1. 谈谈你对java平台的理解
- 首先是java最显著的两个特性,一次写入处处运行;还有垃圾收集器gc,gc能够对java内存进行管理回收,程序员不需要关心内存的分配和回收问题
- 然后谈谈jre和jdk的区别,jre包含了jvm和java类库;jdk除了jvm和java类库,还包含了一些java工具集
- 常见的垃圾收集器有:
- Serial GC:串行收集,垃圾回收时会阻塞工作线程
- Parallel GC:并行收集,多线程收集,停顿时间短,吞吐量高
- CMS:使用标记清除算法,多线程进行垃圾收集
- G1:吸收了CMS的优点,将堆划分为多个连续的区域,进行多线程收集。区域间采用复制算法,整体采用标记整理算法,避免内存碎片
- 垃圾收集器特点
- Serial收集器:串行运行;作用于新生代;复制算法;响应速度优先;适用于单CPU环境下的client模式。
- ParNew收集器:并行运行;作用于新生代;复制算法;响应速度优先;多CPU环境Server模式下与CMS配合使用。
- Parallel Scavenge收集器:并行运行;作用于新生代;复制算法;吞吐量优先;适用于后台运算而不需要太多交互的场景。
- Serial Old收集器:串行运行;作用于老年代;标记-整理算法;响应速度优先;单CPU环境下的Client模式。
- Parallel Old收集器:并行运行;作用于老年代;标记-整理算法;吞吐量优先;适用于后台运算而不需要太多交互的场景。
- CMS收集器:并发运行;作用于老年代;标记-清除算法;响应速度优先;适用于互联网或B/S业务。
- G1收集器:并发运行;可作用于新生代或老年代;标记-整理算法+复制算法;响应速度优先;面向服务端应用
- .class文件在JVM中,进行的是解析或编译运行,JVM会对.class文件进行解析运行,同时JVM中存在JIT编译器,会对字节码文件进行编译预热,热点代码会编译优化成机器码执行
2. Exception和Error
- Exception是异常,Error是错误,异常可以捕获处理,错误不需要处理
- try-catch尽量包裹需要包裹的代码块,而不是全部
- Exception捕获尽量细化,不要直接捕获Exception
3. 强引用、软引用、弱引用、幻象引用有什么区别
- 强引用:最常见的引用,我们平时Object obj = new Object(),产生的引用都是强引用,只有在没有引用关系或obj = null的时候会被垃圾收集器收集
- 软引用:当内存不够的时候,会优先回收软引用的对象,平时的用法和强引用一样
- 弱引用:生命周期比软引用短,当垃圾收集器扫描到弱引用对象时,就会被回收
- 虚引用(幻象引用):无法通过引用获取对象属性,通常用来监视对象是否被回收
4. 谈谈Java反射机制,动态代理是基于什么原理?
- 动态代理可以用反射实现,比如jdk自身提供的动态代理
- 也可以利用字节码操作机制,cglib(基于asm)
5. Java提供了哪些IO方式? NIO如何实现多路复用?
- 由于nio实际上是同步非阻塞io,是一个线程在同步的进行事件处理,当一组channel处理完毕以后,去检查有没有又可以处理的channel。这也就是同步+非阻塞。同步,指每个准备好的channel处理是依次进行的,非阻塞,是指线程不会傻傻的等待读。只有当channel准备好后,才会进行。
- 当每个channel所进行的都是耗时操作时,由于是同步操作,就会积压很多channel任务,从而完成影响。那么就需要对nio进行类似负载均衡的操作,如用线程池去进行管理读写,将channel分给其他的线程去执行,这样既充分利用了每一个线程,
- nio不适合数据量太大交互的场景
6. IO和NIO拷贝的效率问题
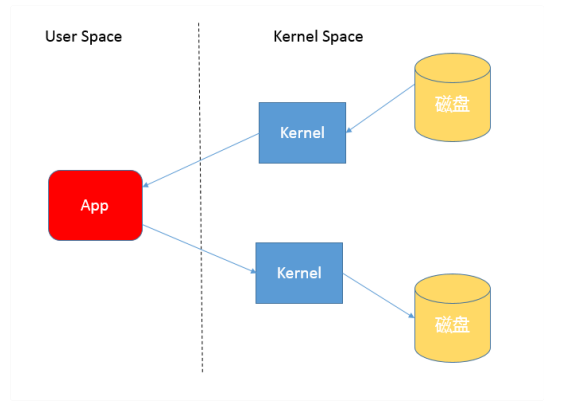
- 你需要理解用户态空间(User Space)和内核态空间(Kernel Space),这是操作系统层面的基本概念,操作系统内核、硬件驱动等运行在内核态空间,具有相对高的特权;而用户态空间,则是给普通应用和服务使用。
当我们使用输入输出流进行读写时,实际上是进行了多次上下文切换,比如应用读取数据时,先在内核态将数据从磁盘读取到内核缓存,再切换到用户态将数据从内核缓存读取到用户缓存。所以,这种方式会带来一定的额外开销,可能会降低IO效率。
- 而基于NIO transferTo的实现方式,在Linux和Unix上,则会使用到零拷贝技术,数据传输并不需要用户态参与,省去了上下文切换的开销和不必要的内存拷贝,进而可能提高应用拷贝性能。注意,transferTo不仅仅是可以用在文件拷贝中,与其类似的,例如读取磁盘文件,然后进行Socket发送,同样可以享受这种机制带来的性能和扩展性提高。
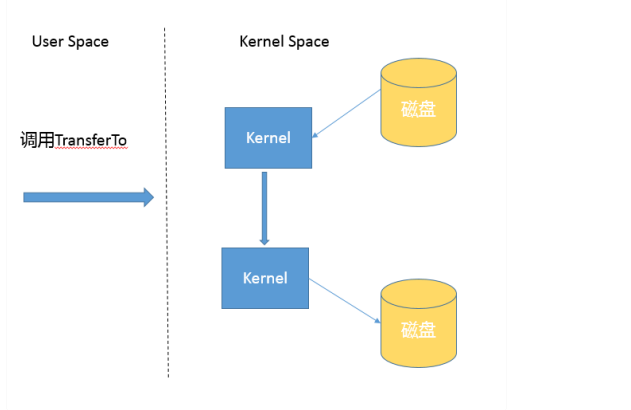
零拷贝可以理解为内核态空间与磁盘之间的数据传输,不需要再经过用户态空间
7. 谈谈你知道的设计模式?请手动实现单例模式,Spring等框架中使用了哪些模式?
- 设计模式可分为三种类型,创建型、结构型和行为型
- 创建型例如:单例,工厂,建造者
- 结构型例如:适配器,装饰器,代理模式等
- 行为型例如:观察者,模板模式,命令模式
- Spring中比较明显的有BeanFactory工厂模式,AOP代理模式,jdbcTemplate模板模式,各种监听器Listener,观察者模式
8. Java并发包提供了哪些并发工具类?
- 提供了比synchronized更加高级的各种同步结构,包括CountDownLatch、CyclicBarrier、Semaphore等,可以实现更加丰富的多线程操作,比如利用Semaphore作为资源控制器,限制同时进行工作的线程数量。
- 各种线程安全的容器,比如最常见的ConcurrentHashMap、有序的ConcunrrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。
- 各种并发队列实现,如各种BlockedQueue实现,比较典型的ArrayBlockingQueue、 SynchorousQueue或针对特定场景的PriorityBlockingQueue等。
- 强大的Executor框架,可以创建各种不同类型的线程池,调度任务运行等
9. 并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
- Concurrent类型基于lock-free,在常见的多线程访问场景,一般可以提供较高吞吐量
- 而LinkedBlockingQueue内部则是基于锁,并提供了BlockingQueue的等待性方法。
- Concurrent类型没有类似CopyOnWrite之类容器相对较重的修改开销。
- 但是,凡事都是有代价的,Concurrent往往提供了较低的遍历一致性。你可以这样理解所谓的弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历
- 与弱一致性对应的,就是同步容器常见的行为“fast-fail”,也就是检测到容器在遍历过程中发生了修改,则抛出ConcurrentModifcationException,不再继续遍历。
- 弱一致性的另外一个体现是,size等操作准确性是有限的,未必是100%准确
- 与此同时,读取的性能具有一定的不确定性
10. Java并发类库提供的线程池有哪几种? 分别有什么特点?
- Executors目前提供了5种不同的线程池创建配置
- newCachedThreadPool(),它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过60秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用SynchronousQueue作为工作队列
- newFixedThreadPool(int nThreads),重用指定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有nThreads个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目nThreads。
- newSingleThreadExecutor(),它的特点在于工作线程数目被限制为1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目
- newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize),创建的是个ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程。
- newWorkStealingPool(int parallelism),这是一个经常被人忽略的线程池,Java 8才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
- 线程数大致计算 线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)
11. 谈谈JVM内存区域的划分,哪些区域可能发生OutOfMemoryError?
- 程序计数器(PC,Program Counter Register)。在JVM规范中,每个线程都有它自己的程序计数器,并且任何时间一个线程都只有一个方法在执行,也就是所谓的当前方法。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者,如果是在执行本地方法,则是未指定值(undefned)。
- Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用。
前面谈程序计数器时,提到了当前方法;同理,在一个时间点,对应的只会有一个活动的栈帧,通常叫作当前帧,方法所在的类叫作当前类。如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,成为新的当前帧,一直到它返回结果或者执行结束。JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈。
栈帧中存储着局部变量表、操作数(operand)栈、动态链接、方法正常退出或者异常退出的定义等。
- 堆(Heap),它是Java内存管理的核心区域,用来放置Java对象实例,几乎所有创建的Java对象实例都是被直接分配在堆上。堆被所有的线程共享,在虚拟机启动时,我们指定的“Xmx”之类参数就是用来指定最大堆空间等指标。
理所当然,堆也是垃圾收集器重点照顾的区域,所以堆内空间还会被不同的垃圾收集器进行进一步的细分,最有名的就是新生代、老年代的划分。 - 方法区(Method Area)。这也是所有线程共享的一块内存区域,用于存储所谓的元(Meta)数据,例如类结构信息,以及对应的运行时常量池、字段、方法代码等。
由于早期的Hotspot JVM实现,很多人习惯于将方法区称为永久代(Permanent Generation)。Oracle JDK 8中将永久代移除,同时增加了元数据区(Metaspace) - 本地方法栈(Native Method Stack)。它和Java虚拟机栈是非常相似的,支持对本地方法的调用,也是每个线程都会创建一个。在Oracle Hotspot JVM中,本地方法栈和Java虚拟机栈是在同一块儿区域,这完全取决于技术实现的决定,并未在规范中强制

- 两点区别
- 直接内存(Direct Memory)区域,它就是Direct Bufer所直接分配的内存,也是个容易出现问题的地方。尽管,在JVM工程师的眼中,并不认为它是JVM内部内存的一部分,也并未体现JVM内存模型中。
- JVM本身是个本地程序,还需要其他的内存去完成各种基本任务,比如,JIT Compiler在运行时对热点方法进行编译,就会将编译后的方法储存在Code Cache里面;GC等功能需要运行在本地线程之中,类似部分都需要占用内存空间。这些是实现JVM JIT等功能的需要,但规范中并不涉及
- 除了程序计数器,其他区域都有可能会因为可能的空间不足发生OutOfMemoryError,简单总结如下:
- 堆内存不足是最常见的OOM原因之一,抛出的错误信息是“java.lang.OutOfMemoryError:Java heap space”,原因可能千奇百怪,例如,可能存在内存泄漏问题;也很有可能就是堆的大小不合理,比如我们要处理比较可观的数据量,但是没有显式指定JVM堆大小或者指定数值偏小;或者出现JVM处理引用不及时,导致堆积起来,内存无法释放等。
- 而对于Java虚拟机栈和本地方法栈,这里要稍微复杂一点。如果我们写一段程序不断的进行递归调用,而且没有退出条件,就会导致不断地进行压栈。类似这种情况,JVM实际会抛出StackOverFlowError;当然,如果JVM试图去扩展栈空间的的时候失败,则会抛出OutOfMemoryError。
- 对于老版本的Oracle JDK,因为永久代的大小是有限的,并且JVM对永久代垃圾回收(如,常量池回收、卸载不再需要的类型)非常不积极,所以当我们不断添加新类型的时
候,永久代出现OutOfMemoryError也非常多见,尤其是在运行时存在大量动态类型生成的场合;类似Intern字符串缓存占用太多空间,也会导致OOM问题。对应的异常信息,会标记出来和永久代相关:“java.lang.OutOfMemoryError: PermGen space”。 - 随着元数据区的引入,方法区内存已经不再那么窘迫,所以相应的OOM有所改观,出现OOM,异常信息则变成了:“java.lang.OutOfMemoryError: Metaspace”。直接内存不足,也会导致OOM
12. 如何监控和诊断JVM堆内和堆外内存使用?
- 可以使用综合性的图形化工具,如JConsole、VisualVM(注意,从Oracle JDK 9开始,VisualVM已经不再包含在JDK安装包中)等。这些工具具体使用起来相对比较直观,直接连接到Java进程,然后就可以在图形化界面里掌握内存使用情况
- 也可以使用命令行工具进行运行时查询,如jstat和jmap等工具都提供了一些选项,可以查看堆、方法区等使用数据。
- 或者,也可以使用jmap等提供的命令,生成堆转储(Heap Dump)文件,然后利用jhat或Eclipse MAT等堆转储分析工具进行详细分析。
- 如果你使用的是Tomcat、Weblogic等Java EE服务器,这些服务器同样提供了内存管理相关的功能。
- 另外,从某种程度上来说,GC日志等输出,同样包含着丰富的信息。
jdk自带实用工具 https://www.jianshu.com/p/36ac6403df44
- 为什么CMS两次标记时要 stop the world?
- 两次标记为了安全回收对象,虚拟机在特定的指令位置设置了“安全点”,当运行到该位置时,程序就会停顿,暂停当前运行的所有用户线程,进而进行标记清除
- 特定指令的位置:
- 循环末尾
- 方法返回前/调用方法call指令之后
- 可能抛异常的地方
13. 谈谈你的GC调优思路?
- 从性能的角度看,通常关注三个方面,内存占用(footprint)、延时
(latency)和吞吐量(throughput) - 基本的调优思路可以总结为:
- 确定调优目标,比如服务停顿严重,希望GC暂停尽量控制在200ms以内,并且保证一定标准的吞吐量
- 通过jstat等工具查看GC等相关状态,可以开启GC日志,或者是利用操作系统提供的诊断工具等
- 选择的GC类型是否符合我们的应用特征,如CMS和G1都是更侧重于低延迟的GC选项。
- 根据实际情况调整新生代老年代比例和大小等
- 思路归纳为:
- 选择合适的垃圾收集器;
- 使用jdk工具分析GC状况;
- 调整gc参数
14. Java内存模型中的happen-before是什么?
- Happen-before关系,是Java内存模型中保证多线程操作可见性的机制
- 它的具体表现形式,包括但远不止是我们直觉中的synchronized、volatile、lock操作顺序等方面,例如:
- 线程内执行的每个操作,都保证happen-before后面的操作,这就保证了基本的程序顺序规则,这是开发者在书写程序时的基本约定。
- 对于volatile变量,对它的写操作,保证happen-before在随后对该变量的读取操作。
- 对于一个锁的解锁操作,保证happen-before加锁操作。
- 对象构建完成,保证happen-before于fnalizer的开始动作。
- 甚至是类似线程内部操作的完成,保证happen-before其他Thread.join()的线程等。
15. Java程序运行在Docker等容器环境有哪些新问题?
- Docker其内存、CPU等资源限制是通过CGroup(Control Group)实现的,早期的JDK版本(8u131之前)并不能识别这些限制,进而会导致一些基础问题:
- 如果未配置合适的JVM堆和元数据区、直接内存等参数,Java就有可能试图使用超过容器限制的内存,最终被容器OOM kill,或者自身发生OOM。
- 错误判断了可获取的CPU资源,例如,Docker限制了CPU的核数,JVM就可能设置不合适的GC并行线程数等
- 从应用打包、发布等角度出发,JDK自身就比较大,生成的镜像就更为臃肿,当我们的镜像非常多的时候,镜像的存储等开销就比较明显了
- 虽然看起来Docker之类容器和虚拟机非常相似,例如,它也有自己的shell,能独立安装软件包,运行时与其他容器互不干扰。但是,如果深入分析你会发现,Docker并不是一种完全的虚拟化技术,而更是一种轻量级的隔离技术。
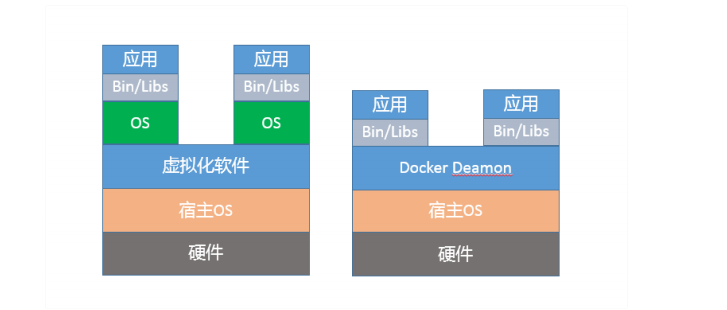
- 容器虽然省略了虚拟操作系统的开销,实现了轻量级的目标,但也带来了额外复杂性,它限制对于应用不是透明的,需要用户理解Docker的新行为。
针对这种情况,JDK 9中引入了一些实验性的参数,以方便Docker和Java“沟通”,例如针对内存限制,可以使用下面的参数设置
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap如果你可以切换到JDK 10或者更新的版本,问题就更加简单了。Java对容器(Docker)的支持已经比较完善,默认就会自适应各种资源限制和实现差异。前面提到的实验性参
数“UseCGroupMemoryLimitForHeap”已经被标记为废弃。与此同时,新增了参数用以明确指定CPU核心的数目。-XX:ActiveProcessorCount=N
- 如果实践中发现有问题,也可以使用“-XX:-UseContainerSupport”,关闭Java的容器支持特性
- 如果只能使用老版本
- 明确设置堆、元数据区等内存区域大小,保证Java进程的总大小可控
- 能在环境中,这样限制容器内存:
- $ docker run -it --rm --name yourcontainer -p 8080:8080 -m 800M repo/your-java-container:openjdk
- 额外配置下面的环境变量,直接指定JVM堆大小。
- -e JAVA_OPTIONS='-Xmx300m'
- 明确配置GC和JIT并行线程数目,以避免二者占用过多计算资源。
- -XX:ParallelGCThreads -XX:CICompilerCount
- 建议配置下面参数,明确告知JVM系统内存限额。
- -XX:MaxRAM=
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
- -XX:MaxRAM=
- 也可以指定Docker运行参数,例如:
- --memory-swappiness=0
16. 你了解Java应用开发中的注入攻击吗?
- 注入式(Inject)攻击是一类非常常见的攻击方式,其基本特征是程序允许攻击者将不可信的动态内容注入到程序中,并将其执行,这就可能完全改变最初预计的执行过程,产生恶意效果
- 最常见的SQL注入攻击。一个典型的场景就是Web系统的用户登录功能,根据用户输入的用户名和密码,我们需要去后端数据库核实信息。
- 假设应用逻辑是,后端程序利用界面输入动态生成类似下面的SQL,然后让JDBC执行。
Select * from use_info where username = "input_usr_name" and password = "input_pwd"但是,如果我输入的input_pwd是类似下面的文本
" or ""="那么,拼接出的SQL字符串就变成了下面的条件,OR的存在导致输入什么名字都是复合条件的。
Select * from use_info where username = “input_usr_name” and password = “” or “” = “”- 第二,操作系统命令注入。
- 第三,XML注入攻击。
- 解决方法,例如针对SQL注入:
- 在数据输入阶段,填补期望输入和可能输入之间的鸿沟。可以进行输入校验,限定什么类型的输入是合法的,例如,不允许输入标点符号等特殊字符,或者特定结构的输入。
- 在Java应用进行数据库访问时,如果不用完全动态的SQL,而是利用PreparedStatement,可以有效防范SQL注入。不管是SQL注入,还是OS命令注入,程序利用字符串拼接
生成运行逻辑都是个可能的风险点! - 在数据库层面,如果对查询、修改等权限进行了合理限制,就可以在一定程度上避免被注入删除等高破坏性的代码。
17. 后台服务出现明显“变慢”,谈谈你的诊断思路?
- 理清问题的症状,这更便于定位具体的原因,有以下一些思路:
- 问题可能来自于Java服务自身,也可能仅仅是受系统里其他服务的影响。初始判断可以先确认是否出现了意外的程序错误,例如检查应用本身的错误日志。
- 监控Java服务自身,例如GC日志里面是否观察到Full GC等恶劣情况出现,或者是否Minor GC在变长等;利用jstat等工具,获取内存使用的统计信息也是个常用手段;利用jstack等工具检查是否出现死锁等
- 如果还不能确定具体问题,对应用进行Profling也是个办法,但因为它会对系统产生侵入性,如果不是非常必要,大多数情况下并不建议在生产系统进行。
- 大致可以分几个方面检查
- 系统异常报错
- JVM配置不合理或内存不够,FULL gc频繁
- 检查变慢接口具体代码,可能由于数据量增多,sql没有优化查询变慢
- 调用第三方接口变慢