Java核心技术36讲阅读笔记(1)
本文参考极客时间杨晓峰-Java核心技术36讲
本文为博主阅读《Java核心技术36讲》整理的笔记,如需转载,请附上本文链接
1.对“Write once,run anywhere!"的理解
“一次编写,到处运行”说的是Java语言跨平台的特性,Java的跨平台特性与Java虚拟机的存在密不可分,可在不同的环境中运行。比如说Windows平台和Linux平台都有相应的JDK,安装好JDK后也就有了Java语言的运行环境。其实Java语言本身与其他的编程语言没有特别大的差异,并不是说Java语言可以跨平台,而是在不同的平台都可以让Java语言运行的环境而已,所以才有了Java一次编写到处运行的效果。
严格的讲,跨平台的语言不止Java一种,但Java是较为成熟的一种。“一次编写,到处运行”这种效果跟编译器有关。编译语言的处理需要编译器和解释器。Java虚拟机和DOS类似,相当于一个供程序运行的平台。
程序从源代码到运行的三个阶段:编码——编译——运行——调试。Java在编译阶段则体现了跨平台的特点。编译过程大致是这样的:首先是将Java源代码转化成.class字节码文件,这是第一次编译。.class文件就是可以到处运行的文件。然后Java字节码会被转化为目标机器码,这是由JVM来执行的,即Java的第二次编译。
“到处运行”的关键和前提就是JVM。因为在第二次编译中JVM起着关键作用。在可以运行Java虚拟机的地方都有一个JVM操作系统。从而使Java提供了各种不同平台上的虚拟机制,因此实现了“到处运行”的效果。需要强调的一点是,Java并不是编译机制,而是解释机制。Java字节码的设计充分考虑了JIT这一即时编译方式,可以将字节码直接转化成高性能的本地机器码,这同样是Java虚拟机的一个构成部分。
2.Java语言的特性
- 面向对象(封装,继承,多态)
- 平台无关性(JVM运行.class文件)
- 语言(泛型,Lambda)
- 类库(集合,并发,网络,IO/NIO)
- JRE(Java运行环境,JVM,类库)
- JDK(Java开发工具,包括JRE,Javac,诊断工具)
3.Exception和Error的区别
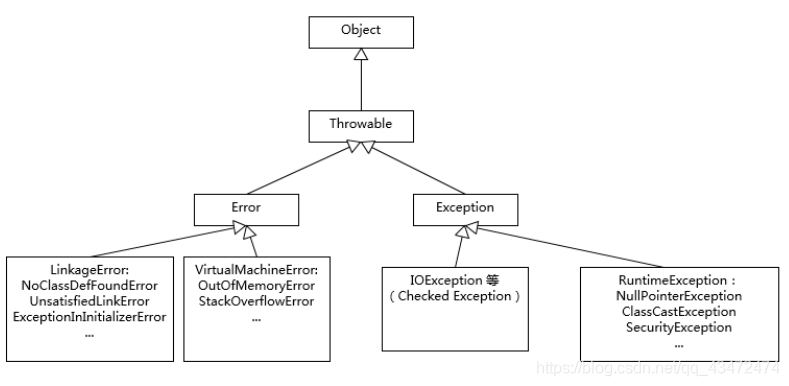
- Exception和Error都是继承了Throwable类,在Java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
- Exception和Error体现了Java平台设计者对不同异常情况的分类。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
- Error是指在正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM本身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如OutOfMemoryError类,都是Error的子类。
- Exception又可分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。不检查异常就是所谓的运行时异常,类似NullpointerException、ArrayIndexOutOfBoundsException类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
4.final、finally、finalize的不同
- final可以用来修饰类,方法,变量,分别有不同的意义,final修饰的class代表不可以继承扩展,final修饰的变量是不可以修改的,而final修饰的方法是不可以重写的(override)。
- finally则是Java保证重点代码一定要被执行的一种机制。我们可以使用try—finally或者try—catch—finally来进行类似关闭JDBC连接,保证unlock锁等动作。
- finalize是基础类java.lang.Object的一个人方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。finalize机制现在已经不推荐使用,并且JDK 9开始被标记为deprecated。
5.强引用、软引用、弱引用、幻象引用有什么区别?具体使用场景是什么?
不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和对垃圾收集的影响。
- 所谓强引用(“Strong”Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,就是可以被垃圾收集的了,当然具体的回收时机还是要看垃圾收集的策略。
- 软引用(SoftReference),是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当JVM认为内存不足时,才会去试图回收软引用指向的对象。JVM会确保在抛出OutOfMemoryError之前,清理软引用指向的对象。软引用常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
- 弱引用(WeakReference)并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这样就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
- 对于幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被finalize以后,做某些事情的机制,比如,通常用来做所谓的PostMortem清理机制,也有人利用幻象引用监控对象的创建和销毁。
6.String、StringBuffer、StringBuilder有什么区别?
- String是Java语言非常基础和重要的类,提供了构造和管理字符串的各种基本逻辑。它是典型的Immutable类,被声明为final class,所有属性也是final的。也由于它的不可变性,类似拼接,裁剪字符串等动作,都会产生新的String对象。由于字符串操作的普遍性,所以相关操作的效率往往对应用性能有明显影响。
- StringBuffer是为解决上面提到拼接产生太多中间对象的问题而提供的一个类,我们可以用append或者add方法,把字符串添加到已有序列的末尾或者指定位置。StringBuffer本质是一个线程安全的可修改字符序列,它保证了线程安全,也随之带来了额外的性能开销,所以除非有线程安全的需要,不然还是使用它的后继者,也就是StringBuffer。
- StringBuilder是java 1.5中新增的,在能力上和StringBuffer没有本质区别,但是去掉了线程安全的部分,有效减小了开销,是绝大部分情况下进行字符串拼接的首选。
7.Java反射机制、动态代理是基于什么原理?
反射机制是Java语言提供的一种基础功能、赋予程序在运行时自省(introspect,官方用语)的能力。通过反射我们可以直接操作类或者对象,比如获取某个对象的类定义、获取类声明的属性和方法,调用方法或者构造对象,甚至可以运行时修改类定义。
动态代理是一种方便运行时动态构造代理,动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装RPC调用,面向切片的编程(AOP)。
实现动态代理的机制很多,比如JDK自身提供的动态代理,就是就要利用了上面提到的反射机制。还有其他的的实现方式,比如利用传说中更高性能的自己码操作机制,类似ASM,cglib(基于ASM),javassist等。
8.反射的原理。
反射最大的作用之一就是在于我们可以不在编译时知道某个对象的类型,而在运行时通过提供完整的“包名+类名.class”得到。注意:不是在编译时,而是在运行时。
功能:
- 在运行时能判断任意一个对象所属的类。
- 在运行时能构造任何一个类的对象。
- 在运行时判断任意一个类所具有的成员变量和方法。
- 在运行时调用任意一个对象的方法。
说大白话就是,利用Java反射机制我们可以加载一个运行时才得知的名称的class,获悉其构造方法,并声明其对象实体,能对其fields设置并唤起其methods。
应用场景:
反射技术常用在各类通用框架开发中,因为为了保证框架的通用性,需要根据配置文件加载不同的对象或类,并调用不同的方法,这个时候就会用到反射–运行时动态加载需要加载的对象。
特点:
由于反射会额外消耗一定的系统资源,因此如果不需要动态地创建一个对象,那么就不需要用反射。另外,反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
9.动态代理的原理。
为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在两者之间起到中介作用。
所谓动态代理,就是实现阶段不用关心代理谁,而是在运行阶段才指定代理哪一个对象(不确定性)。
组成要素:
(动态)代理模式主要涉及三个要素:
- 抽象类接口
- 被代理类(具体实现抽象接口的类)
- 动态代理类:实际调用被代理类的方法和属性的类
实现方式:
实现动态代理的方式有很多,比如JDK自身提供的动态代理,就是主要利用了反射机制。还有其他的实现方式,类似ASM,CGLIB(基于ASM),Javassist等。
10.int和Integer有什么区别?
- int和我们常说的整型数字,是Java的8个原始数据类型(Primitive Types,boolean,short,char,int,float,double,long)之一。Java语言虽然号称一切都是对象,但原始数据类型是例外。
- Integer是int对应的包装类,它有一个int类型的字段存储数据,并且提供了基本操作,比如数学运算,int和字符串之间转换等。在Java 5中,引入了自动装箱和自动拆箱功能(boxing/unboxing),Java可以根据上下文,自动进行转换,极大地简化了相关编程。
- 关于Integer的值缓存,这涉及Java 5中另一个改进。构建Integer对象的传统方式是直接调用构造器,直接new一个对象。但是根据实践,我们发现大部分数据操作都是集中在有限的,较小的数据范围,因而,在Java 5中新增了静态工厂方法valueOf,在调用它的时候会利用一个缓存机制,带来了明显的性能改进。按照Javadoc,这个值默认缓存是-128到127之间。
11.Vector,ArrayList,LinkedList的区别
- 这三者都是实现集合框架中的List,也就是所谓的有序集合,因此具体功能也比较近似,比如都是提供按照位置进行定位,添加或者删除的操作,都是提供迭代器以遍历其内容等,但因为具体的设计区别,在行为,性能,线程安全等方面,表现又有很大不同。
- Vector是Java早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。Vector内部是使用对象数组来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有的数组数据。
- ArrayList是应用更加广泛的动态数组实现,它本身不是线程安全的,所以性能要好很多。与Vector近似,ArrayList也是可以根据需要调整容量,不过两者的调整逻辑有所区别,Vector在扩容时会提高一倍,而ArrayList则是提高50%。
- LinkedList顾名思义是Java提供的双向链表,所以它不需要像上面两种那样调整容量,它也不是线程安全的。
12.不同容器类型适合的场景
- Vector和ArrayList作为动态数组,其内部元素以数组形式顺序存储的,所以非常适合随机访问的场合。除了尾部插入和删除元素,往往性能会相对较差,比如我们在中间位置插入一个元素,需要移动后续所有元素。
- 而LinkedList进行节点插入,删除却高效得多,但是随机访问性能则比动态数组慢。
13.TreeSet和HashSet的基本特征和典型使用场景
- TreeSet支持自然随机访问,但是添加、删除、包含等操作相对低效(log(n)时间)。
- HashSet则是利用哈希算法,理想情况下,如果哈希散列正常,可以提供常数时间的添加、删除、包含等操作,但是它不保证有序。
- LinkedHashSet内部构建了一个记录插入顺序的双向链表,因此提供了按照插入顺序遍历的能力,与此同时,也保证了常数时间的添加、删除、包含等操作,这些操作性能略低于HashSet,因为需要维护链表的开销。
- 在遍历元素时,HashSet受自身容量的影响,所以初始化时,除非有必要,不然不要将其背后的HashSet容量设置过大。而对于LinkedHashSet,由于其内部链表提供的方便,遍历性能只和元素多少有关系。
14.Hashtable,HashMap,TreeMap的区别
- Hashtable,HashMap,TreeMap都是最常见的Map实现,是以键值对的形式存储和操作数据的容器类型。
- Hashtable是早期Java类库提供的一个哈希表实现,本身是同步的,不支持null键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
- HashMap是应用更加广泛的哈希表实现,行为上大与Hashtable一致,主要区别在于HashMap不是同步的,支持null键和值等。通常情况下,HashMap进行put或者get操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户ID和用户信息对应的运行时存储结构。
- TreeMap则是基于红黑树的一种提供顺序访问的Map,和HashMap不同,它的get、put、remove之类操作都是O(log(n))的时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
15.解决哈希冲突的方法
- 开放定址法:当关键字key的哈希地址p=H出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2…直到找出一个不冲突的地址pi,将对应元素存入其中。
- 再哈希法:同时构造多个不同的哈希函数Hi=RH1(key) i=1,2,…,k,当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生产生聚集,但增加了计算时间。
- 链地址法:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和哈希表发生冲突的元素,一律填入溢出表。
16.如何保证线程是安全的?
- Java提供了不同层面的线程安全支持。在传统集合框架内部,除了Hashtable等同步容器,还提供了所谓的同步包装器(Synchronized Wrapper),我们可以调用Connections工具类提供的包装方法来获取一个同步的包装容器(如Connections.synchronizedMap),但是他们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
- 另外,更加普遍的选择是利用并发包提供的线程安全容器类,它提供了各种并发容器,比如:ConncurrentHashMap、CopyOnWriteArrayList。
- 各种线程安全队列(Queue,Deque),比如ArrayBlockingQueue,SynchronousQueue。各种有序容器的线程安全版本等。
- 具体保证线程安全的方式,包括有从简单的synchronize方式,到基于更加精细化的,比如基于分离锁实现的ConcurrentHashMap等并发实现等。具体选择要看开发的场景需求,总体来说,并发包内提供的容器通用场景,远优于早期的简单同步实现。
