Pytorch 深度可分离卷积和MobileNet_v1
1.深度可分离卷积
深度可分离卷积提出了一种新的思路:对于不同的输入channel采取不同的卷积核进行卷积,它将普通的卷积操作分解为两个过程。
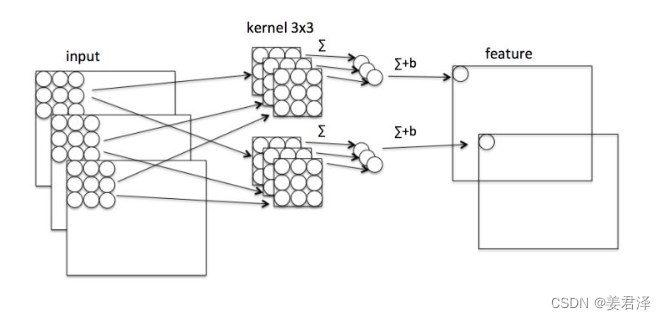
卷积过程
假设有 N × H × W × C N \times H \times W \times C N×H×W×C的输入,同时有 k 个 3 × 3 3 \times 3 3×3 的卷积。如果设置 pad=1 且 stride=1 ,那么普通卷积输出为 N × H × W × k N \times H \times W \times k N×H×W×k
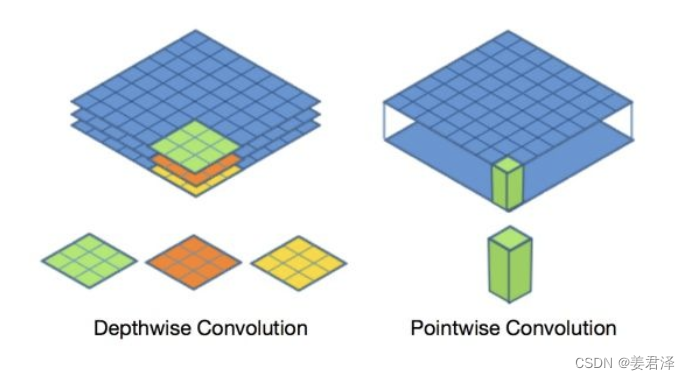
Depthwise 过程
Depthwise是指将 N × H × W × C N \times H \times W \times C N×H×W×C的输入分为 g r o u p = C group=C group=C 组,然后每一组做 3 × 3 3 \times 3 3×3 卷积。这样相当于收集了每个Channel的空间特征,即Depthwise特征
Pointwise 过程
Pointwise是指对 N × H × W × C N \times H \times W \times C N×H×W×C 的输入做 k 个普通的 1 ∗ 1 1*1 1∗1 卷积。这样相当于收集了每个点的特征,即Pointwise特征。Depthwise+Pointwise最终输出也是 N × H × W × k N \times H \times W \times k N×H×W×k
2.优势创新
Depthwise+Pointwise可以近似看作一个卷积层:
- 普通卷积:3x3 Conv+BN+ReLU
- Mobilenet卷积:3x3 Depthwise Conv+BN+ReLU 和 1x1 Pointwise Conv+BN+ReLU
计算加速
参数量降低
假设输入通道数为3,要求输出通道数为256,两种做法:
- 直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,912
- DW操作,分两步完成,参数量为:3×3×3+3×1×1×256 = 795(3个特征层*(3*3的卷积核)),卷积深度参数通常取为1
乘法运算次数降低
对比一下不同卷积的乘法次数:
- 普通卷积计算量为: H × W × C × k × 3 × 3 H\times W\times C\times k \times 3 \times3 H×W×C×k×3×3
- Depthwise计算量为: H × W × C × 3 × 3 H \times W \times C \times 3 \times 3 H×W×C×3×3
- Pointwise计算量为: H × W × C × k H \times W \times C \times k H×W×C×k
通过Depthwise+Pointwise的拆分,相当于将普通卷积的计算量压缩为:
d e p t h w i s e + p o i n t w i s e c o n v = H × W × C × 3 × 3 + H × W × C × k H × W × C × k × 3 × 3 = 1 k + 1 3 × 3 \frac{depthwise+pointwise}{conv}=\frac{H \times W \times C \times 3 \times 3+H \times W \times C \times k}{H \times W \times C \times k \times 3 \times 3}=\frac{1}{k}+\frac{1}{3 \times 3} convdepthwise+pointwise=H×W×C×k×3×3H×W×C×3×3+H×W×C×k=k1+3×31
通道区域分离
深度可分离卷积将以往普通卷积操作同时考虑通道和区域改变(卷积先只考虑区域,然后再考虑通道),实现了通道和区域的分离。
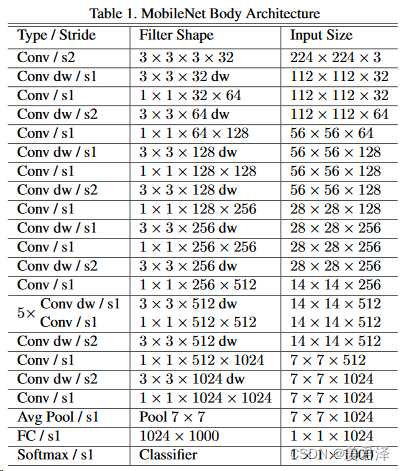
3.网络结构
Mobilenet v1利用深度可分离卷积进行加速,其架构如下
- 首先经过一个步长为2的3*3传统卷积层进行特征提取
- 接着通过一系列的深度可分离卷积(DW+PW卷积)进行特征提取
- 最后经过平均池化层、全连接层,以及经过softmax函数后得到最终的输出值。
pytorch实现
import torch
import torch.nn as nn
def conv_bn(in_channel, out_channel, stride = 1):
"""
传统卷积块:Conv+BN+Act
"""
return nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, stride, 1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
def conv_dsc(in_channel, out_channel, stride = 1):
"""
深度可分离卷积:DW+BN+Act + Conv+BN+Act
"""
return nn.Sequential(
nn.Conv2d(in_channel, in_channel, 3, stride, 1, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channel, out_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True),
)
class MobileNetV1(nn.Module):
def __init__(self,in_dim=3, num_classes=1000):
super(MobileNetV1, self).__init__()
self.num_classes = num_classes
self.stage1 = nn.Sequential(
conv_bn(in_dim, 32, 2),
conv_dsc(32, 64, 1),
conv_dsc(64, 128, 2),
conv_dsc(128, 128, 1),
conv_dsc(128, 256, 2),
conv_dsc(256, 256, 1),
)
self.stage2 = nn.Sequential(
conv_dsc(256, 512, 2),
conv_dsc(512, 512, 1),
conv_dsc(512, 512, 1),
conv_dsc(512, 512, 1),
conv_dsc(512, 512, 1),
conv_dsc(512, 512, 1),
)
self.stage3 = nn.Sequential(
conv_dsc(512, 1024, 2),
conv_dsc(1024, 1024, 1),
)
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(1024, self.num_classes)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.avg(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x