问题动机
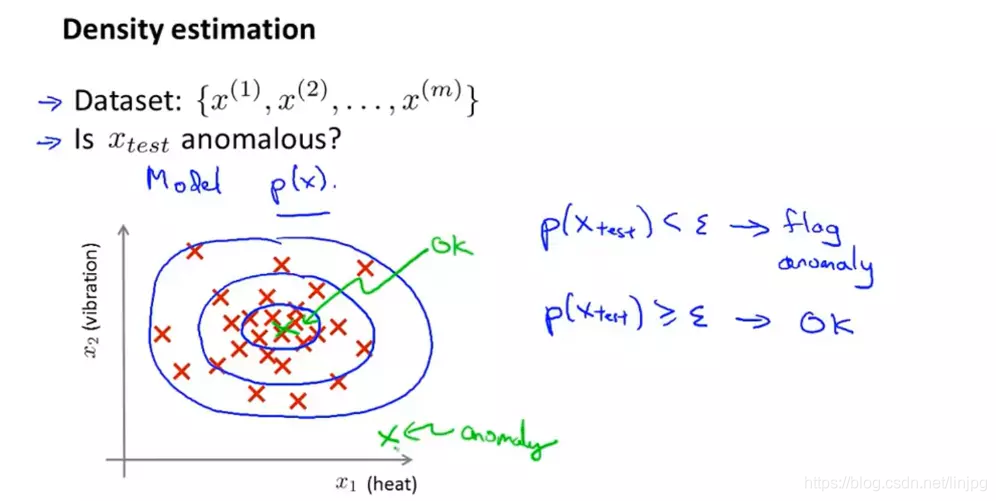
模型建立
再给定训练集的情况下,如何检测某一个输入x是否异常?
首先要根据训练集数据建立一个模型,当给定数据的值的时候,则数据被认定为异常,表示它距离总体数据中心较远时被认定为正常。

欺诈行为识别是异常识别最常用的领域,向量表示用户i的一系列特征,如登录次数,点击某一个页面的次数,发帖次数等,根据这些特征建立模型,然后根据阈值识别欺诈行为。同样,异常识别还用于产品检测等方面。
高斯分布
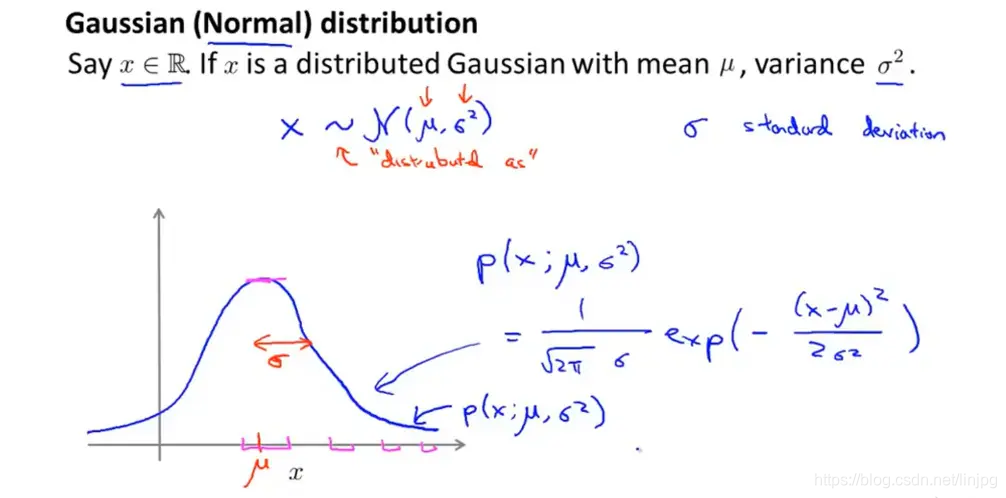
基于高斯分布的异常检测算法

假设样本数据的每一个特征对应一个高斯分布,模型等于这些分布的联合分布。通常,统计学上概率联乘基于独立性假设,但在实际中,若样本数量足够大,是否独立就不那么重要了。

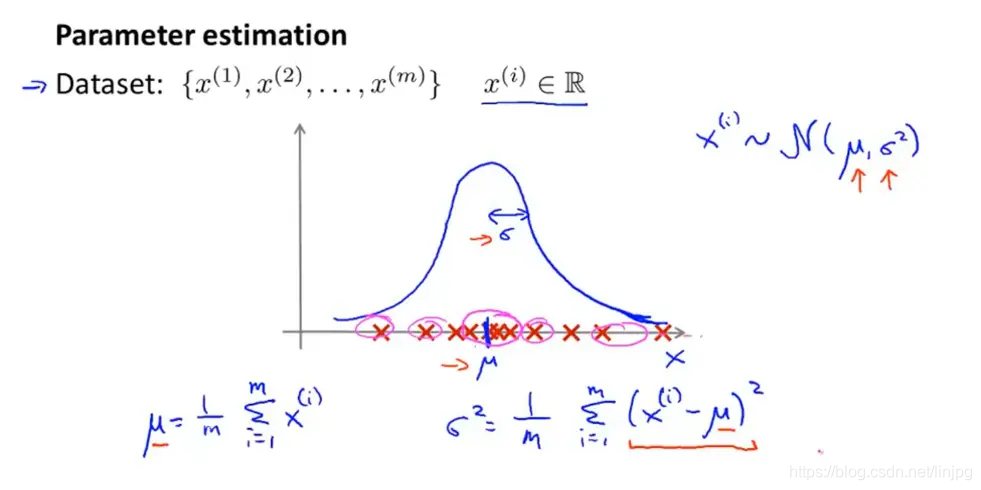
首先选择可能需要的特征,拟合特征的参数,即均值和方差,得到每个特征的分布,也可以用特征向量表示;用所有特征的联合分布构建模型;给定新的样本点x,根据模型计算值,看其有没有小于阈值ε。

上图数据有两个特征,拟合每个特征的参数,p值就表示为在三维图上面的高度。
开发和评估异常检测系统
在进行特征选择的时候,如果想知道是否应该加入一个新的特征,一个数值的评估指标就显得很重要,那么在进行特征选择的时候可以分别计算加入该特征和不加两种情况,当加入该特征时,返回一个数值指标,可以用来判断算法效果是否得到了改进。


假设有10000个正常样本和20个异常样本,按上面的方式进行评估。根据训练集求得特征向量的参数,构造模型,样本的分类比例有不同的方法,但是不要把把验证集同时作为测试集。

首先进行模型的构造,对训练集样本中的每一个特征建立高斯分布擦书,然后通过联乘建立模型,因为样本其实是有标签的,即,是带有标签y的,那么,y就可以用来帮我们判断模型的好坏。建立模型以后,在验证集中进行算法评估,将验证集中的某一个样本值x输入到模型中,根据阈值预测验证集样本的标签,大于阈值则为正常点,小于阈值为异常点。然后在与样本的实际标签作对比,计算评估指标如准确率,召回率,F-score等。

对于模型中的阈值ε的选择,可以尝试不同的ε,然后选择对应的F-score最大的ε。
既然我们有了带标签的数据,为什么不适用线性回归,逻辑回归等方法进行异常点识别呢?
异常检测VS监督学习

异常检测适用于正样例(y=1)数量非常少,而负样例(y=0)数量非常多的样本。因为这正样本正样例太少,无法找到所有的异常原因,若进行监督学习的话,无法学到所有的知识,还有可能会存在未来会发生的新的异样,这些异常现在无法观测的到,更无法进行建模。相反,异常检测是对大量的负样例进行建模,这样任何偏离模型的样本就可以被识别为异常,而不用研究异常的原因是什么。之前在讲述有监督的学习的时候提到过例子,垃圾邮件的分类,就是因为我们拥有的垃圾邮件的数量非常多,可以总结出垃圾邮件的普遍特征,因此有利于算法学习和建模。
因此,当负样例即异常点数量非常少的时候,可以使用异常检测法对数据中的负样例进行建模,偏离正常点的数据都被认为是异常点;当负样例即异常点数量非常多的时候,监督学习算法可以有效地进行学习,因此,这个时候可以选择监督学习的算法进行异常点识别。
选择异常算法要使用的功能
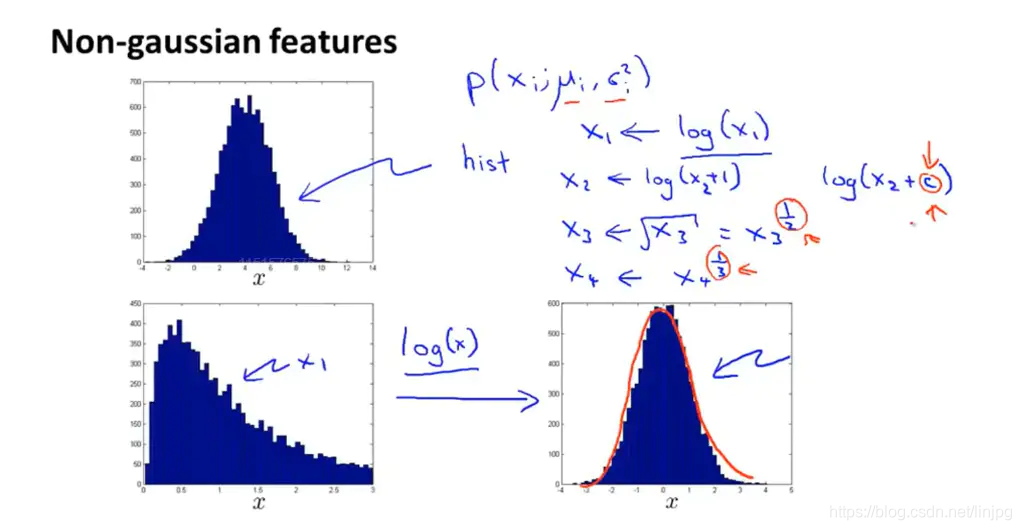
在进行异常检测的时候,我们认为数据的分布符合高斯分布,然后根据训练集进行参数估计,再通过联乘进行模型构建,然后在验证集中进行验证。但是,实际上很多特征的分布不是符合高斯分布的,此时我们可以通过变换将其调整为高斯分布(实际上样本数量足够多的情况下不进行调整也可以,但是如果进行了调整,模型效果肯定会更好)。调整的方式有很多,如上图所示,可以将参数数值取对数,进行开方等,通过调节幂指数等参数,是数据的分布趋向于高斯分布。
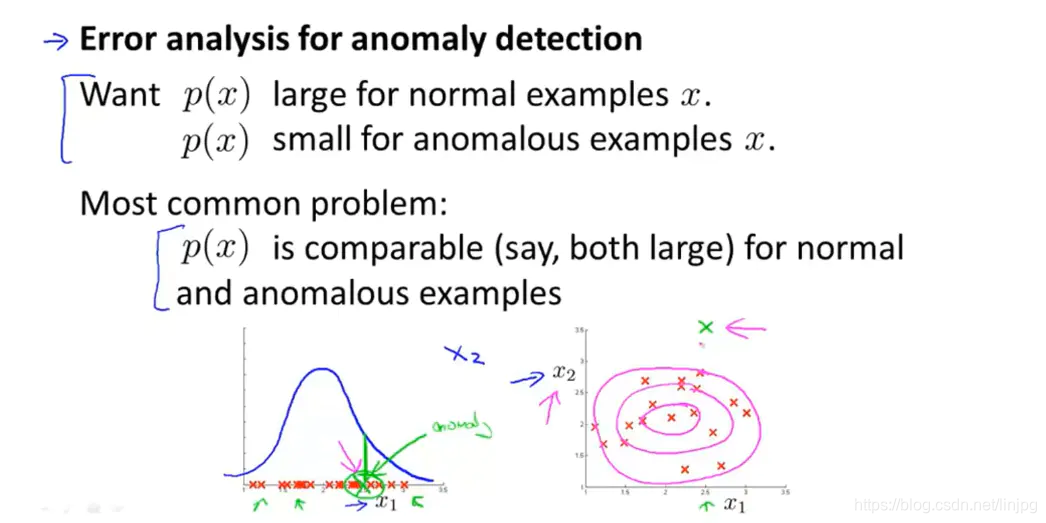
我们希望的得到的模型在正样例上数值较大,在负样例上数值较小。我们可以采取这样的方法,先进行初始模型的建立,在最后分析模型的表现,当模型表现不好的时候在分析可能产生的原因是什么,根据这些原因再去选择合适的特征。一个常见的问题是单一特征的时候,异常点和正常点的额都很大,此时,就可以添加新的特征去进行异常点检测。

我们可以根据对问题的判断,自己构造特征。
多变量高斯分布
异常检测的一种延伸
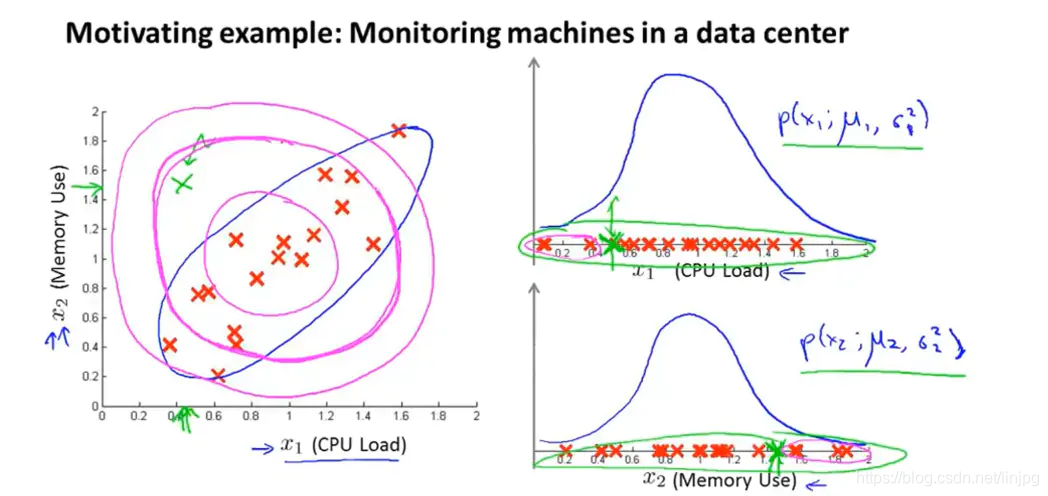
上图左上角的绿色点是异常数据,因此通常在CPU负载较低的时候,内存使用应该较低,但是这个点不同。当分别考虑CPU负载和内存使用两个特征的时候,如右边两个坐标所示,这个异常点并没有表现出来异常,从CPU负载来看,小于该点的值也有很多;从内存使用来看,大于该点的也有很多。这样一来使用异常检测算法就不能识别出这个异常点,这是因为进行高斯异常检测的时候,是按照左图洋红色线来划分的,越靠近内部圆圈的点越是正常,原理内部圆的点越不正常。这样就忽略了不同特征之间的关系。
为了改进这种异常识别算法的不足,就有了改进的异常检测算法,即多变量高斯分布 。

多变量高斯分布
多变量高斯分布在建立模型的时候不在分别将每一个特征的分布看做一个高斯分布,而是整合成一个分布,分布中的参数表示样本的协方差矩阵。随着参数的变化,样本分布变化如图:
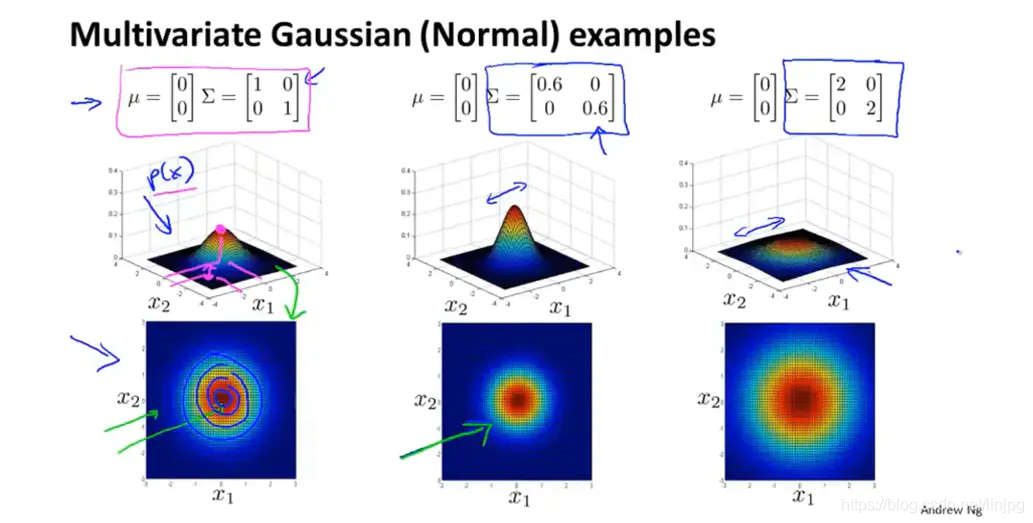
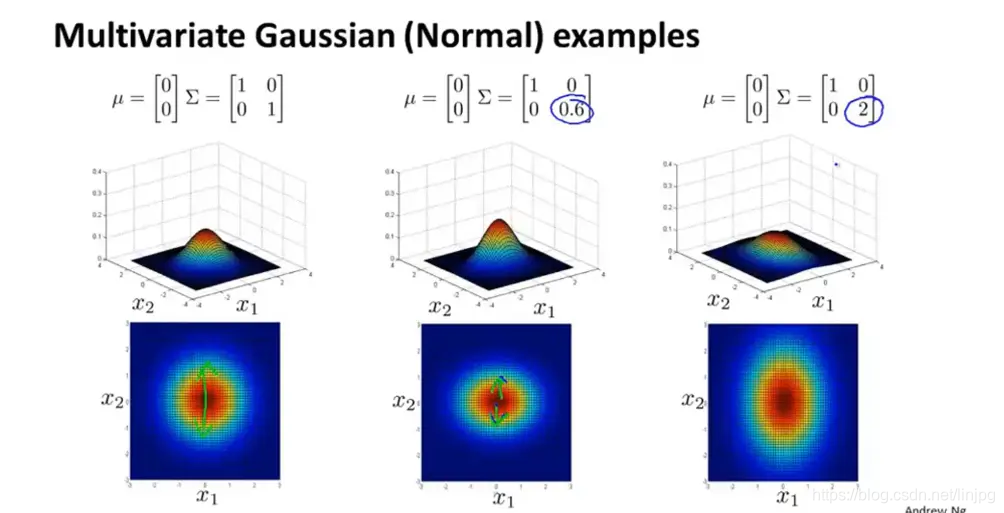
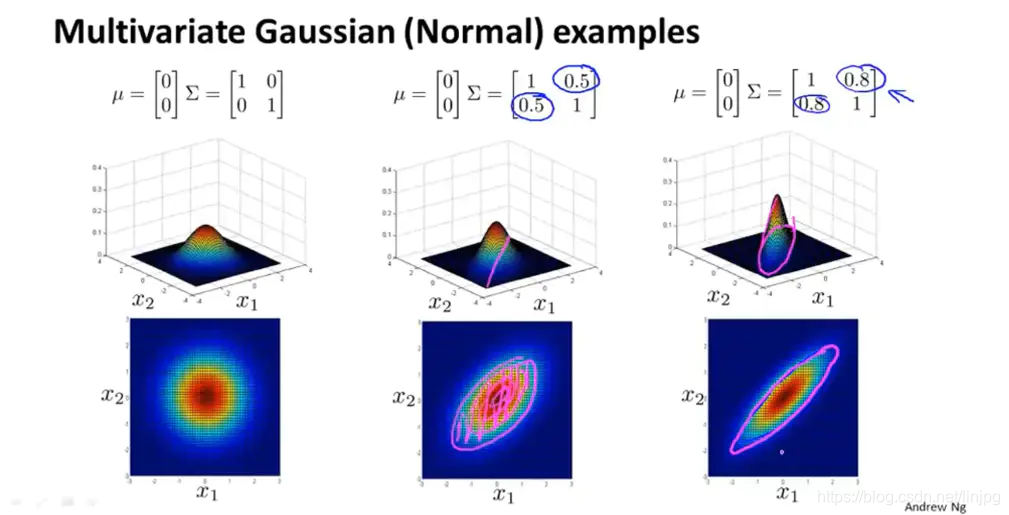
当特征方差同时变化时
当只有一个特征向量的方差变化时
当两个特征向量高度正相关时
协方差矩阵的副对角线上元素的大小表示两个特征的相关系数,因此,数值越大,两个特征的相关性越大,则样本分布图如上所示。同理,相关系数为负的时候,表示两个特征负相关,则样本分布如下所示:
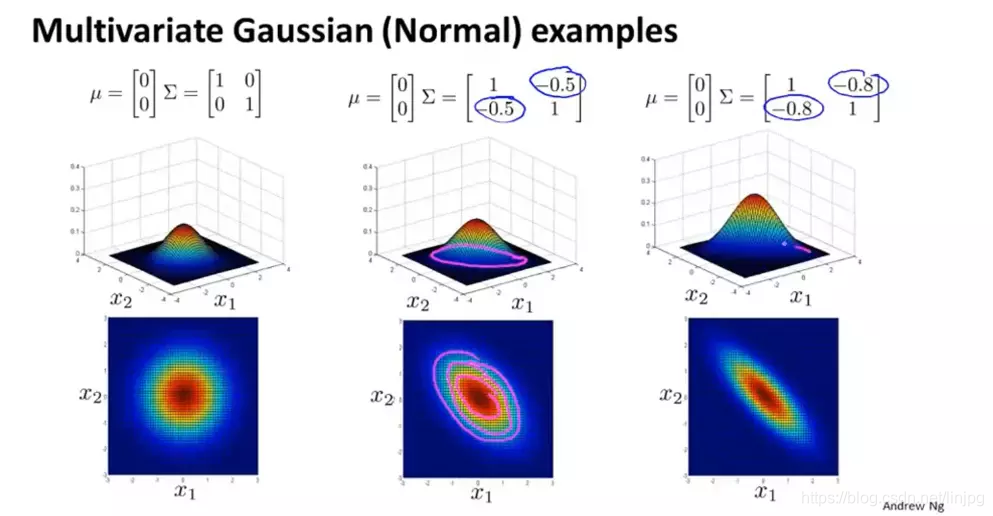
特征负相关
当改变均值的时候,分布的峰值会发生改变,即改变均值就是移动整个分布的中心:
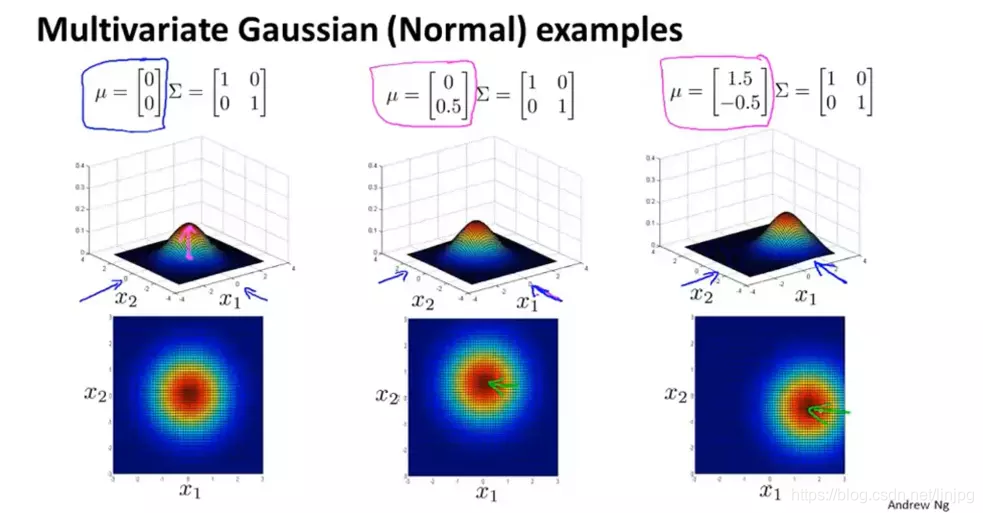
均值改变的多元高斯分布
多变量高斯分布的异常检测
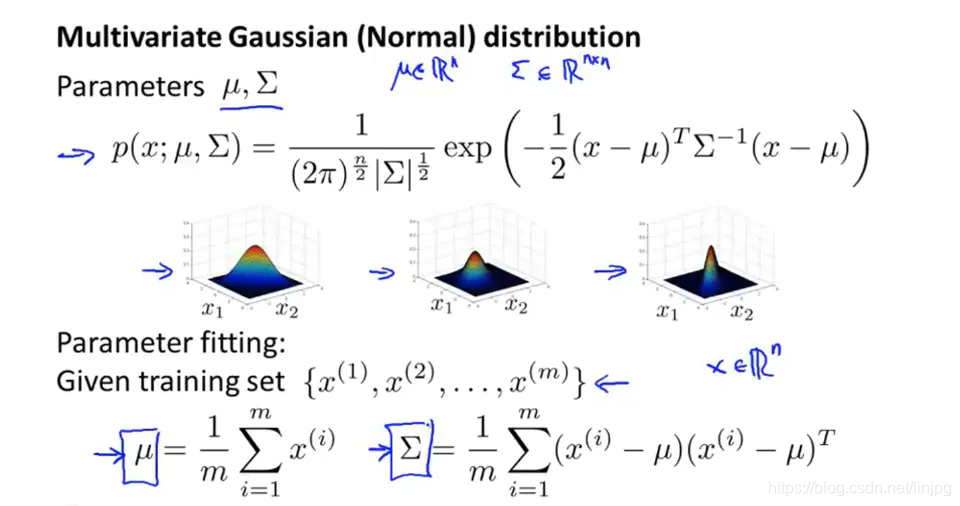
多元高斯分布的参数估计
在多元高斯分布中,要估计的参数就是均值向量和sigmoid函数。

多元高斯分布模型
在求出参数以后,可以按照上述公式建立模型,给定一个新的样本x,当其小于阈值ε的时候就会被认定为异常。

与单变量高斯模型的比较
单变量高斯分布其实就是在样本特征相互独立的时候的一种特殊的多元高斯分布的情况

传统高斯分布与多变量高斯分布的对比
在传统的高斯分布中,如果能手工建立相关特征之间的关系,捕捉异常关系,那么是可以使用传统的高斯异常检测的,如果不能自己识别建立这种关系,那么就适合使用多元高斯分布,它会自动捕捉特征之间的关系;在训练集规模较小的时候使用传统的高斯分布是可以的,若要使用多元高斯分布,那么就要求训练集数据量要很大,训练集数据量m要远远大于特征个数n,一般m>10n,效果较好,不然就会出现奇异矩阵。再优点方面,传统的高斯分布可能计算较为简单,而多元高斯分布计算量随着特征的个数上升。
如果在使用多元高斯分布的时候产生了奇异矩阵,可能是存在以下两方面的问题:一是数据量太少,没有达到远超过特征数的要求;另一方面是存在特征冗余,即特征之间存在线性关系。
参考资料 吴恩达机器学习—异常检测
吴恩达机器学习笔记之异常检测
吴恩达机器学习中文版笔记:异常检测(Anomaly Detection)
