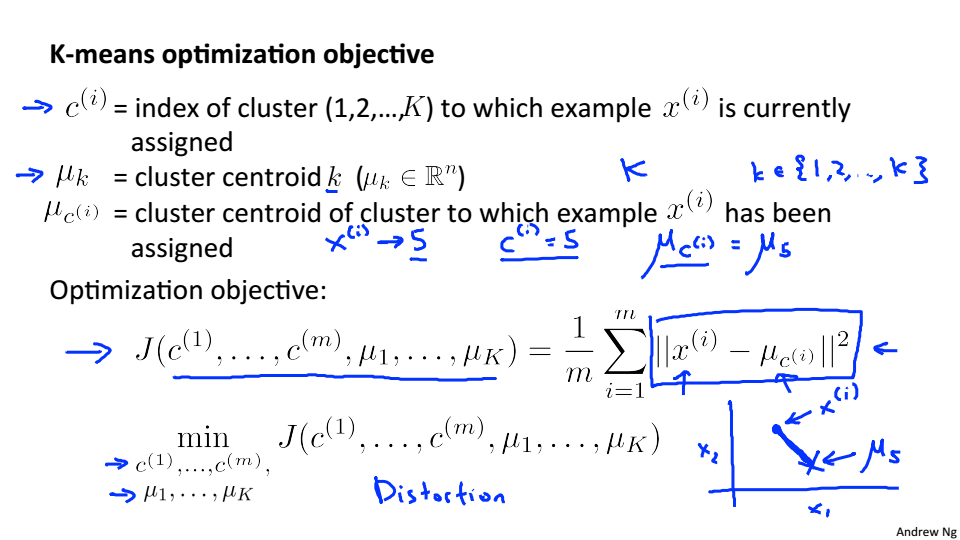
Opetimization objective
K-Mean中的优化目标
J是点到聚类中心的平均距离,J也被称为失真函数
Random Initialization
随机选取聚类中心
一般是随机选取K个样本,在让聚类中心等于这些样本

局部最优
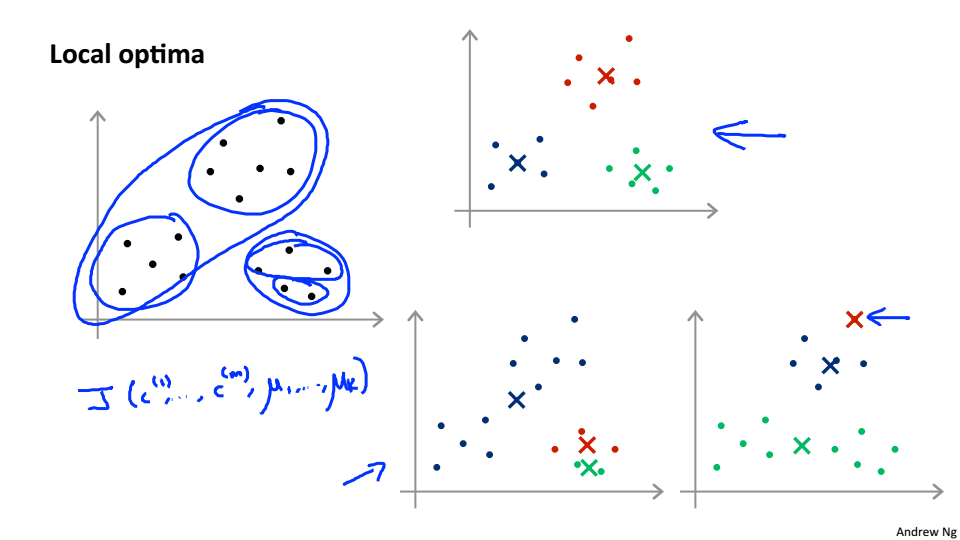
加入随机初始化和代价函数后的K-Mean,最后的J的结果一般在2~10之间才是全局最优解

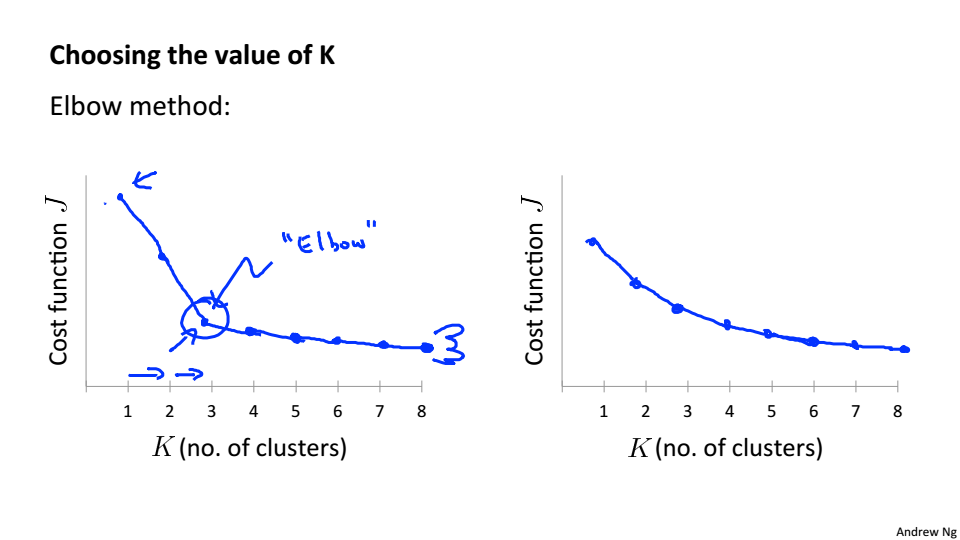
Choosing the number of Clusters
Elbow Method
绘制代价函数关于K的函数曲线,J会随着K的增大而减小,逐渐趋于平稳,拐点处的K即我们所需要的K
但大部分情况拐点不是很清晰,不能很明显的找出来
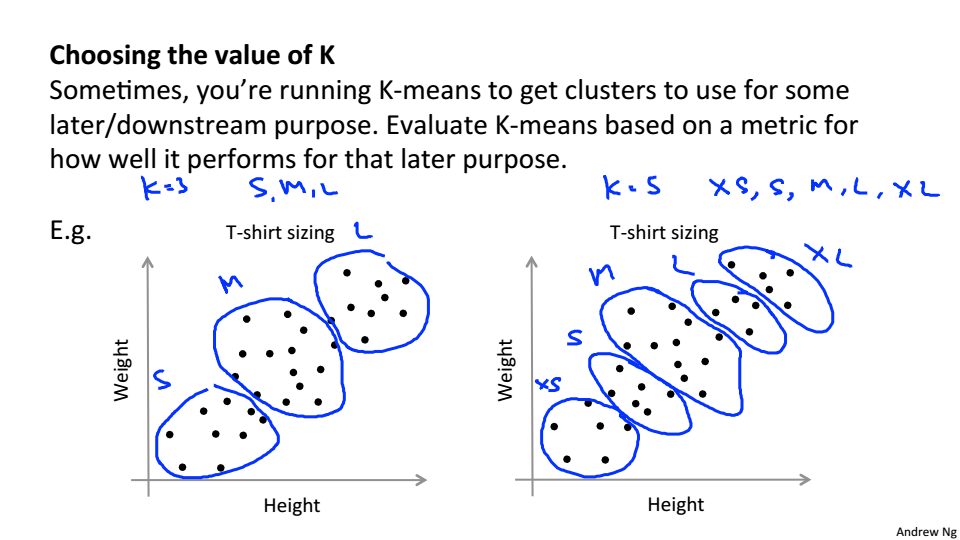
通过聚类要达到的目的来确定K的值,以T恤为例,如果T恤的尺码只有S、M、L那么K就应该选择3
Motivation
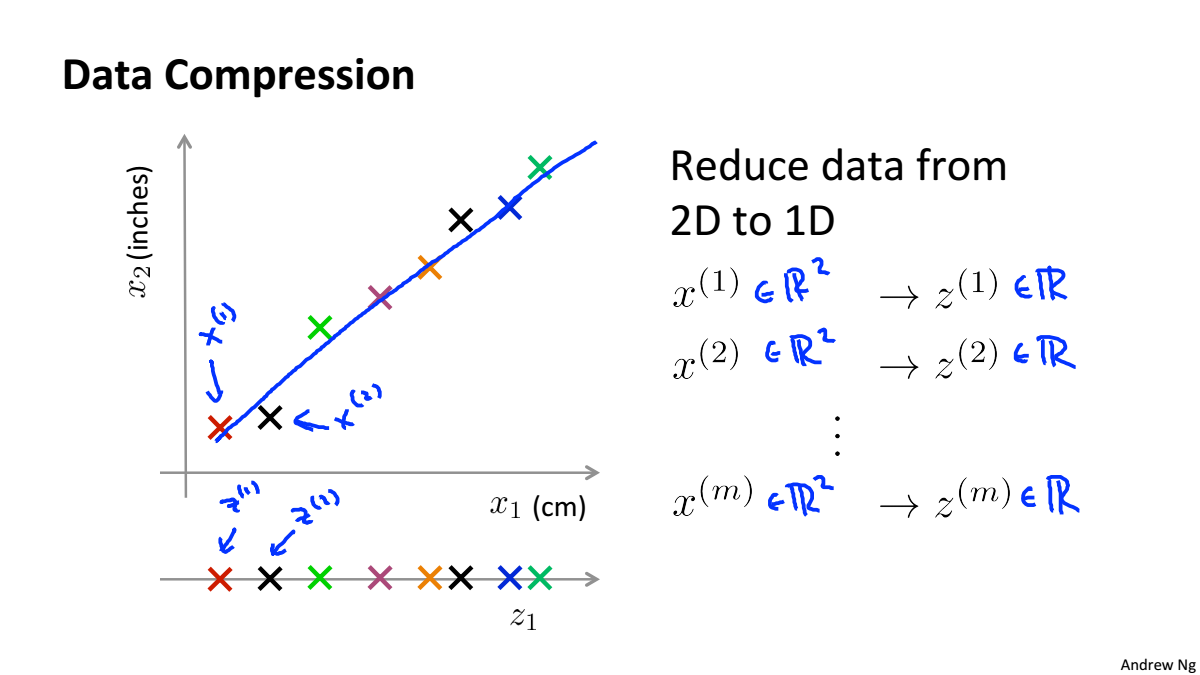
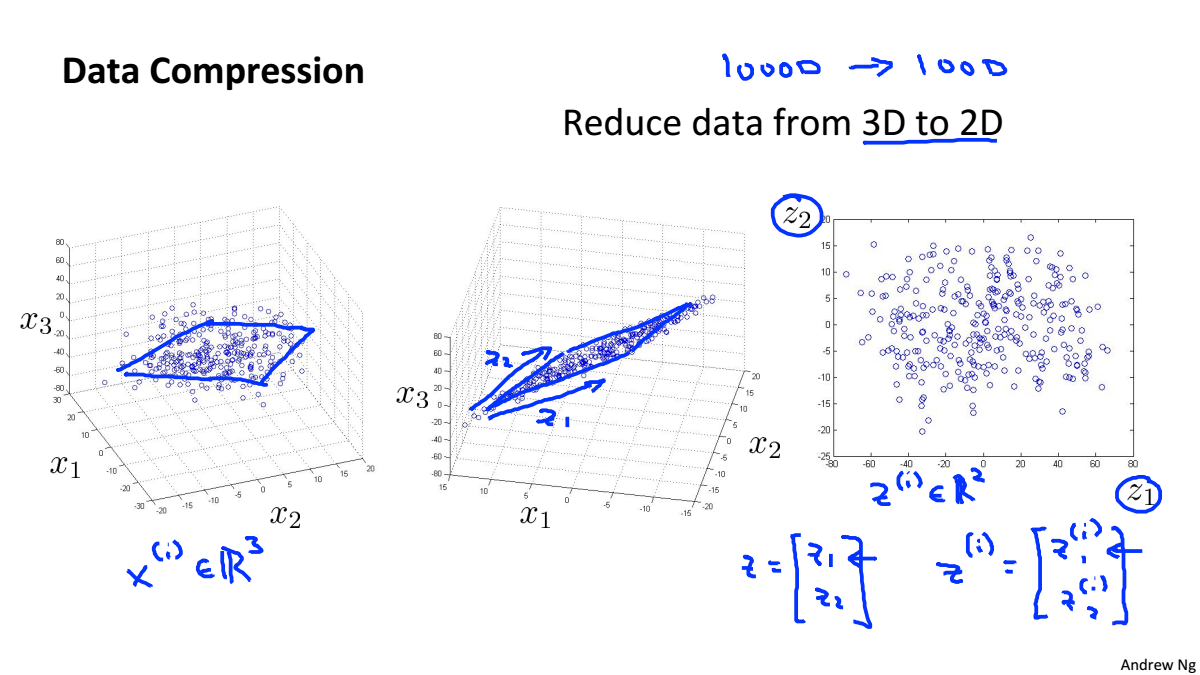
Data Compression
数据压缩不仅可以使数据量减少,减小内存和硬盘的占用,而且可以提高算法的计算速度
数据压缩就是寻找相关特征之间的关系如下图中的x1和x2都是表示长度,只是单位不一样,就可以根据他们的线性关系,合并为一个一维特征
三维数据降到二维
将三维数据投影到一个二维平面
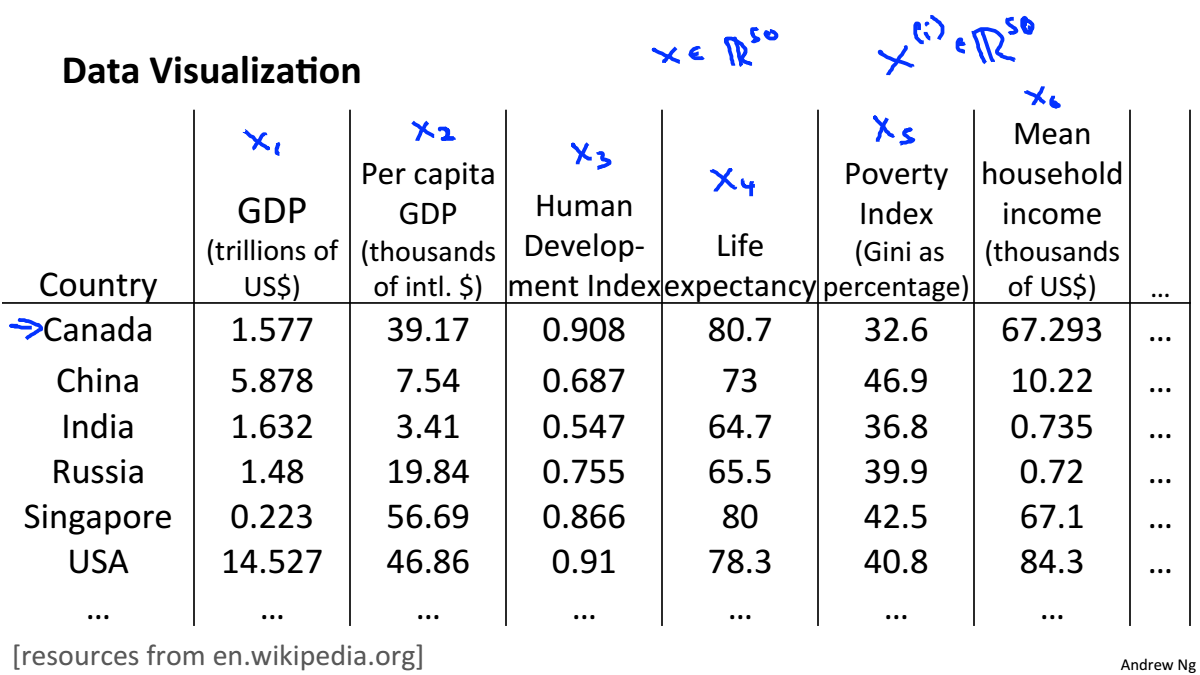
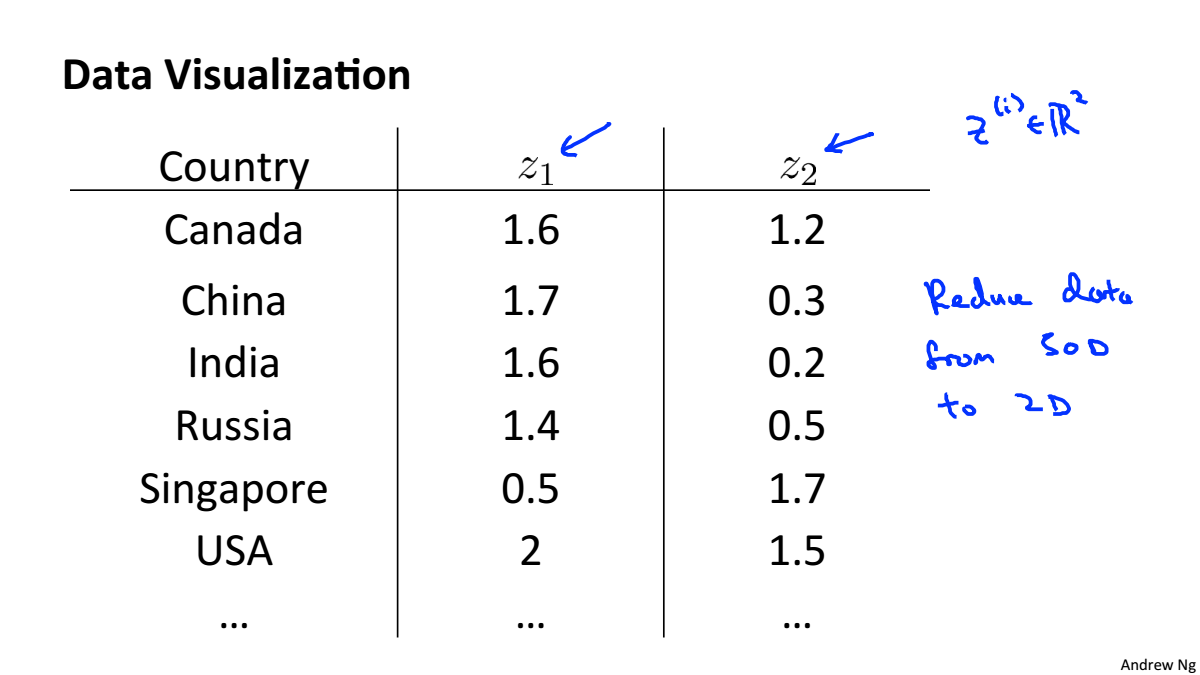
Data Visualiztion
一个高维数据可以被计算机处理,但人只能感知三维的数据,所以在做高维数据可视化时,要先对数据进行降维,在进行可视化。
Principal Component Analysis
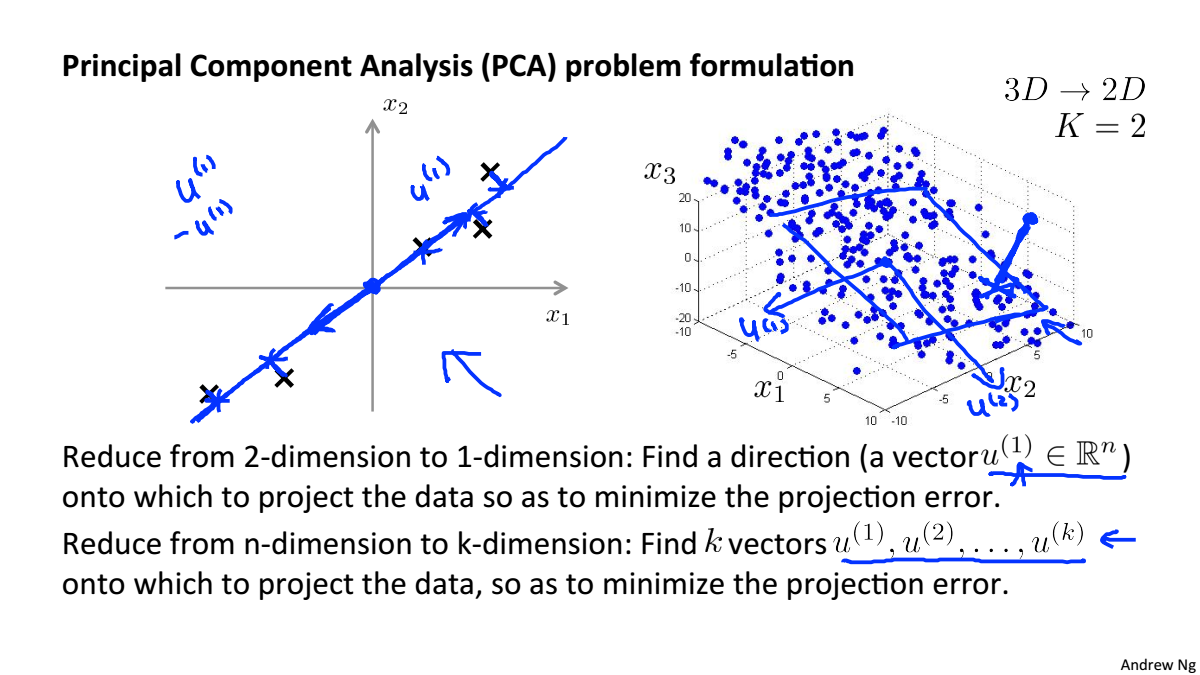
Principal Component Analysis Problem Formulation
PCA将高维数据投影到低维空间,使得数据投影到这个面的误差最小,这个误差也叫作投影误差,在进行降维之前,要对数据进行均值归一化和特征规范化
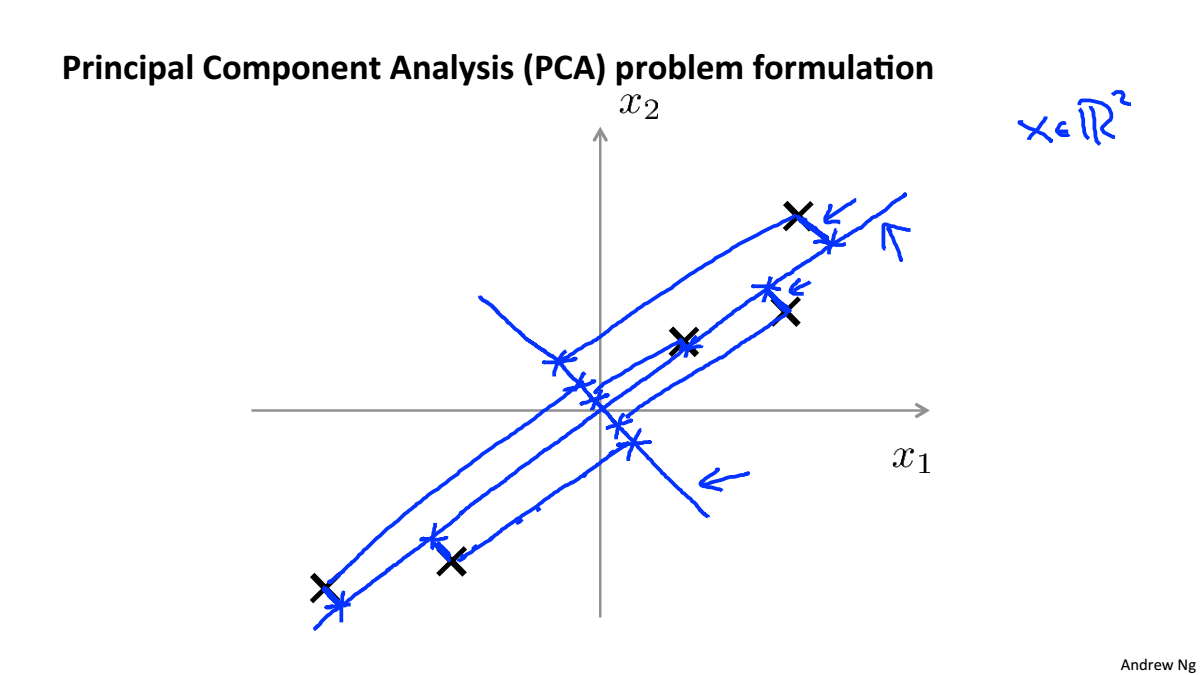
对于二维降到一维,是要寻找一个向量,使得投影误差最小
对于n维降到k维,是要寻找k个向量,使得投影误差最小
PCA和线性回归的区别:
- 线性回归的误差是结果值得误差,PCA是点到投影面的距离
- PCA是无监督学习
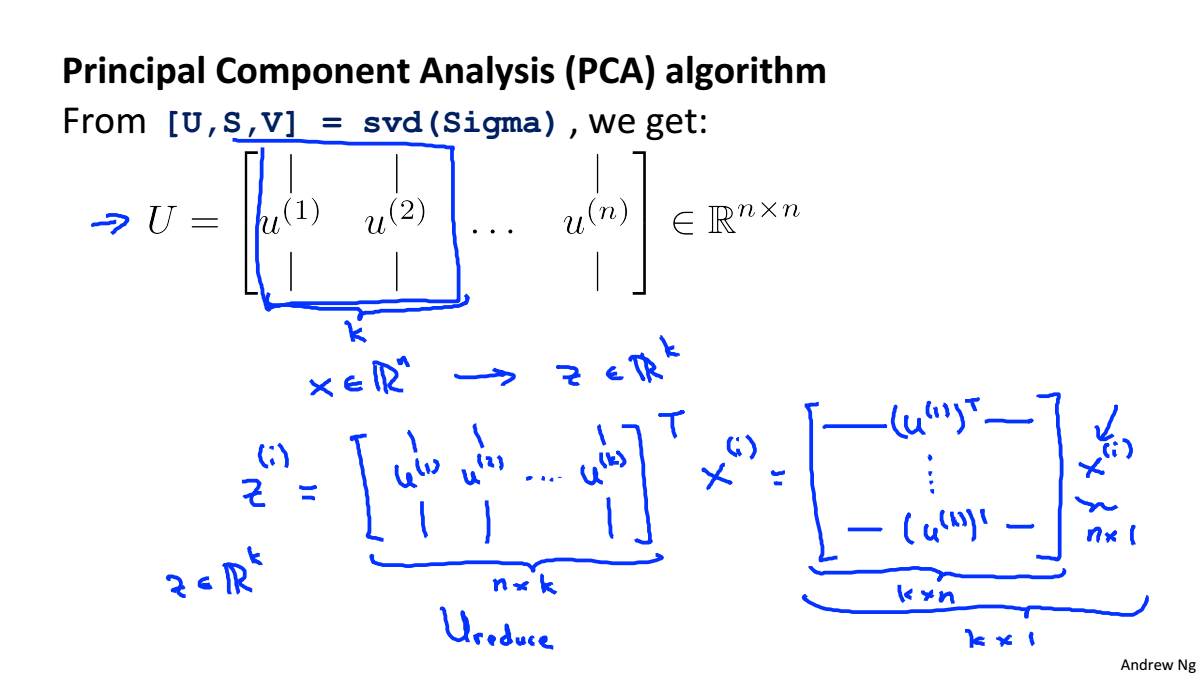
Principal Component Analysis Algorithm
数据预处理(特征缩放/均值归一化)

PCA算法的步骤:
- 计算协方差矩阵
- 使用svd计算
的特征值和特征向量

- 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵
-
就是降维之后的数据
Applying PCA
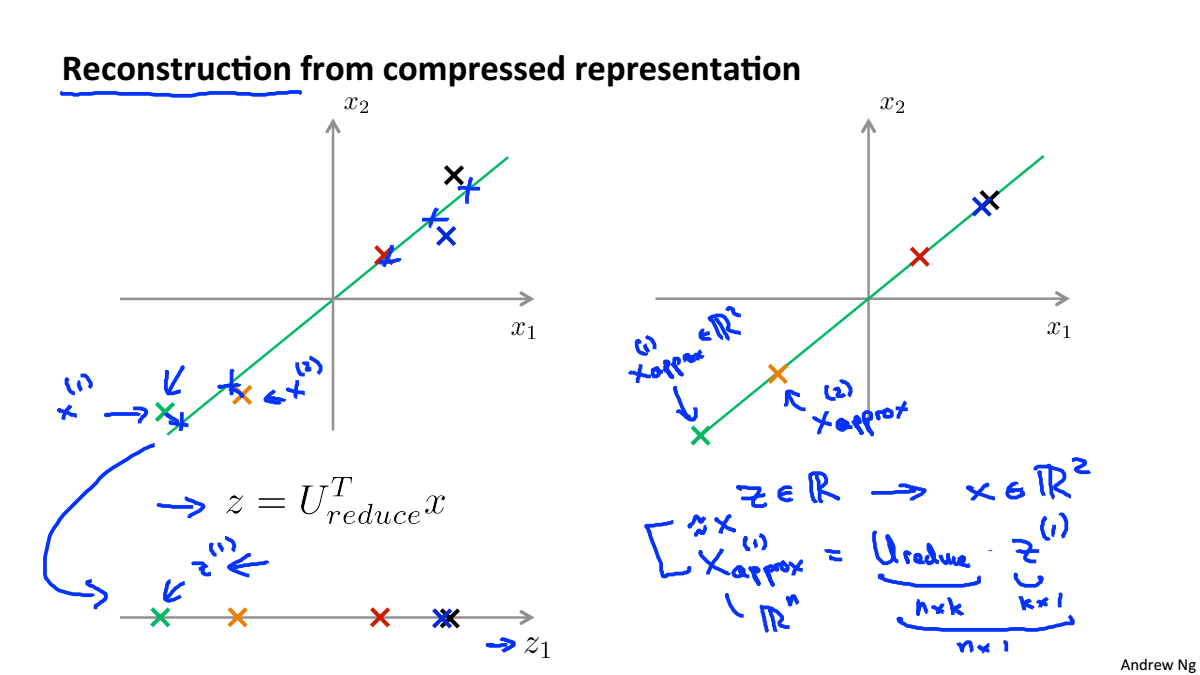
Reconstruction from Compressed Representation
Choosing the Number of Principal Components
计算平均投影误差和总变差的比,选择该值最小时候的K,该值表示的是与原数据的差异性,当为0.01时代表PCA保留了99%的差异性

选择K的两种两种方法:
- 尝试不同的K,计算差异性,如果>99%则符合要求
- 根据svd的到奇异值矩阵,矩阵对角上前K个数的和除以全部数的和就是差异性,从而根据差异性找到K

Advice for applying PCA
监督学习加速
降维矩阵应该在训练集上运行PCA获得,得到降维矩阵后就可以在交叉验证集合测试集上使用

PCA并不是一个防止过拟合的好方法,应当使用正则化来防止过拟合
