SMO算法看了近3遍感觉还是有点朦朦胧胧,模模糊糊。
所以索性,理解多少写多少,避免遗忘。可能会有很多错误,欢迎指正。
主要基于李航的《统计学习方法》
SMO(sequential minimal optimization)序列最小最优化算法
我们在讨论支持向量机的学习问题时,可以将其转换成求解凸二次规划问题。实现支持向量机的学习是要找到这样的凸二次规划问题的全局最优解,SMO就是支持向量机学习的一种快速算法,也是一种启发式算法。
基本思路:
如果所有变量的解都满足此优化问题的KKT条件,那么这个最优化问题的解就得到了。(KKT条件是该最优化问题的充分必要条件)。否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。子问题的两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定。如此,SMO算法将原问题不断分解为子问题求解,进而达到求解原问题的目的。[1]
特点:
将原始的二次规划问题分解为只含有两个变量的二次规划子问题,对子问题不断求解,使得所有的变量满足KKT条件
包含两部分:
1、求解两个变量二次规划的解析方法
2、选择变量的启发式方法
SMO算法要解的是如下凸二次规划的对偶问题:
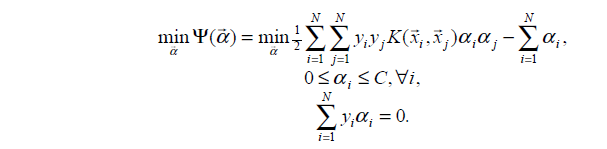
其中,K( ,)是核函数
两个变量二次规划的求解方法
1、SMO的最优化问题的子问题
前面提到将原始的二次规划问题分解为只含有两个变量的二次规划子问题,所以假设选定两个变量、
,其他变量相当于常数,省略常数后,SMO的最优化问题的子问题可以化简成以下形式:

最终的优化目标是:
![]() ………… (1)
………… (1)
原来的约束条件变成:
s.t. (用
表示)…………(*)
还有
(注意,对于式子,我们在用
表示
时,等式两边同时乘
就可以,不要用除以
的方式,要时刻记住
=1)
2、视为一元函数,求导取极值
(1)式可以看成是一个二元函数,根据于和
的约束关系,可以把
消去。不过我们的目的是为了关于
求导,导数为0的点就是要找的极值点,所以这里既可以把
消去后对
求导,也可以直接在现在这个式子上对
求导。
根据(*)式得
![]() …………(2)
…………(2)
代入(1)式中,可以看成是一个一元函数
用来表示最优化的目标,将
带入得到
对上式中的求导等于0
![]() …………(3)
…………(3)
借用参考3中博客解析

把(4)(6)(7)式带入到(3)式中去,并进行化简
其中
得到…………(8)
3、对原始解进行裁剪
裁剪的问题,博客2里得部分讲的很详细(具体的就不贴出来,请参看最后的参考博文链接)
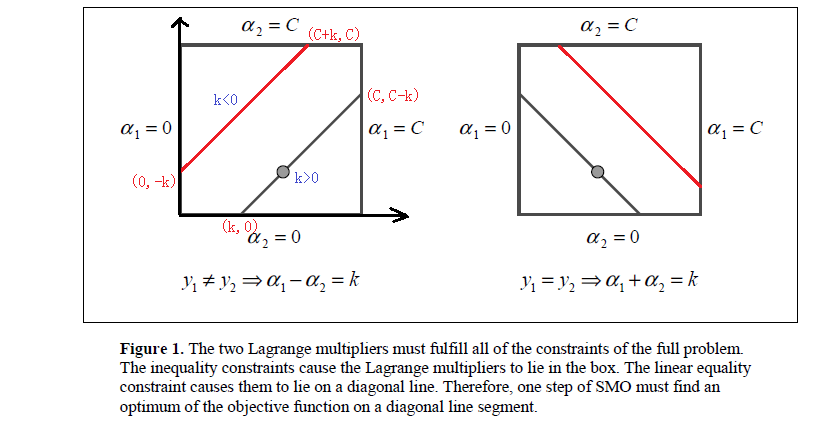
对约束条件对应的*式,考虑两种情况,分别如上图所示。
需要满足约束条件
,所以最优值
的取值范围也要满足条件
L和H分别是坐在的对角线段端点的界。
当时,
的可行域为
,区间端点分别为:
,
当时,
的可行域为
,区间端点分别为:
,
所以在更新时,要先求出
的可行域,然后用之前的那个公式求出极值点
,然后看极值点
处的在不在可行域范围内,在的话就使用极值点处的
,不在的话就使用边界值H或者L更新,具体更新规则为:

4、求解
由于只有两个变量,根据
可以求得…………(9)
其他一些内容涉及到论文《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》
等看完再补充
选择变量的启发式方法
1、第1个变量的选择
SMO称第1个变量的选择称为外循环。外循环在训练样本中选取违反KKT条件最严重的样本点,将其作为第一个变量。
遍历的时候首先遍历满足的样本点,也就是在间隔边界上的支持向量点,检验是否满足KKT条件;
如果都满足,那么遍历整个训练集,检验是否满足KKT条件。

2、第2个变量的选择
SMO称第2个变量的选择称为内循环。在找到第一个变量的基础上,第二个变量的标准是希望能使有足够大的变化。
由上述的(8)式,是依赖于|E1−E2|,为了加快计算的速度,做简单的就是选择|E1−E2|最大时的
当E1为正时,那么选择最小的Ei作为E2;如果E1为负,选择最大Ei作为E2。
为了节省时间,通常为每个样本的Ei保存在一个列表中,选择最大的|E1−E2|来近似最大化步长。
3、计算阈值b和差值
这一部分还没理解。空着先……
参考:
1、李航的《统计学习方法》