前面几节详细介绍了卷积神经网络和深度卷积神经网络,这个网络可以说是为图像处理量身制作,同时在2010年,hintion带领的团队使用AlexNet网络(深度卷积网络)在ImageNet大赛中获得冠军,更是奠定了卷积网络的商业地位,到目前为止该网络也是图像识别的主要网络之一。本节开始针对深度网络进行优化探讨,然后针对卷积神经网络探讨优化问题本篇。不是本人所写,是国外的博客,在阅读时,感觉写的很好,同时有图像很形象,因此这里翻译过来供大家参考,文末给出链接,通过优化可以知道深度网络的优缺点,如何针对网络进行优化将对我们都很有很有好处。这个系列会写很多篇,都是干货

深度学习在很大程度上是关于解决大规模讨厌的优化问题。神经网络仅仅是一个非常复杂的功能,由数百万个参数组成,代表了问题的数学解决方案。考虑图像分类的任务.AlexNet网络是一个数学函数,它采用表示图像RGB值的数组,并将输出生成为一堆类分数。
通过训练神经网络,我们基本上意味着我们正在最小化损失函数。这个损失函数的值为我们提供了衡量我们的网络在给定数据集上的性能与完美程度的距离。
损失函数
为了简单起见,让我们假设我们的网络只有两个参数。在实践中,这个数字大约是十亿,但我们仍然会坚持整个帖子中的两个参数示例,以便在尝试可视化事物时不会让自己疯狂。现在,一个非常好的损失函数的计数可能看起来像这样,如下图。
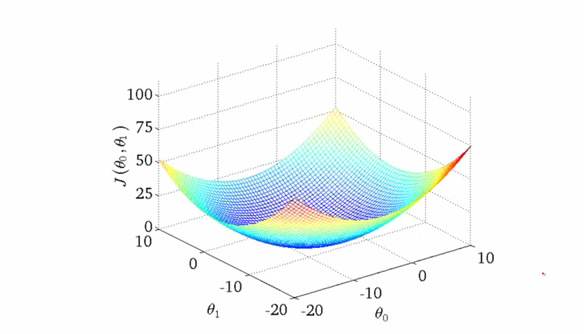
我为什么说的英文一个非常好的损失函数?因为具有如上所述轮廓的损失函数是凸函数,但是这样的损失函数一般不存在。然而,它仍然是一个体面的教学工具,以获得一些关于梯度下降的最重要的想法。那么,让我们来吧!
图中的X和ÿ轴代表两个权重的值。所述ž轴表示损失函数的值。我们的目标是找到损失最小的权值。一点一这被称为损失函数的最小值。
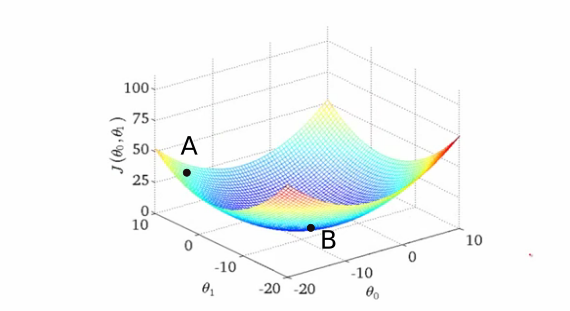
刚开始时随机初始化了权重,所以你的神经网络可能就像你醉汉一样,将猫的图像分类为人类。这种情况对应于轮廓上的点A,其中网络表现不好并且因此损失很高。我们需要找到一种方法以某种方式导航到“谷”的底部到乙点,其中损失函数具有最小值?那我们怎么做呢?
梯度下降
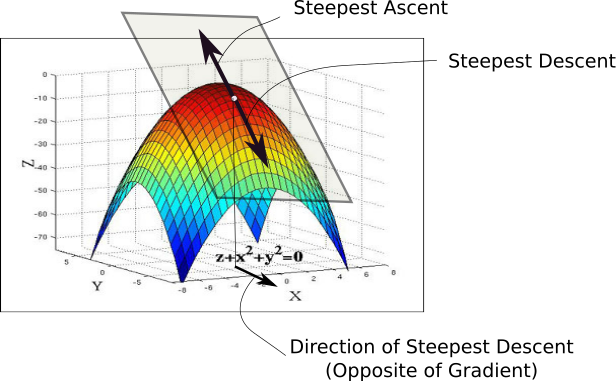
当我们初始化我们的权重时,我们处于损失误差很大的甲点。我们要做的第一件事就是检查的xy平面中所有可能的方向,沿着哪个方向移动导致损失函数值的最大下降。这是我们必须移动的方向。这个方向由与梯度方向完全相反的方向给出。梯度,高维表亲,为我们提供最陡上升的方向。
下图将帮助你理解这一点。在曲线的任何一点,我们都可以定义一个与该点相切的平面。在更高的维度,我们总是可以定义超平面,但现在让我们坚持使用维平面吧。然后,我们可以在这个平面上拥有无限的方向。在他们中间,正好一个方向将为我们提供功能最陡上升的方向。该方向由梯度给出。与之相反的方向是最陡下降的方向。这就是算法得到它的名字的方式。我们沿着渐变的方向进行下降,因此,它被称为渐变下降。(这里需要大家深入理解什么是梯度,为什么梯度方向就是函数上升最快的方向,理解不请的查看我的这篇文章,这里你会彻底的深入理解什么是梯度的)
现在,我们有了前进的方向,我们需要设置前进的步伐即每次前进多少。步骤此大小的称为学习率。我们必须仔细选择它,以确保我们能够达到最低标准。
如果我们走得太快(很大),我们可能会超过最小值,并继续沿着“山谷”的山脊反弹而不会达到最小值即会产生振荡。太慢了(
很小),训练时间可能太长,根本不可行。即使情况并非如此,学习速度非常慢也会使算法更容易陷入局部最小值,我们将在本文稍后介绍。
一旦我们得到了梯度和学习率,我们就采取一个步骤,并在我们最终的任何位置重新计算梯度,并重复该过程。
虽然梯度的方向告诉我们哪个方向有最陡的上升,但它的大小告诉我们最陡的上升/下降是多么陡峭。因此,在最小值处,轮廓几乎是平坦的,您会发现渐变几乎为零。实际上,对于最小点而言,它恰好为零。
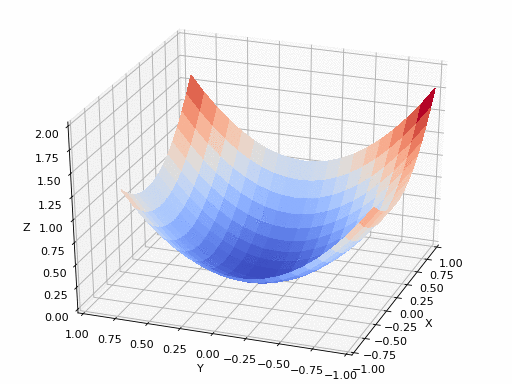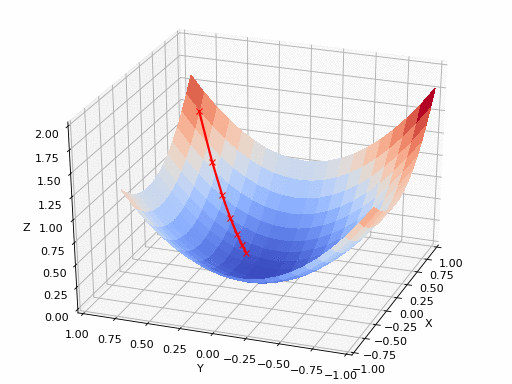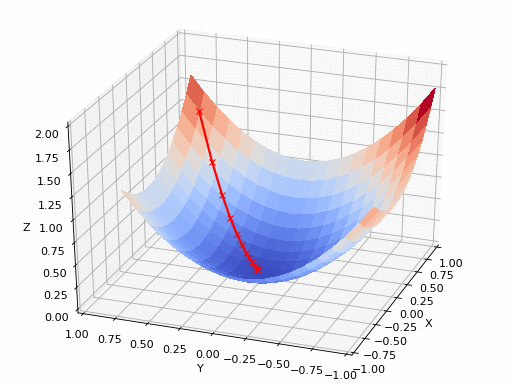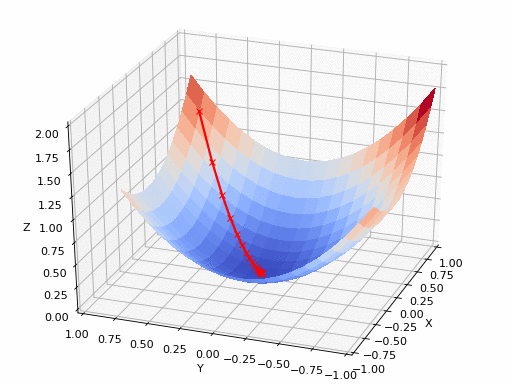
下降的梯度下降
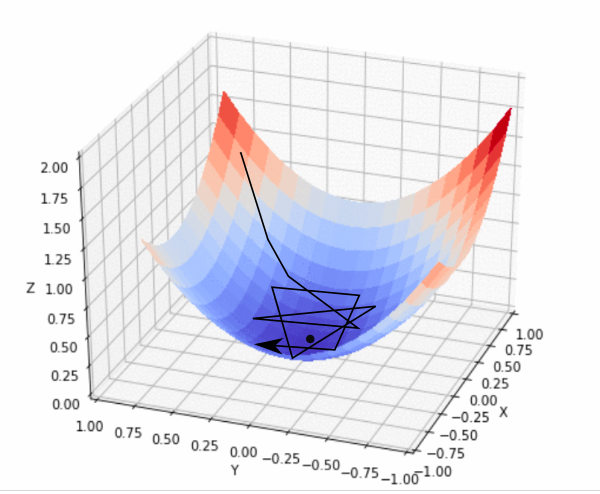
使用太大的学习率的效果
在实践中,可能我们永远也。不能正好到达极小值,但我们在极小值附近保持振荡。当我们在这个区域振荡时,损失值不会发生太大变化,因为我们只是在实际最小值附近反弹。通常,当损失值未在预定数量(例如10或20次迭代)中得到改善时,我们停止迭代。当这样的事情发生时,我们说我们的训练已经收敛了。
常见错误
让我稍稍停顿一下。如果你上网搜索梯度下降的可视化图像,你大概会看到从某一点开始,朝向最低点的一条轨迹,就像前面的动画一样。然而,这只是一个不精确的示意。实际上,轨迹完全被限制在XY权重平面上,完全不涉及ž轴上的移动这是因为权重是唯一的自由参数如下图所示。:
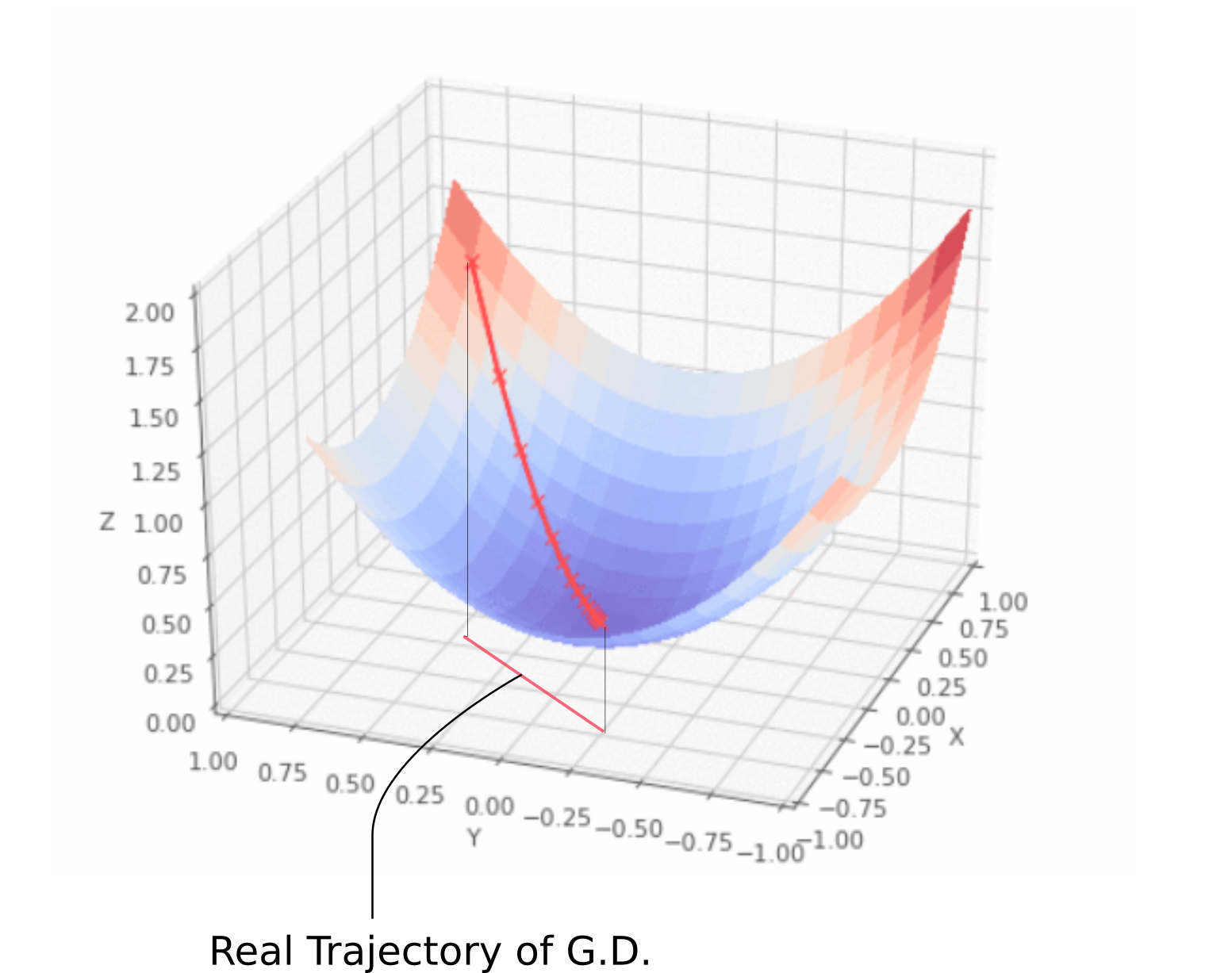
XY平面中的每个点代表一个独特的权重组合,我们希望有一组由最小值描述的权重。
基本方程
描述梯度下降更新规则的基本方程是:
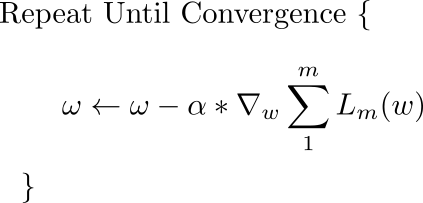
此更新在每次迭代期间执行。这里,w是权重向量,它位于xy平面中。从该向量中,我们相对于权重乘以α(学习率)减去损失函数的梯度。梯度是一个向量,它给出了损失函数具有最陡上升的方向。最速下降的方向是与梯度完全相反的方向,这就是我们从权重向量中减去梯度向量的原因。
如果想象向量对你来说有点困难,几乎相同的更新规则同时应用于网络的每个权重。唯一的变化是,由于我们现在为每个权重单独执行更新,因此上述等式中的梯度将替换为沿特定权重所表示的方向的梯度向量的投影。
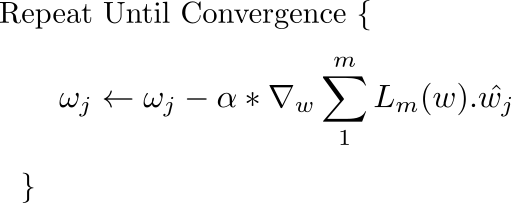
对所有权重同时进行此更新。
在减去之前,我们将梯度向量乘以学习速率。这代表了我们之前谈到的步骤。意识到即使我们保持学习速率不变,步长的大小也会因梯度的大小变化而变化,而损失轮廓的陡度也会变化。当我们接近最小值时,梯度接近零,我们朝着最小值采取越来越小的步骤。
从理论上讲,这很好,因为我们希望算法在接近最小值时采取较小的步骤。步长太大可能导致它超过最小值并在最小值的脊之间反弹。
梯度下降中广泛使用的技术是具有可变的学习速率,而不是固定的学习速率。最初,我们可以承受很高的学习率。但是后来,我们想要在接近最小值时放慢速度。实现此的策略方法称为模拟退火或衰减学习率。在此,学习速率在每个固定次数的迭代中衰减。主要采用的有动量学习法,AdaGrad和RMSProp,亚当,在下一节将详细探讨这些优化算法。
梯度下降的挑战之一:局部极小值
好吧,目前为止,梯度下降看起来是一个非常美好的童话。不过我要开始泼凉水了。还记得我之前说过,我们的损失函数是一个非常好的函数,这样的损失函数并不真的存在?
首先,神经网络是复杂函数,具有大量非线性变换。由此得到的损失函数看起来不像一个很好的碗,只有一处最小值可以收敛。实际上,这种圣人般的损失函数称为凸函数,而深度网络的损失函数几乎总是非凸的事实上,损失函数可能是这样的:
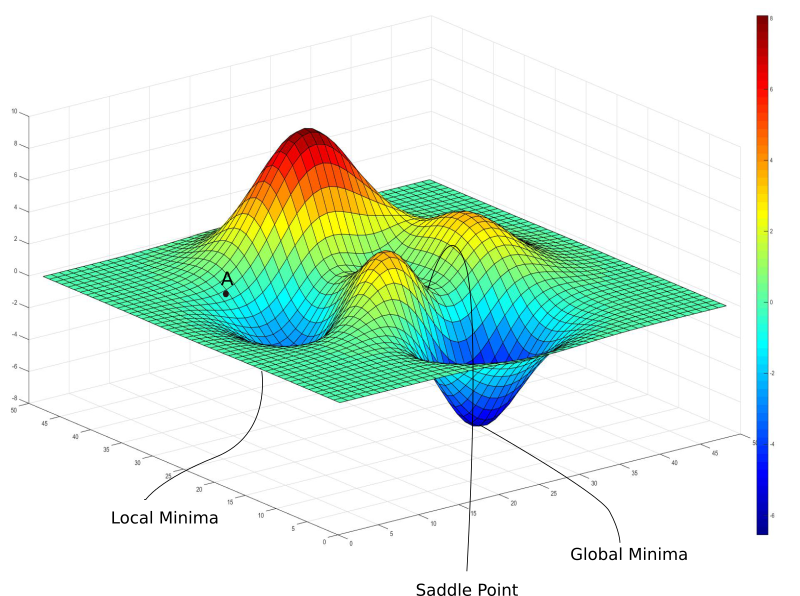
上图中有一个梯度为零的局部极小值。然而,我们知道那不是我们能达到的最低损失(全局最小值)。如果初始权重位于点A,那么我们将收敛于局部极小值,一旦收敛于局部极小值,梯度下降无法逃离这一陷阱。
梯度下降是由梯度驱动的,而梯度在任何极小值处都是零。局部极小值,顾名思义,是损失函数在局部达到最小值的点。而全局最小值,是损失函数整个定义域上可以达到的最小值。
让事情更糟的是,损失等值曲面可能更加复杂,实践中可没有我们考虑的三维等值曲面。实践中的神经网络可能有上亿权重,相应地,损失函数有上亿维度。在那样的图像上梯度为零的点不知道有多少。
事实上,可视化这样的高维函数很难。然而,因为现在有很多极具天赋的人从事深度学习研究,人们找到了以三维形式可视化损失函数的等值曲面的方法。最近的一篇论文提出了过过器归一化(Filter Normalization)技术,本文就不解释它的具体做法了。我们只要知道,它能够为我们提供呈现损失函数复杂性的视图。例如,下图表示VGG-56深度网络在CIFAR-10数据集上的损失函数:

正如您所看到的那样,损失情况与当地最小值相关。
梯度下降的挑战之二:鞍点
我们碰到的另一种问题是鞍点,看起来是这样的:
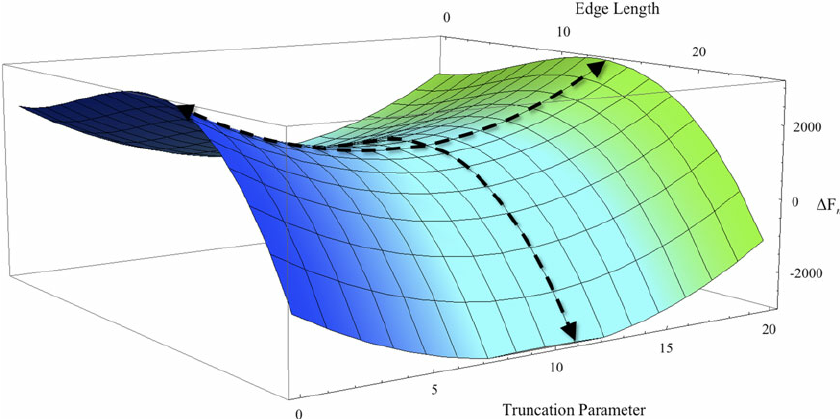
之前的图片中,双“峰”交汇处也有一个鞍点。
鞍点因形状像马鞍而得名。鞍点处,梯度在一个方向(X)上是极小值,在另一个方向上则是极大值。如果沿着X方向的等值曲面比较平,那么梯度下降会沿着Ÿ方向来回振荡,造成收敛于最小值的错觉。
梯度下降的挑战之三:梯度悬崖
多层神经网络还经常会有极度陡峭的区域,就如同悬崖一样,如下图所示(其中蓝色是损失值,绿色是梯度方向,载损失突变的时候也就是类似悬崖一样的,在那一点梯度会变化很大,导致直接飞出这个区域,在高维的情况下更复杂,可能直接跳出该区域,达到未知区域),高度非线性的神经网络或者循环神经网络,在参数空间中常常含有尖锐的非线性,这导致了某些区域可能会产生非常高的梯度。当参数靠近这一悬崖区域时,高梯度会将参数弹射到很远的地方,很可能导致原本的优化工作半途而废。
需要注意的是,由于循环神经网络涉及在多个时间段内相乘,因此梯度悬崖在递归神经网络中十分频繁,特别是处理较长的时序序列时,该问题更加突出,这里先给出这个概念,后面等讲完RNN后再给出解决方法。

梯度下降的挑战之四:梯度消失和梯度爆炸
这个将在下节详细介绍,这里为了完整性,列在这里。
梯度下降的挑战之五:梯度不精确
大多数优化算法最原始的动机都是试图获取代价函数对应的精确梯度,从而优化学习器。但在实践中,我们经常使用含有噪声的梯度进行优化。比如梯度下降法需要遍历所有训练数据后计算出平均梯度,然后才修改网络,但这种方法在数据较大时训练速度太慢,因此深度学习通常会进行数据采样,使用最小批量梯度下降学习方法进行网络训练,甚至在极端情况下还会使用随机梯度下降(一次采样一条数据)进行网络训练。这种不精确的梯度,也就导致了训练的稳定性较差,但梯度不精确有时也可以看作是防止过拟合以及逃离局部最优或鞍点的方法。机器学习终究不是一个最优化问题,但其却要依靠优化手段来完成机器学习任务。贝体问题,还需要根据实际需求进行思考。
梯度下降的挑战之六:优化理论的局限性
一些理论结果显示,很多针对神经网络而设计的优化算法有着局限性,但在实践中,这些理论结果却很少对神经网络产生影响。这也是相比于其他机器学习算法而言,神经网络更像是一个黑盒,神经网络中存在着大量的训练技巧,这也使得训练神经网络更像是艺术而非科学。
在神经网绍的训练中,我们通常不关心能否找到精确的全局最优解,我们仅仅是去降低代价函数的值,使其能够获得较好的泛化性能。但我们并不是不想获得全局最优解,只是理论分析神经网络算法是一个极其困难的任务。总而言之,深度学习是实践的产物,还缺乏强有力的理论支持,很多科研人员仍然对其保持着怀疑态度,如何理智地评估深度学习算法性能边界仍然是机器学习中一个重要的目标。
下面主要讲解前两个挑战即局部最优和鞍点,下面几节会着重讲解病态曲率(解决方法是SGD,动量(Momentum),AdaGrad,RMSProp,Adam),梯度消失,激活函数,批量标准化(批量标准化)归一化)
随机性是救星
所以,我们该如何逃离局部极小值和鞍点,努力收敛于全局最小值呢?答案是随机性。
目前为止,我们进行梯度下降时计算的损失函数累加了训练集中所有可能样本上的损失。如果我们碰到局部极小值或鞍点,我们便陷入其中。帮助梯度下降摆脱这些的一种方法是使用随机梯度下降。
随机梯度下降并不通过累加所有损失函数计算损失,而是计算随机取样(无放回)的样本的损失。与批量梯度下降不同,我们之前的方法在一个批次内处理所有样本,因此称为批量梯度下降。
相应地,随机梯度下降的更新规则为:
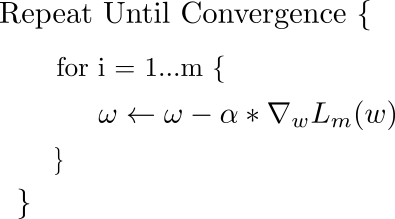
随机梯度下降的更新细则
基于“单样本损失”计算出的梯度,方向和基于“全样本损失”计算出的梯度可能略有不同。因此,当“全样本损失”可能将我们推入局部极小值,或让我们陷于鞍点时,“单样本损失”梯度可能指向不同的方向,也许能帮助我们避开局部极小值和鞍点。
即使我们陷入了“单样本损失”的局部极小值,下一个随机取样的数据点的“单样本损失”可能不一样,让我们得以继续移动。
当它真的收敛时,它收敛于根据几乎所有“单样本损失”计算得出的最小值。同时,经验表明,鞍点极为不稳定,小小的轻推可能就足以逃离鞍点。
所以,这是否意味着,在实践中,我们应该总是进行这样的单样本随机梯度下降?
批量大小
答案是否,尽管理论上,随机梯度下降也许能为我们提供最好的结果,从算力上看,它是一个不太可行的选项。随机梯度下降时,我们需要一步一步地计算损失,而在批量梯度下降时,单独损失的梯度可以并行计算。
因此,我们在这两种方法之间寻找一个平衡。我们既不使用整个数据集,也不仅仅基于单个样本构造损失函数,我们使用固定数量的样本,比如,16,32,128,这称为小批量。之所以称为小批量,是为了区别批量(批次)梯度下降。选择合适的小批量大小,可以确保我们既能有足够的随机性以摆脱局部极小值,又能充分利用并行处理的算力优势。
重新审视局部极小值:它们并没有你想像的那么糟糕
在你仇视局部极小值之前,先看下最近的研究吧。最近的研究表明,局部极小值并不一定不好。在神经网络的损失曲面上,有太多的极小值了“。良好”的局部极小值表现可能和全局最小值一样好。
为什么我说“良好”?因为我们仍然可能陷入难以预测的训练样本导致的“糟糕”的局部极小值。“良好”的局部极小值,文献中常称为最优局部极小值,在神经网络的高维损失函数中,可以有相当多个。
另外,许多神经网络进行的是分类任务。如果局部极小值对应的正确标签的分值在0.7-0.8之间,而同一样本全局最小值对应的正确标签的分值在0.95-0.98之间,最终得到的输出分类预测是一样的。
我们希望极小值具有的性质是它位于较平坦的一边。为什么?因为平坦极小值更容易收敛,跳过极小值,在极小值周围的“谷脊”反复回弹的概率更低。
更重要的是,预测集的损失曲面一般和训练集的略有不同。平坦宽阔的极小值,从训练集到预测集的切换不会改变太多损失,而狭窄的极小值则不然。更平坦的极小值推广性更好。
重新审视学习率
最近涌现了一堆学习率规划的研究,以避免收敛于损失曲面的次优极小值。即使使用学习率衰减,仍有可能陷入局部极小值。传统上,训练或者在固定数目的迭代之后结束,或者在损失没有改善的10个(比方说)迭代后结束(文献中称为及早停止)。
更高的学习率也有助于帮助我们在训练早期逃离局部极小值。
也有人组合了及早停止和学习率衰减,每次遇到10个损失没有改善的迭代,就降低学习率,并在学习率低于某个预订的阈值时停止训练。
近年来也曾流行周期学习率,缓慢增加学习率,然后降低学习率,循环往复。
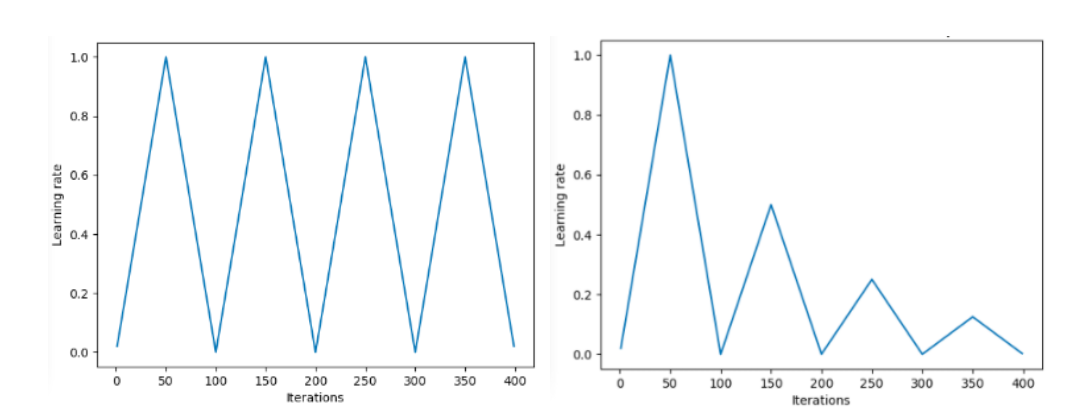
Leslie N. Smith提出的“三角”和“三角2”循环学习率方法。在左图中,min和max lr保持不变。在右边,每个周期后差异减半。图片来源:Hafidz Zulkifli
还有称为热重启随机梯度下降的技术,基本上就是学习率退火至下界后,还原学习率为原值。还有不同的学习率衰减的规划方案,从指数衰减到余弦衰减。
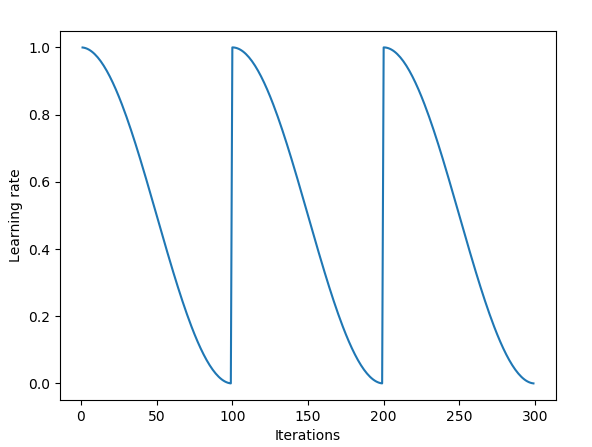
的队最近一篇]介绍]论文了一种称为随机权值平均的技术。作者开发了一种方法,它首先收敛到最小值,缓存权重,然后将学习率恢复到更高的值。然后,这种更高的学习速率将算法从最小值推进到损失表面中的随机点。然后使算法再次收敛到另一个最小值。这重复几次。最后,他们对所有缓存权重集的预测进行平均,以产生最终预测。
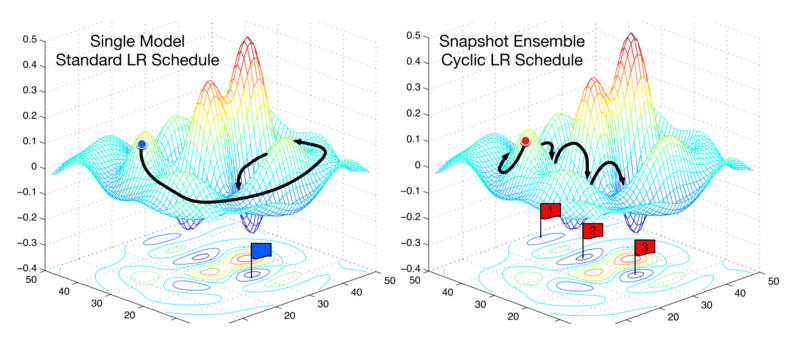
结语
梯度下降就介绍到这里了。不过我们还漏了一点没讲,如何应对病态曲率。随机梯度下降的一些扩展,如动量,RMSProp,亚当可以用来克服这一问题。
不过我觉得我们介绍的内容对一篇博客文章来说已经够多了,剩余的内容将在另一篇文章中介绍。
参考资料
-
可见化神经网络的损失曲面(论文):的arXiv:1712.09913
-
Hafidz Zulkifli关于学习率规划的文章:https://towardsdatascience.com/understanding-learning-rates-and-how-it-improves-performance-in-deep-learning-d0d4059c1c10
-
随机权重平均(论文):的arXiv:1704.00109
原文地址:HTTPS://blog.paperspace.com/intro-to-optimization-in-deep-learning-gradient-descent/
这里补充一下,这篇文章是从国外的论坛看到的,然后翻译过来,本来打算自己总结的,但是这篇文章太好了,很形象,因此就翻译过来,供以后自己查阅体会,同时了为了完整性,在原来的基础上,增添了其他的问题,使其更加完整,优化方法还有很多,相信以后的更新将更偏向于优化。特此说明。此外这是一系列文章,在此基础上我会根据本人的理解体系进程穿插知识。