一、前期准备
- 准备一台客户机
- 安装jdk
- 配置环境变量
- 安装Hadoop
- 配置环境变量
二、配置集群
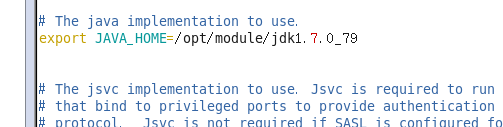
- 配置hadoop-env.sh文件
cd /opt/module/hadoop-2.7.2/etc/hadoop
vim hadoop-env.sh
- 配置core-site.xml
这个文件也在hadoop目录下
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
- 配置hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
三、启动集群
- 格式化namenode
注意:这里第一次格式化就好了,后面不要格式化,否则会出问题!!!
bin/hdfs namenode -format
-
启动namenode
sbin/hadoop-daemon.sh start namenode -
启动DataNode
sbin/hadoop-daemon.sh start datanode
四、查看集群
- 查看集群是否启动成功
 namenode和datanode启动成功
namenode和datanode启动成功
2.查看产生的log日志
logs文件位于/opt/module/hadoop-2.7.2目录下

3.在web端查看HDFS文件系统
在web浏览器中输入http://192.168.23.101:50070/explorer.html#/
如果不能访问的话,看如下帖子处理 http://www.cnblogs.com/zlslch/p/6604189.html

五、操作集群
- 在hdfs文件系统上创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input - 将测试文件内容上传到文件系统上
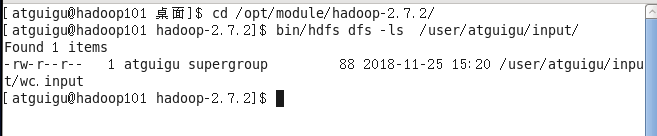
bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/ - 查看上传的文件是否正确
bin/hdfs dfs -ls /user/atguigu/input/
bin/hdfs dfs –cat /user/atguigu/wc.input
- 在Hdfs上运行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output - 查看输出结果
bin/hdfs dfs -cat /user/atguigu/output/* - 将测试文件内容下载到本地
hadoop fs -get /user/atguigu/output/part-r-00000 ./wcoutput/