从2012年的Alexnet夺得 ILSVRC 2012冠军开始,CNN在图像识别领域层出不穷,出现了各种各样的网络架构,但是近年来都是依靠增加网络的深度和广度来提高准确率的,需要大量的使用GPU。但是要注意的是,这些在学术上的成就并不能应用到现实中,因为计算资源需求太高,而现实中的设备并没有这么强的算力。因此,作者提出了一种轻量级的CNN,大大减少了计算量,可以应用于手持设备上。
下面我们直奔主题,看看mobilenet的体系结构,分析下为何它能够实现轻量级,少计算吧!
其实,文章的核心思想挺简单,就是分解卷及操作。
一、深度可分卷积
MobileNet模型基于深度可分卷积(depthwise separable
convolution),这是一种分解卷积的形式,将标准卷积分解成深度卷积(depthwise convolution)和被称为点卷积(pointwise convolution)的1x1卷积。
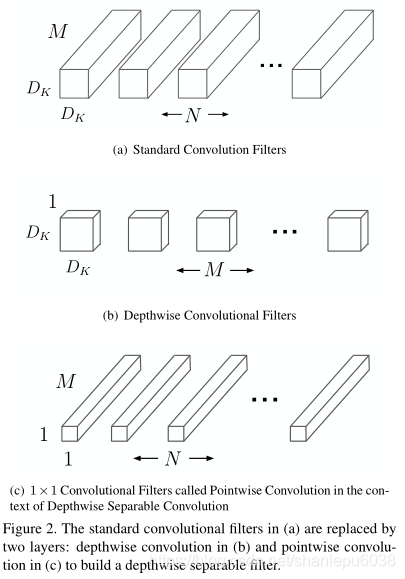
下图显示了深度可分卷积的主要原理:
-
首先,(a)表示了标准的卷积:对于HxWxM的feature map(通常H=W,M为通道数),有N个Dk xDk xM的过滤器来进行卷积操作
-
(b)和(c)一起表示了深度可分卷积的处理步骤:
明确一点:feature map是由M层HxW大小的特征图堆叠起来的。
首先,filter的深度为1,也就是每个过滤器都作用在feature map的一层上,而不是和标准卷积那样每个过滤器作用于所有通道,因此需要M个filter,这一步的处理影响了最后的feature map的size大小
其次,用N个1x1xM的filter作用于b的输出上,这是对所有通道上特征的融合,这一步的处理影响了最后的feature map的深度
好了,经过b和c的处理,最终的结果和标准卷积差不多了。
上述说明对照到原文这一段:

二、mobilenet architecture
下图是文中给出的mobilenet的结构。
其中,需要注意的是,第一层卷积是标准卷积,其余的都是深度可分卷积构成的,最后连接了平均池化层和FC层以及softmax层

另外,为了加速收敛,作者也采取了batch normalization。值得注意的是,在每层的depthwise convolution和1x1convolution后,都需要进行BN和relu操作。

三、减少计算量的原理
这一段自然是一些数学表达:
标准卷积层的计算量如下图所示。我们来简单理解一下这个式子。
首先,input是DF x DF x M , filter是DK x DK x M x N ,一个filter的计算量应该是 DK x DK x DF x DF x M(假设通过padding的方式使得输出size和输入size一样,stride=1),那么有N个filter,自然得到下列式子:
DK x DK x DF x DF x M x N

深度可分卷积的计算量如下:
这里说的很清楚了,不多解释

那么有,两个计算量之比为:
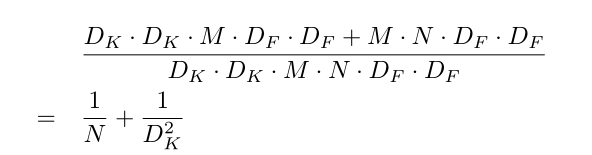
由于N通常比DK大很多,所以可以近似舍去,也就是说,如果我们采用3x3大小的卷积,能够减少9倍的计算量。
四、超参数的选择
上面给定的网络结构其实也不小,那么如果想再精简一些,该如何做呢?
一个想当然的想法是,我能不能再减少一些堆叠呢?很显然,是可以的。
这里作者给出了两个超参数用于精简模型和减少计算:
Width Multiplier: Thinner Models
Resolution Multiplier: Reduced Representation
下面我们一一介绍:
-
Width Multiplier: Thinner Models
设宽度乘数width multiplier为alpha,宽度乘数的作用是在每一层均匀地使网络变薄,因此对于一个给定的层和宽度乘数alpha,输入通道数M就成了alpha x M , 输出通道数N就成了alpha x N。
计算量就降为:
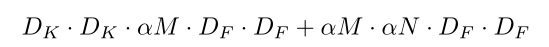
其中,0 < alpha <=1,且alpha一般取值为1, 0.75, 0.5, 0.25
不仅能减少计算量,参数量也可以减少,大概是原来的1 / (alpha)2 -
Resolution Multiplier: Reduced Representation
分辨率乘数Resolution Multiplier,记为p(应该是希腊字母rou)。
这个参数是用于缩减input的分辨率的,因此,输入DF x DF就变成了p x DF x p x DF,很显然,这个超参数只能减少计算量,而不能减少参数数量。
结合以上两个超参数,我们的计算量就有如下表达:
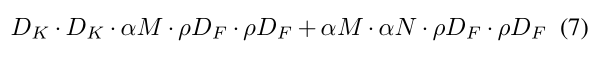
五、实验结果
下面奉上实验结果:
table4表明了标准卷机和深度可分卷积的差距:
准确率上深度可分卷积低1%,但是在运算量和参数数量上,根本不是一个数量级的。

table6-7表明了两个超参数的选择是精确度和检测速度的一种trade-off
