我们学习一下分桶表,其实分区和分桶这两个概念对于初学者来说是比较难理解的。但对于理解了的人来说,发现又是如此简单。
我们先建立一个分桶表,并尝试直接上传一个数据
create table student4(sno int,sname string,sex string,sage int, sdept string) clustered by(sno) into 3 buckets row format delimited fields terminated by ','; set hive.enforce.bucketing = true;强制分桶。 load data local inpath '/home/hadoop/hivedata/students.txt' overwrite into table student4;

我们看到虽然设置了强制分桶,但实际student表下面只有一个students一个文件。分桶也就是分区,分区数量等于文件数,所以上面方法并没有分桶。
现在,我们用插入的方法给另外一个分桶表传入同样数据

create table student4(sno int,sname string,sex string,sage int, sdept string) clustered by(sno) into 3 buckets row format delimited fields terminated by ','; set hive.enforce.bucketing = true;强制分桶。 load data local inpath '/home/hadoop/hivedata/students.txt' overwrite into table student4; 我们看到虽然设置了强制分桶,但实际STUDENT表下面只有一个STUDENTS一个文件。 分桶也就是分区,分区数量等于文件数,所以上面方法并没有分桶。 #创建第2个分桶表 create table stu_buck(sno int,sname string,sex string,sage int,sdept string) clustered by(sno) sorted by(sno DESC) into 4 buckets row format delimited fields terminated by ','; #设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数 set hive.enforce.bucketing = true; set mapreduce.job.reduces=4; #开会往创建的分通表插入数据(插入数据需要是已分桶, 且排序的) #可以使用distribute by(sno) sort by(sno asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段) #注意使用cluster by 就等同于分桶+排序(sort) insert into table stu_buck select sno,sname,sex,sage,sdept from student distribute by(sno) sort by(sno asc); Query ID = root_20171109145012_7088af00-9356-46e6-a988-f1fc5f6d2e13 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 4 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1510197346181_0014, Tracking URL = http://server71:8088/proxy/application_1510197346181_0014/ Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1510197346181_0014 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 4 2017-11-09 14:50:59,642 Stage-1 map = 0%, reduce = 0% 2017-11-09 14:51:38,682 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.04 sec 2017-11-09 14:52:31,935 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 7.91 sec 2017-11-09 14:52:33,467 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 15.51 sec 2017-11-09 14:52:39,420 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 22.5 sec 2017-11-09 14:52:40,953 Stage-1 map = 100%, reduce = 92%, Cumulative CPU 25.86 sec 2017-11-09 14:52:42,243 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 28.01 sec MapReduce Total cumulative CPU time: 28 seconds 10 msec Ended Job = job_1510197346181_0014 Loading data to table default.stu_buck Table default.stu_buck stats: [numFiles=4, numRows=22, totalSize=527, rawDataSize=505] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 4 Cumulative CPU: 28.01 sec HDFS Read: 18642 HDFS Write: 819 SUCCESS Total MapReduce CPU Time Spent: 28 seconds 10 msec OK Time taken: 153.794 seconds
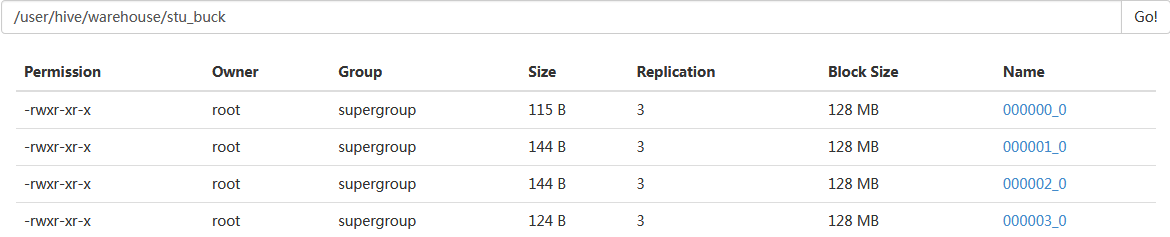
我们设置reduce的数量为4,学过mapreduce的人应该知道reduce数等于分区数,也等于处理的文件数量。
把表或分区划分成bucket有两个理由
扫描二维码关注公众号,回复: 4498084 查看本文章
1,更快,桶为表加上额外结构,链接相同列划分了桶的表,可以使用map-side join更加高效。
2,取样sampling更高效。没有分区的话需要扫描整个数据集。
hive> create table bucketed_user (id int,name string)
> clustered by (id) sorted by (id asc) into 4 buckets;
重点1:CLUSTERED BY来指定划分桶所用列和划分桶的个数。HIVE对key的hash值除bucket个数取余数,保证数据均匀随机分布在所有bucket里。
重点2:SORTED BY对桶中的一个或多个列另外排序
总结:我们发现其实桶的概念就是MapReduce的分区的概念,两者完全相同。物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
而分区表的概念,则是新的概念。分区代表了数据的仓库,也就是文件夹目录。每个文件夹下面可以放不同的数据文件。通过文件夹可以查询里面存放的文件。但文件夹本身和数据的内容毫无关系。
桶则是按照数据内容的某个值进行分桶,把一个大文件散列称为一个个小文件。
这些小文件可以单独排序。如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可。效率当然大大提升。
同样,对数据抽样的时候,也不需要扫描整个文件。只需要对每个分区按照相同规则抽取一部分数据即可。
转载于: