hive中有数据分区的方案,也有数据分桶的方案,今天我们就来探讨下数据分桶 以及数据分桶使用的场景。
该篇文章主要分为一下几个部分:
1.数据分桶的适用场景
2.数据分桶的原理
3.数据分桶的作用
4.如何创建数据分桶表
5.如何将数据插入分桶表
6.针对于分桶表的数据抽样
7.数据分桶的一些缺陷
数据分桶的适用场景:
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,
尤其是需要确定合适大小的分区划分方式,(不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况)
试试分桶是将数据集分解为更容易管理的若干部分的另一种技术。
数据分桶的原理:
跟MR中的HashPartitioner的原理一模一样
MR中:按照key的hash值去模除以reductTask的个数
Hive中:按照分桶字段的hash值去模除以分桶的个数
Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
数据分桶的作用:
好处:
1、方便抽样
2、提高join查询效率
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
创建数据分桶表:
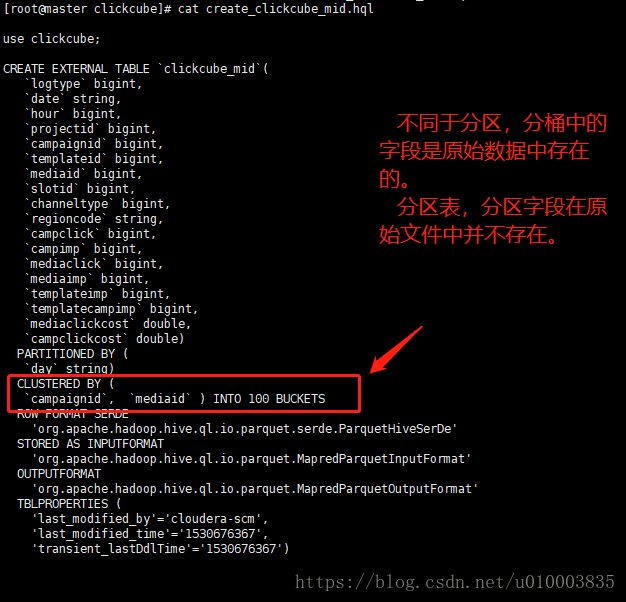
创建数据分桶表与普通表的表区别并不太大,如下为一个创建数据分桶表的示例:
use clickcube; CREATE EXTERNAL TABLE `clickcube_mid`( `logtype` bigint, `date` string, `hour` bigint, `projectid` bigint, `campaignid` bigint, `templateid` bigint, `mediaid` bigint, `slotid` bigint, `channeltype` bigint, `regioncode` string, `campclick` bigint, `campimp` bigint, `mediaclick` bigint, `mediaimp` bigint, `templateimp` bigint, `templatecampimp` bigint, `mediaclickcost` double, `campclickcost` double) PARTITIONED BY ( `day` string) CLUSTERED BY ( `campaignid`, `mediaid` ) INTO 100 BUCKETS ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' TBLPROPERTIES ( 'last_modified_by'='cloudera-scm', 'last_modified_time'='1530676367', 'transient_lastDdlTime'='1530676367')
其实主要注意的地方就如下的点:
CLUSTERED BY (
`campaignid`, `mediaid` ) INTO 100 BUCKETS
如何将数据插入分桶表
将数据导入分桶表主要通过以下步骤
第一步:
从hdfs或本地磁盘中load数据,导入中间表
第二步:
通过从中间表查询的方式的完成数据导入
分桶的实质就是对 分桶的字段做了hash 然后存放到对应文件中,所以说如果原有数据没有按key hash ,
需要在插入分桶的时候hash, 也就是说向分桶表中插入数据的时候必然要执行一次MAPREDUCE,
这也就是分桶表的数据基本只能通过从结果集查询插入的方式进行导入
这里我们主要讲解第二步:
主要的过程我们写为一个SQL
use clickcube; set hive.enforce.bucketing = true; INSERT OVERWRITE TABLE clickcube_mid_bucket PARTITION( day = '2018-07-03' ) SELECT clickcube_mid.logtype, clickcube_mid.`date`, clickcube_mid.`hour`, clickcube_mid.projectid, clickcube_mid.campaignid, clickcube_mid.templateid, clickcube_mid.mediaid, clickcube_mid.slotid, clickcube_mid.channeltype, clickcube_mid.regioncode, clickcube_mid.campclick, clickcube_mid.campimp, clickcube_mid.mediaclick, clickcube_mid.mediaimp, clickcube_mid.templateimp, clickcube_mid.templatecampimp, clickcube_mid.mediaclickcost, clickcube_mid.campclickcost FROM clickcube_mid WHERE day = '2018-07-03'
这里我们需要注意几点
我们需要确保reduce 的数量与表中的bucket 数量一致,为此有两种做法
1.让hive强制分桶,自动按照分桶表的bucket 进行分桶。(推荐)
set hive.enforce.bucketing = true;
2.手动指定reduce数量
set mapreduce.job.reduces = num;
/
set mapreduce.reduce.tasks = num;
并在 SELECT 后增加CLUSTER BY 语句
下面展示下整体的数据导入脚本
主要分为3个文件:
-rw-r--r--. 1 root root 637 7月 4 20:37 insert_into_bucket.hql
-rw-r--r--. 1 root root 37 7月 4 20:26 insert_into_bucket.init
-rwxr-xr-x. 1 root root 1788 7月 4 20:27 insert_into_bucket.sh
insert_into_bucket.hql 数据导入HQL
insert_into_bucket.init 设置初始环境
insert_into_bucket.sh 主体执行脚本
insert_into_bucket.sh
#! /bin/bash set -o errexit source /etc/profile source ~/.bashrc ROOT_PATH=$(dirname $(readlink -f $0)) echo $ROOT_PATH date_pattern_old='^[0-9]{4}-[0-9]{1,2}-[0-9]{1,2}$' date_pattern='^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$' #参数数量 argsnum=$# #一些默认值 curDate=`date +%Y%m%d` partitionDate=`date -d '-1 day' +%Y-%m-%d` fileLocDate=`date -d '-1 day' +%Y-%m-%d` #日志存放位置 logdir=insert_bucket_logs function tips() { echo "Usage : insert_into_bucket.sh [date]" echo "Args :" echo "date" echo " date use this format yyyy-MM-dd , ex : 2018-06-02" echo "============================================================" echo "Example :" echo " example1 : sh insert_into_bucket.sh" echo " example2 : sh insert_into_bucket.sh 2018-06-02" } if [ $argsnum -eq 0 ] ; then echo "No argument, use default value" elif [ $argsnum -eq 1 ] ; then echo "One argument, check date pattern" arg1=$1 if ! [[ "$arg1" =~ $date_pattern ]] ; then echo -e "\033[31m Please specify valid date in format like 2018-06-02" echo -e "\033[0m" tips exit 1 fi dateArr=($(echo $arg1 |tr "-" " ")) echo "dateArr length is "${#dateArr[@]} partitionDate=${dateArr[0]}-${dateArr[1]}-${dateArr[2]} else echo -e "\033[31m Not valid num of arguments" echo -e "\033[0m" tips exit 1 fi if [ ! -d "$logdir" ]; then mkdir -p $logdir fi cd $ROOT_PATH #nohup hive -hivevar p_date=${partitionDate} -hivevar f_date=${fileLocDate} -f hdfs_add_partition_dmp_clearlog.hql >> $logdir/load_${curDate}.log nohup beeline -u jdbc:hive2://master:10000 -n root --color=true --silent=false --hivevar p_date=${partitionDate} -i insert_into_bucket.init -f insert_into_bucket.hql >> $logdir/insert_bucket_${curDate}.log
insert_into_bucket.init
set hive.enforce.bucketing = true;
insert_into_bucket.hql
use clickcube; INSERT OVERWRITE TABLE clickcube_mid_bucket PARTITION( day = '${hivevar:p_date}' ) SELECT clickcube_mid.logtype, clickcube_mid.`date`, clickcube_mid.`hour`, clickcube_mid.projectid, clickcube_mid.campaignid, clickcube_mid.templateid, clickcube_mid.mediaid, clickcube_mid.slotid, clickcube_mid.channeltype, clickcube_mid.regioncode, clickcube_mid.campclick, clickcube_mid.campimp, clickcube_mid.mediaclick, clickcube_mid.mediaimp, clickcube_mid.templateimp, clickcube_mid.templatecampimp, clickcube_mid.mediaclickcost, clickcube_mid.campclickcost FROM clickcube_mid WHERE day = '${hivevar:p_date}'
针对于分桶表的数据抽样:
分桶的一个主要优势就是数据抽样,
主要有两种方式
1)基于桶抽样
2)基于百分比抽样
1)基于桶抽样:
hive> SELECT * FROMbucketed_users
> TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
0 Nat
4 Ann
桶的个数从1开始计数。因此,前面的查询从4个桶的第一个中获取所有的用户。 对于一个大规模的、均匀分布的数据集,这会返回表中约四分之一的数据行。我们 也可以用其他比例对若干个桶进行取样(因为取样并不是一个精确的操作,因此这个 比例不一定要是桶数的整数倍)。
说法一:
注:tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUTOF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。
x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
说法二:
分桶语句中的分母表示的是数据将会被散列的桶的个数,
分子表示将会选择的桶的个数。
示例:
SELECT COUNT(1)
FROM clickcube_mid_bucket
TABLESAMPLE(BUCKET 10 OUT OF 100 ON rand())
WHERE day='2018-07-03';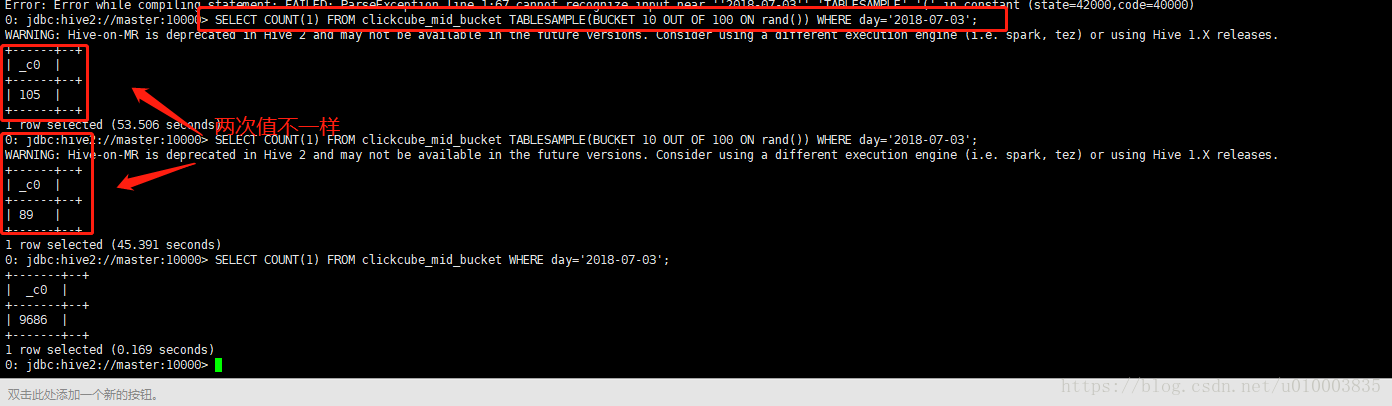
2)基于百分比抽样:
hive另外一种按照抽样百分比进行抽样的方式,该种方式基于行数,按照输入路径下的数据块的百分比进行抽样。
这种抽样的最小单元是一个hdfs数据块,如果表的数据大小小于普通块大小128M,将返回所有行。
基于百分比的抽样方式提供了一个变量,用于控制基于数据块的调优种子信息:
<property>
<name>hive.sample.seednumber</name>
<value>0</value>
</property>
A number userd for percentage sampling. By changing this number, user will change the subsets of data sampled.
数据分桶存在的一些缺陷:
如果通过数据文件LOAD 到分桶表中,会存在额外的MR负担。
实际生产中分桶策略使用频率较低,更常见的还是使用数据分区。
转载自https://blog.csdn.net/u010003835/article/details/80911215