一、概述
批量方法,例如有约束方法BFGS,它在每次迭代中使用全部训练集来计算参数的下一次更新,这类方法很好地收敛于局部最优解。它们在框架实现下(例如minFunc)也能直接得到好的结果,因为它们几乎不用调整多少超参数。然而,在全部训练集上计算代价和导数在实践中经常运行很慢,而且有时候数据集太大,内存不足变得很难处理。批量优化方法的另一个问题是它在“在线”模式下难以加入新的数据。随机梯度下降(SGD)能解决这些问题,只通过单个的或一部分训练集来得到目标函数的负梯度。SGD在神经网络模式下的使用是由于在全部训练集上运行反向传播的高成本而产生的。SGD能解决这种成本问题,而且仍能较快地收敛。
二、随机梯度下降
标准的梯度下降算法更新目标函数J(θ)的参数θ,用:
θ=θ−α∇θE[J(θ)]
上面等式的期望值是在全部训练集上评价的近似值。随机梯度下降(SGD)仅仅以期望值条件下更新,并只使用单个的或一部分训练样本计算参数的梯度。新一轮的更新为:
θ=θ−α∇θJ(θ;x(i),y(i))
(x(i),y(i))来自训练集。
通常SGD中每一次参数更新是利用一部分训练样本或是小批量样本计算的,而不是用单个样本。原因是双方面的:第一,这种方法减少了参数更新的方差,并能得到更稳定的收敛。其次,该方法能利用高度优化的矩阵运算进行计算,用于代价函数和梯度的向量化计算。典型的小批量大小为256,尽管该大小的最优值随着不同的应用和结构而改变。
在SGD中,一般学习率比在批量梯度下降中的学习率小很多,因为在更新过程中的方差大很多。选择一个合适的学习率和方法(即,随着学习的进程而改变学习率的的值)非常困难。实际中能取得好的效果的一种标准方法是在最初阶段(遍历一个训练集)或者两次训练阶段使用一个足够小的常数作为学习率,使得到稳定的收敛,然后随着收敛慢下来,学习率的值减半。更好的一种方法是,在每个阶段后评价使用的数据集,并当每个阶段目标函数的变化小于一个小的阈值的时候减小学习率。这往往能很好地收敛到局部最优。另一种常用的方法是在每次迭代t以a/(b+t)减小学习率,其中a和b分别表示初始学习率和开始减小学习率的时间。更复杂的方法包括回溯线搜索方法来寻找最优更新。
关于SGD最后一点但是很重要的一点是我们将数据输入给算法的顺序。如果所给数据的顺序是有意义的,会使(算得的)梯度产生偏差并得到很差的收敛性。通常一个好避免的方法是在训练的每个阶段前对数据随机洗牌。
三、动量
如果目标函数(平面)通往最优值方向是一条长的浅沟而在边沿是峭壁,标准的SGD往往沿着浅沟振荡,因为负梯度会指向其中一个陡峭方向,而不是沿着通往最优值的沟的方向。深度结构的目标函数在局部最优值附近会有这种形式的平面,故标准的SGD会导致收敛地非常慢,尤其从第一个峭壁开始。动量是一种方法用来促使目标函数更快地沿着浅沟的方向走。动量更新形式如下:
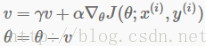
在上面的等式中,v是当前的速度向量,和参数向量θ是相同维度。学习率a正如上式描述,尽管使用动量,a需要更小一点因为梯度的数量级会比较大。最后γ∈(0,1]决定了前面多少个梯度迭代会参与到到此次更新中。通常γ设置为0.5,直到最初的学习稳定下来后可以增加到0.9甚至更高。