前言:最近参加百度点石大赛,完成商家招牌的分类和检测,把实验过程简单记录下来,具体步骤如下。
环境配置:windows下的visual studio2013和caffe(cpu版本)环境搭建请看我另一篇博客:http://www.cnblogs.com/wmr95/articles/9021748.html
下面写写具体实验流程:
1.首先把比赛平台下的数据集下载放到caffe-master路径下data文件夹中,如图:

首先数据提供的是train和test图片数据及label的txt文件,具体如图所示:
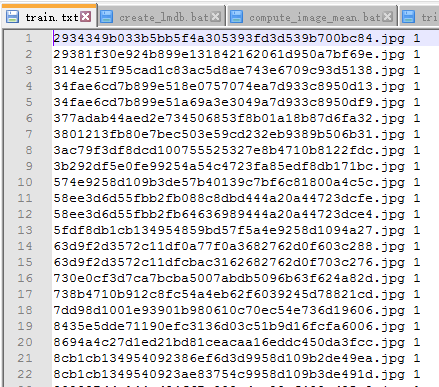
其中train文件夹下的图片和train.txt中的内容如图:
2.接下来根据图片和label信息得到lmdb格式文件train_lmdb新建一个create_lmdb.bat 文件,内容为:
E:\caffe-master\Build\x64\Release\convert_imageset.exe --resize_height=128 --resize_width=128 --shuffle --backend="lmdb" E:\caffe-master\data\signboard\train\ E:\caffe-master\data\signboard\train.txt train_lmdb pause
简单解释一下,第一个显然是你编译好的caffe中的exe工具,第二和第三指定对图像进行resize(因为原图大小尺寸不一),第四个是shuffle参数,随机打乱一下label的txt列表,第六个--backend指定生成lmdb格式(还可以指定为leveldb,另外一种格式),第七个指定train文件夹下的图片,第八个指定train的label信息,最后一个指定得到的train_lmdb(这个不能添加路径,由程序自己创建文件夹,如果提前有这个文件夹会报错)。
执行成功截图:
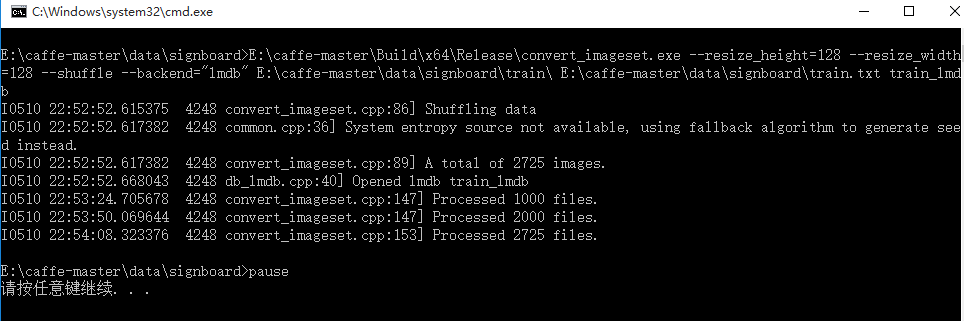 在当前路径下得到train_lmdb文件,如图所示:
在当前路径下得到train_lmdb文件,如图所示:

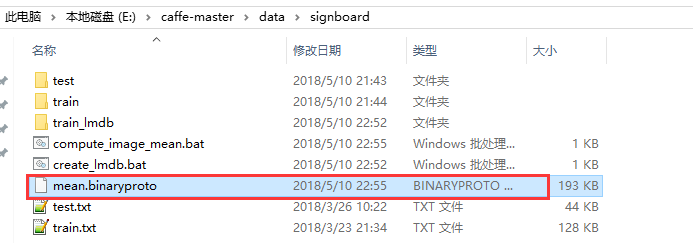
3.根据得到的lmdb格式文件train_lmdb得到均值文件
新建一个compute_image_mean.bat文件,代码内容为:
E:\caffe-master\Build\x64\Release\compute_image_mean.exe E:\caffe-master\data\signboard\train_lmdb mean.binaryproto
pause
具体意思大概看下就了解,不具体解释了。运行成功截图为:

在当前路径下得到的mean.binaryproto文件为:
4.接下来就准备网络模型的事情了(简单举个例子,我这里先采用的是cifar10的网络,接下来以这个为例)
先将examples下的cifar10拷贝一份命名为signboard,这里主要用到两个prototxt文件:
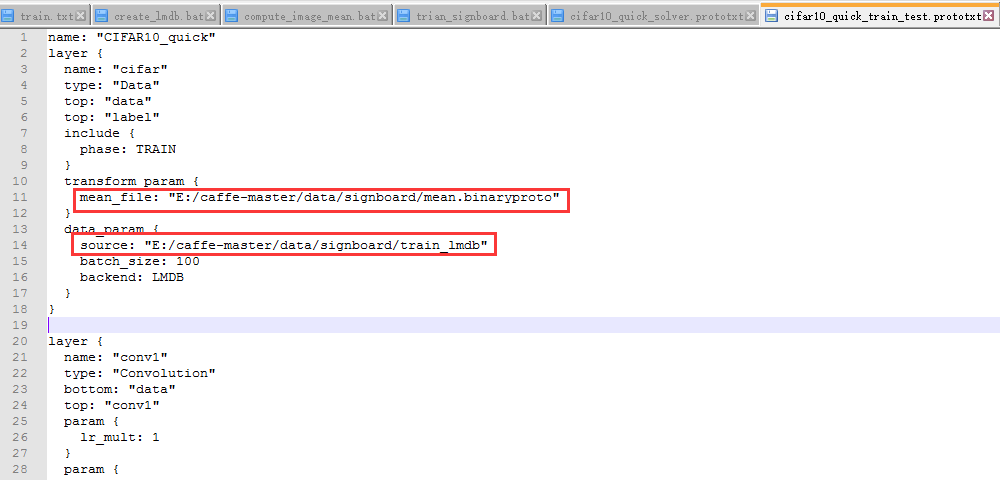
train_test.prototxt的内容需要做修改:(mean_file和source需要指定路径,另外我们是进行100分类,最后的output由10改为100)
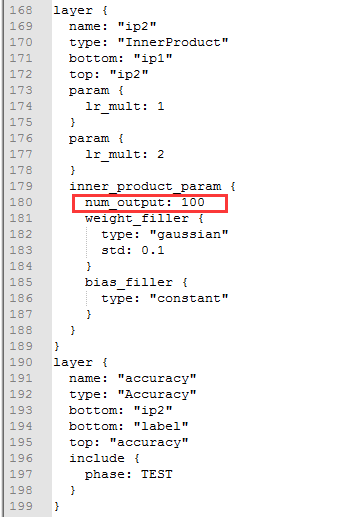
这里需要注意,因为我们没有得到test_lmdb文件,这里需要把phase的TEST部分删除,只留下TRAIN部分。
然后再修改solver.prototxt文件:
因为训练过程中不包含测试集,所以这里需要把test部分注释,否则会出现“Unknown bottom blob 'data' (layer 'conv1',bottom index 0)”的错误。

错误截图为:

5.完成数据处理和网络模型后,就可以进行训练模型了,在caffe-master根目录下新建一个trian_signboard.bat文件,代码内容为:
.\Build\x64\Release\caffe.exe train --solver=.\examples\signboard\cifar10_quick_solver.prototxt
pause
在caffe-master根目录下执行这个.bat文件就可以训练了,开心的飞起~~训练过程截图为:
这只是初步的把分类实验跑起来,后期打算做数据增强和finetune操作。期待竞赛有个好成绩~~