第9讲 对比Hashtable、HashMap、TreeMap有什么不同?
一、主要不同点
| 数据结构 | 底层实现 | 线程安全 | 性能 | 支持null键值 |
|---|---|---|---|---|
| HashTable | 基于哈希表 | 是 | put/get/remove-o(1) | 不支持 |
| HashMap | 基于哈希表 | 否 | put/get/remove-o(1) | 支持 |
| TreeMap | 基于红黑树 | 否 | put/get/remove-o(log n) | 不支持null键,支持null值 |
| ConcurrentHashMap | 锁分段技术 | 是 | 并发环境下优于同步版本的集合 | 不支持 |
第14讲 谈谈你知道的设计模式?
一、按照模式的应用目标分类
- 创建型模式,解决对象创建的各种问题,如工厂、单例、构建器(Builder)、原型;
- 结构型模式,是对软件设计结构的总结,关注于类、对象继承、组合方式的实践经验,如装饰者、外观、组合、适配器、桥接、代理;
- 行为型模式,是从类和对象之间交互、职责划分等方面总结的模式,如策略、观察者、命令、迭代器、模板方法、访问者。
二、JDK中典型应用
JDK的IO框架运用了装饰者模式(特征:一系列的类以相同的抽象类或者接口作为其构造函数的入参)。如:InputStream <- FilterInputStream <- BufferedInputStream。
GUI、Swing等的组件事件监听,运用了观察者模式。
新版JDK中HTTP/2 Client API,创建HttpRequest,运用了构建器模式,通常被实现成fluent风格的API,也叫方法链。
三、Spring中的应用
- BeanFactory和ApplicationContext应用了工厂模式
- 在bean的创建过程中,spring为不同scope定义的的对象,提供了单例和原型等模式实现
- AOP里应用了装饰者、代理、适配器模式
- 各种事件监听器,是典型的观察者模式
- 类似JdbcTemplate运用了模板模式
第15讲 synchronized和ReentrantLock有什么区别呢?
一、两者的区别
- synchronized是JDK1.5之前仅有的同步手段
- 前者可以用来修饰方法和代码块,后者通过对象调用lock和unlock等方法的形式来使用,书写更为灵活
- 可再入的意思就是,一个线程如果已经获取并正持有这个锁,再次获取时可以直接成功,这意味着获取锁的粒度是线程,而不是方法调用。java锁实现强调可再入性,就是为了跟pthread(POSIX线程)的行为进行区分
- 后者可以实现公平性(fairness),但是公平性在很多场景下并不是很有必要,反而会引入额外开销,造成吞吐量的下降
- 后者可以利用定义条件
- 两者的性能不能一概而论,早期版本synchronized在大部分场景下性能更差,后续版本做了很多改进,在低竞争场景中表现可能优于ReentrantLock。
二、什么是线程安全
线程安全是一个多线程环境下正确性的概念,即要维持多线程环境下共享的、可修改的状态的正确性。因此可以通过封装状态,或者让状态不可变(final, immutable)来保证状态的线程安全。
线程安全需要保证几个基本特性:
- 原子性,相关的操作之间,某个操作不会中途被另外的线程干扰,一般通过同步机制实现
- 可见性,对某个共享状态的修改,可以立即被其他线程感知到,通常被解释为将线程的本地状态反映到主内存上,volatile就是用于保证变量的可见性
- 有序性,指保证线程的串行语义,底层指令不会被重排序
三、锁的使用
为了保证锁的正确释放,每一个lock()方法后最好接一个try-catch-finally块:
lockObj.lock();
try {
// do something
...
} finally {
lockObj.unlock();
}
lock()方法最好不要放在try块中,以免lock()时发生异常,导致锁无故被释放。
###四、条件变量(java.util.concurrent.Condition)
如果说ReentrantLock是synchronized的替代选择,那么Condition则是将wait、notify、notifyAll等晦涩难懂的操作转化为直观可控的对象行为。
条件变量最典型的应用就是在标准类库的ArrayBlockingQueue等中。
首先在构造函数中通过ReentrantLock对象的newCondition方法将条件变量创建出来:
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
两个条件变量是从同一个再入锁对象中创建出来的,然后再将它们应用于特定的操作中,如下面的put操作,会一直等待直到notFull条件满足:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
那么notFull什么时候会满足呢?当然是有元素出队的时候:
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
notFull.signal();
return x;
}
可以看到,通过调用条件变量的singal()方法,通知该条件变量的条件已满足,从而等待线程可以继续之后的行为。signal和await方法要成对调用,不然如果只有await方法,线程会一直等待直到被中断(interrupt)。
第16讲 | synchronized底层如何实现?什么是锁的升级、降级?
一、典型回答
synchronized代码块是由一对monitorenter/monitorexit指令实现的,Monitor对象是同步的基本实现单元。
在 Java 6 之前,Monitor的实现完全是靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。
现代JDK中,JVM对此进行了很大的改进,提供了三种不同的Monitor实现,即常说的三种不同的锁:偏斜锁(Biased Locking),轻量级锁和重量级锁,大大改进了其性能。
所谓锁的升级、降级,就是JVM优化synchronized运行的机制,当JVM检测到不同的竞争状况时,会自动在这三种锁之间切换。
当没有竞争出现时,会默认使用偏斜锁。JVM会使用CAS操作,在对象头上的Mark Word部分设置线程ID,以表示这个对象向该线程倾斜,所以这里不涉及真正的互斥锁。这样做的假设是基于很多场景中,大部分对象生命周期中最多只被一个线程锁定,使用偏斜锁就降低了无竞争状态下的开销。
当另一个线程试图去锁定已经被偏斜的对象,JVM会撤销掉偏斜锁,切换到轻量级锁。轻量锁依赖CAS操作Mark Word来试图获取锁,如果重试成功,就使用普通的轻量级锁,否则将进一步升级到重量级锁。
二、Java核心类库中其它类型的锁
Java并发包中的各种同步工具,不仅仅是各种Lock,其它的如Semphore、CountDownLatch,甚至是早期的FutureTask等,都是基于AQS框架实现的。
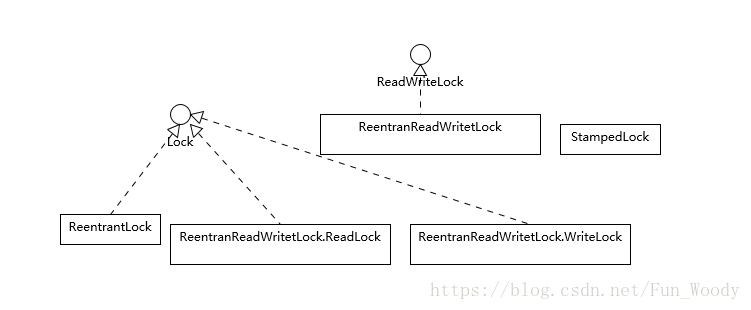
先看一下类图:
ReadWriteLock是一个单独的接口,它代表了一对锁,分别对应只读和写操作。
StampedLock是一个单独的类型,它不支持可再入的语义,即它不是以持有锁的线程为单位。
为什么会需要读写锁等其它类型的锁呢?因为synchronized和ReentrantLock都太过“霸道”,要么不占,要么独占。在写操作不多,只有大量并发读操作的环境下,这些锁的效率会比较低。
下面是一个基于ReadWriteLock实现的Map数据结构,当数据量大,并发读多、并发写少时,比同步版本更具优势:
public class ReadWriteLockSample {
private final Map<String, String> map = new HashMap<String, String>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock readLock = rwl.readLock();
private final Lock writeLock = rwl.writeLock();
public String get(String key) {
readLock.lock();
try {
return map.get(key);
} finally {
readLock.unlock();
}
}
public void put(String key, String value) {
writeLock.lock();
try {
map.put(key, value);
} finally {
writeLock.unlock();
}
}
// ...
}
在运行中,如果写锁已经被某个线程锁定,则试图锁定读锁的操作不会成功,会等待写锁的释放。
读写锁看起来粒度更细一些,但在实际应用中,其表现也不尽如人意,主要是因为其相对较高的开销。
所以JDK在后期引入了StampedLock,在提供类似读写锁的同时,还支持优化读模式,该模式基于一种假设,即大部分的读操作都不会与写操作冲突,其逻辑是先试着读,然后再通过validate方法确认当时是否进入了写模式,如果没有,则成功避免了开销;如果有,则重新尝试获取读锁。样例代码如下:
public class StampedLockSample {
private final StampedLock sl = new StampedLock();
void mutate() {
long stamp = sl.writeLock();
try {
write();
} finally {
sl.unlockWrite(stamp);
}
}
Data access() {
long stamp = sl.tryOptimisticRead();
Data data = read();
if (!sl.validate(stamp)) {
stamp = sl.readLock();
try {
data = read();
} finally {
sl.unlockRead(stamp);
}
}
return data;
}
// ...
}
注意这里的writeLock和unlockWrite一定要保证成对调用。
思考:自旋锁是什么,适合什么场景呢?
是低并发,且同步代码耗时较短时的一种乐观的优化。
第17讲 | 一个线程两次调用start()方法会出现什么情况?
一、典型回答
第二次调用start方法时,会抛出IllegalThreadStateException,这是一种运行时异常,多次调用start被认为是编程错误。
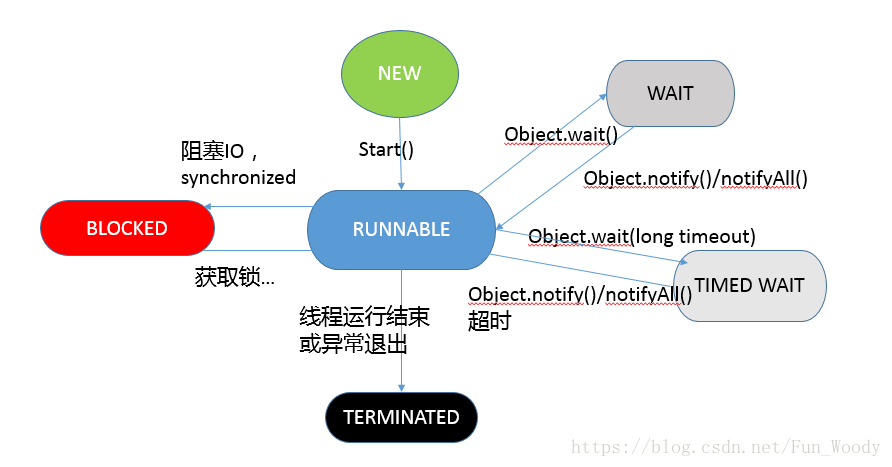
Java 5 之后,线程的状态被定义在其公共内部枚举类java.lang.Thread.State中,分别是:
- 新建(NEW),线程被创建出来,还没有启动的状态。
- 就绪(RUNNABLE),线程已经在JVM中执行,可能正在运行,也可能正在等待CPU资源,在就绪队列中排队。
- 阻塞(BLOCKED),与前两讲介绍的同步操作很相关,线程在等待某个Monitor lock。如进入synchronized代码块时被阻塞。
- 等待(WAITED),在等待其他线程完成某个操作,如生产者消费者模式中,消费者在消费时,如果没有事物可消费,则会等待(wait)生产者完成生产,用类似nofity等动作通知消费者。Thread.join操作也会导致等待。
- 计时等待(TIMED_WIATED),其进入条件和WAITED类似,但调用的是带有超时条件的方法,如wait或join方法的指定超时版本,如:
public final native void wait(long timeout) throws InterruptedException;
- 终止(TERMINATED),线程执行结束后的状态。
在第二次调用start时,线程可能处于任何非NEW的状态,不论如何,线程是不允许被再次启动的。
二、线程的一些基本概念
从操作系统的角度看,线程是系统调度的最小单元,作为任务的真正执行者,有自己的栈(Stack)、寄存器(Register)、本地存储(Thread Local)等,但是会和进程内其它线程共享文件描述符、虚拟地址空间等。
在具体实现中,线程还分为内核线程、用户线程,Java线程的实现和虚拟机相关,基本上在 Java 1.2 之后,JDK已经抛弃了所谓的Green Thread,也就是用户调试的线程,现在的模型是一对一映射到操作系统内核线程。
看Thread的源码,可以发现很多操作都是以JNI形式调用的本地代码。
private native void start0();
private native void setPriority0(int newPriority);
private native void interrupt0();
这种实现有利有弊,总体来说,Java得益于精细粒度的线程和相关的并发操作,其构建高拓展性的的大型应用的能力毋庸置疑,但是它的复杂性也提高了并发编程的门槛。近几年的Go语言提供了协程(coroutine),大大提高了构建并发应用的效率。于此同时,Java也在Loom项目中,孕育新的类似轻量级用户线程(Fiber)等机制,将来的新版JDK中也许就会使用到它。
使用线程可以扩展Thread类,然后实例化。但更常见的做法是实现一个Runnable,将逻辑放在这个Runnable中,通过它构建Thread并启动。这样做的好处是,不会受Java不支持多继承的限制,重用代码实现,当需要重复执行相同的代码时优势明显。而且,它也能更好地与现代Java库中的Executor框架相结合,这样我们不需要操心线程的创建和管理,也能利用Future等机制更好地处理执行结果。线程生命周期通常和业务之间没有本质联系,混淆实现需求和业务需求,就会降低开发的效率。
下图是线程状态和方法之间的关系图:
Thread和Object的方法,听起来简单,实际应用中被证明非常晦涩、易错,这也是为什么Java后来引入了并发包的原因。有了并发包,大多数情况下,我们都不需要直接去调用wait/notify之类的方法了。
三、线程API使用注意事项
- 守护线程:有时候应用需要一个长期驻留后台的线程,但又不希望其影响应用退出,就可以将其设置为守护线程,这个设置必须在启动线程之间完成。
Thread daemonThread = new Thread();
daemonThread.setDaemon(true);
daemonThread.start();
- Spurious wakeup:尤其是在多核CPU的系统中,线程等待存在一种问题,就是在没有任务通知或广播发出的情况下,线程就被唤醒。如果处理不当,就会发生诡异的并发问题,所以我们在等待条件过程中,建议采用下述的方式来书写代码:
// 推荐
while (isCondition()) {
waitForCondition(...);
}
// 不推荐,可能引入bug
if (isCondition()) {
waitForCondition(...);
}
- Thread.onSpinWait():这是 Java 9 引入的特性。16讲的思考题中提到了自旋锁,也可以认为它不是一种锁,而是针对短期等待的一种性能优化技术。onSpinWait()没有任何行为上的保证,而是对JVM的一个暗示,JVM可能通过CPU的pause指令进一步提高性能,性能特别敏感的应用可以关注。
- 慎用ThreadLocal:这是Java提供的一种保存线程私有信息的机制,因为其在线程整个生命周期中都有效,所以可以方便地在某个线程相关的业务模块之间传递信息,如Cookie、事务ID等上下文信息。
它的数据存储于线程相关的ThreadLocalMap中,其内部条目是弱引用。当Key为null时,该条目就变为废弃条目,相关value的回收,往往依赖于几个关键点,即set、remove、rehash。通常弱引用都会和引用队列配合清理机制使用,但ThreadLocalMap并没有这样做,这意味着,废弃项目的回收依赖于显式的触发,否则就要等待线程结束,进而回收相应ThreadLocalMap,这是很多OOM的来源。所以通常建议,应用一定要自己负责remove,并且不要和线程池配合,因为worker线程往往是不会退出的。
第18讲 | 什么情况下Java程序会产生死锁?如何定位、修复?
一、典型回答
死锁是一种特定的程序状态。在多个实体之间,由于循环依赖,导致彼此一直处于等待之中,没有个体能够继续前进。死锁不光发生在线程之间,存在资源独占的进程之间也可能发生死锁。
定位死锁最常见的方法就是利用jstack等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。如果是比较明显的死锁,往往jstack就能直接发现问题所在,类似JConsole甚至可以在图形界面进行有限的死锁检测。
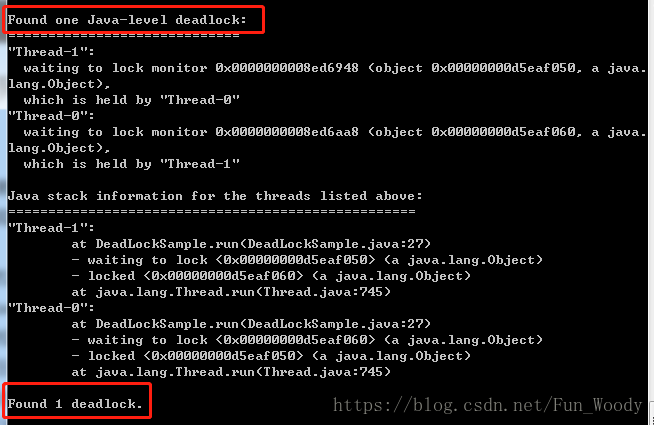
用jstack检测死锁的步骤为,首先通过jps或系统的ps命令、任务管理器等找到程序的进程ID,其实通过jstack pid命令获取线程栈,最后结合代码分析线程栈信息,找出死锁。如果是简单的死锁,jstack可以直接替我们找出:
上图明显告诉了我们存在死锁,以及死锁的成因。
如果程序运行过程中发生了死锁,往往是无法在线解决的。只能通过重启、修改程序来解决问题。所以代码开发阶段互相审查,或者利用工具进行预防性排查,也是很重要的。
二、预防死锁的方法
死锁发生的四个必要条件为:
- 互斥
- 请求与保持
- 不可剥夺
- 环路等待
可以破坏上述条件之一,破坏掉任意一个即可解除死锁。互斥和不可剥夺的条件在并发环境下可能不太好破坏,毕竟要保证线程安全。
下面是几种预防死锁的方法:
- 如果可能,尽量避免使用多个锁,并且只有需要时才持有锁。这是破坏了请求与保持的条件。
- 如果必须使用多个锁,尽量设计好获取锁的顺序,这一点知易行难,可以参看著名的银行家算法。这是破坏了环路等待的条件。
- 使用带超时的方法,为程序带来更多可控性。类似Object.wait(…)或CountDownLatch.await(…),都支持所谓的TIMED_WAIT,我们完全可以假定该锁不一定会获得,指定超时时间,设计好超时无法获取时的逻辑。这也是破坏了请求与保持的逻辑。
- 业界也有一些其它方面的尝试,如通过静态代码分析(如FindBugs)去查找固定的模式,进而发现可能存在的死锁或竞争的状况。实践证明这种方法也有一定的作用,可参考相关文档。
除了上述典型场景的死锁,还有一些更令人头疼的死锁,如类加载过程中发生的死锁,尤其是框架大量使用自定义类加载时,因为往往不是在应用本身的代码库中,所以使用jstack等工具也不见得能够显示全部锁信息,所以处理起来比较棘手。对此,Java有官方文档对此进行说明,并针对特定情况提供了相应的JVM参数和基本准则。
三、思考题
关于今天我们讨论的题目你做到心中有数了吗?今天的思考题是,有时候并不是阻塞导致的死锁,只是某个线程进入了死循环,导致其他线程一直等待,这种问题如何诊断呢?
这种情况可以认为是自旋锁死锁的一种,其它线程因为得不到具体的信号提示,导致线程一直饥饿。这种情况下可以查看线程CPU的使用情况,排查出使用CPU时间片最多的线程,再找出该线程的堆栈信息,排查代码。
基于互斥量的锁如果发生死锁,往往CPU的使用率较低,实践中也可以从这方面进行排查。
第19讲 | Java并发包提供了哪些并发工具类?
一、典型回答
我们通常说的Java并发包就是java.util.concurrent及其子包,包含了java的各种基础并发工具类,具体包括以下几个方面:
- 比synchronized更加高级的各种用于同步的结构,如Semphore, CountDownLatch, CyclicBarrier等,可以实现更加丰富的多线程操作。
- 线程安全的容器,如提高并发性能的ConcurrentHashMap、有序的ConcurrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。
- 各种并发队列的实现,如各种BlockingQueue的实现,比较典型的ArrayBlockingQueue、SynchronousQueue,以及针对特定场景的PriorityQueue等。
- 强大的Executor框架,可以创建各种类型的线程池,进行任务调度,绝大多数情况下,不需要自己从头实现线程池和任务调度器。
我们进行多线程编程,无非是达到这样几个目的:
- 进行多个线程之间的调度、协作,以完成业务逻辑。
- 在线程之间传递数据和状态,这同样是为了业务需要。
- 实现程序的高扩展性,以达到业务对吞吐量的需求。
二、CountDownLatch和CyclicBarrier的区别
- CountDownLatch是不可重置的,所以无法重用;CyclicBarrier可以重用。
- CountDownLatch的基本操作组合是countDown/await,调用await操作的线程等待countDown执行足够多的次数,不管是多个线程来执行countDown,还是一个线程执行多次countDown,只要次数足够即可。所以可以说CountDownLatch操作的是事件。
- CyclicBarrier的基本操作就是await,当所有的伙伴(parties)都执行了await,大家才会继续向前走,并自动进行重置。正常情况下,重置是自动发生的,如果我们调用reset方法,但还有线程在等待,就会导致等待线程被打扰,抛出BrokenBarrierException异常。CyclicBarrier的侧重点是线程,而不是调用事件。它的典型应用场景是等待并发线程结束。
三、线程安全容器
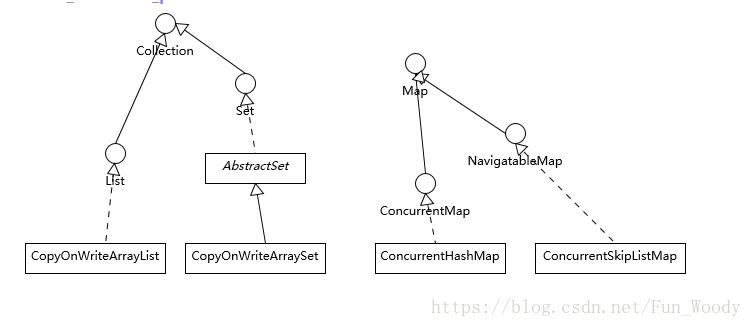
首先可参考下面的类图:
总体上类的结构比较简单。如果我们侧重于Map放入或获取的速度,而不在乎顺序,那么应该选ConcurrentHashMap,否则选ConcurrentSkipListMap;如果我们要对大量数据进行频繁的修改,那么ConcurrentSkipListMap也可能表现出优势。
为什么并发容器里没有ConcurrentTreeMap呢?因为要红黑树在插入、删除结点时,都要移动树的节点从而达到平衡,这导致在多线程场景下很难进行合适粒度的同步,所以很难实现高效的线程安全。
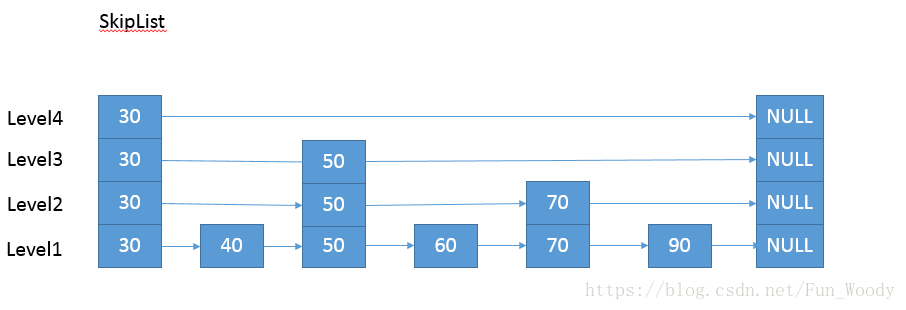
而SkipListMap结构则简单很多,通过层次结构提高访问速度,虽然空间不够紧凑(O(nlogn)),但是在增删元素时线程安全的开销要小很多。下面是它的结构示意图:
关于两个CopyOnWrite容器,其实CopyOnWriteArraySet是包装了CopyOnWriteArrayList来实现的,所以在学习时可以专注其中一种。
CopyOnWrite的意思是,任何修改操作,如add, remove, set,都会导致数组的复制,对复制的数组进行修改后,再直接替换掉原来的数组,通过这种防御性的方式,来实现另类的线程安全。所以这种数据结构,还是适合读多写少的场景,不然修改的开销是比较明显的。
第20讲 | 并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
一、典型回答
- ConcurrentLinkedQueue基于lock-free,在高并发场景下具有较高的性能。
- LinkedBlockingQueue内部基于锁,提供了BlockingQueue的特性方法。
Java并发包中的容器,从命名上看可大致分为三类:Concurrent*, CopyOnWrite*和Blocking,同样是线程安全容器,它们的区别为:
- Concurrent容器没有CopyOnWrite容器的高修改开销。
- 凡事都有两面性,Concurrent容器往往提供了较低的遍历一致性,可以这样理解所谓的弱一致性,即迭代器在遍历时,容器如果发生了修改,遍历还可以继续。
- 弱一致性的另一个特性是size()操作不一定准确。
- 与此同时,弱一致性的容器,读取的性能具有一定的不确定性。
- 与弱一致性对应的是同步容器常有的属性“fail-fast”,也就是在遍历过程中容器如果发生了修改,则会抛出ConcurrentModificationException,不再继续遍历。
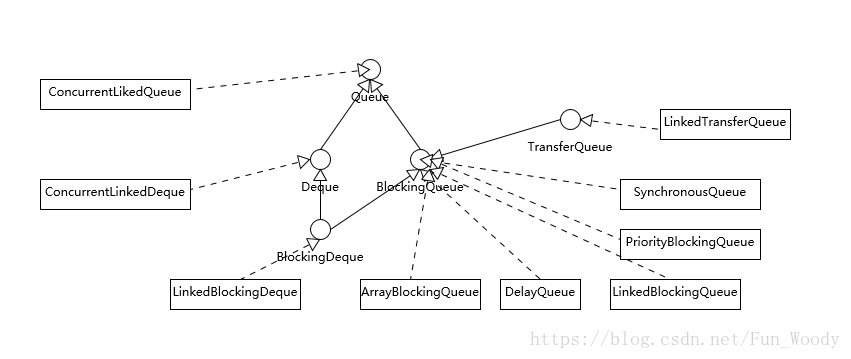
二、线程安全队列概述
废话不多说,先上图,图中没有将非线程安全队列包括进来:
Deque类型的侧重点是对队列头尾都支持插入、删除操作。
大部分类型实现了BlockingQueue接口,意思就是在插入时如果有必要会等待直到队列不满,获取时同样会等待直到队列非空。
另一个BlockingQueue常被考察的点是队列是否有界,这一点也往往会影响我们在应用开发时的选择,简单总结如下:
- ArrayBlockingQueue是最典型的有界队列,其内部以final的数组保存数据,创建队列时就要指定容量,如
public ArrayBlockingQueue(int capacity, boolean fair)
- LinkedBlockingQueue,容易被误解为无界队列,但是其行为和内部代码是基于有界的逻辑实现的,在初始化时也要指定容量,如果没有指定,则默认是Interger.MAX_VALUE,即变成了无界队列。
- SynchronousQueue是一个比神奇的队列实现,它的每个删除操作都要等待插入操作,反之亦然。它的容量是1吗?No,是0。
- PriorityQueue是无界队列,虽然从严格意义上讲,它的容量也要受系统资源限制。
- DelayedQueue和LinkedTransferQueue也是无边界队列。对于无界队列,有一个很自然的属性就是插入操作永远不需要等待。
如果我们分析不同队列的底层实现,BlockingQueue的内部基本都是基于锁实现,下面是典型的LinkedBlockingQueue:
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
可以看出,和之前介绍过的ArrayBlockingQueue不同的是,LinkedBlockingQueue内部的两个条件变量,是从两个不同的ReentrantLock中构建出来的,粒度更细,所以在通用场景下,LinkedBlockingQueue的吞吐量要大于Array的。
下面的take方法与ArrayBlockingQueue也不一样,因为是链表结构,它要自己维护队列的元素数量值:
public E take() throws InterruptedException {
final E x;
final int c;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
而类似ConcurrentLinkedQueue,则是基于CAS的无锁技术,不需要在每个操作时使用锁,所以扩展性表现要更加优异。
SynchronousQueue,在 Java 6 中,其实现方式发生了很大的变化,由CAS操作代替了之前基于锁的逻辑,是Executors.newCachedThreadPool()默认使用的队列。
三、日常开发中如何选择队列
以LinkedBlockingQueue、ArrayBlockingQueue和SynchronousQueue为例,需求可以从多个方面来考虑:
- 考虑应用场景中对边界的要求,ArrayBlockingQueue是有明确的容量限制的,而LinkedBlockingQueue的容量限制取决于我们在创建时是否指定,SynchronousQueue则不能缓存任何元素。
- 从空间利用角度来看,ArrayBlockingQueue对空间的利用更加紧凑,因为它使用的是数组,不需要创建所谓节点,但因为要申请连续的内存空间,所以初始化时对空间的要求更高。
- 通用场景下,LinkedBlockingQueue的吞吐量一般比ArrayBlockingQueue更高,因为其使用了更加细粒度的锁操作。
- ArrayBlockingQueue实现更加简单,性能更好预测,属于表现稳定的选手。
- 如果我们需要实现的两个线程接力性(handoff)的场景,SynchronousQueue则很适合这种场景,而且线程间协调和数据传输统一起来,代码更加规范。
- 很多时候SynchronousQueue的性能表现往往大大超过其它实现,尤其是在队列元素较小的场景。