测试目的
如果不清楚什么是Optane,可以先了解一下:Optane介绍
使用 Intel Memory Drive Technology (IMDT) 将 Intel Optane SSD 模拟成内存,进行性能测试。
在运行时,部分 DRAM 被用作缓存,缓存命中失败时,IMDT会进行拦截并将数据写入IMDT,IMDT通过机器学习从 Optane ssd 不断地预读取数据来避免缓存丢失。
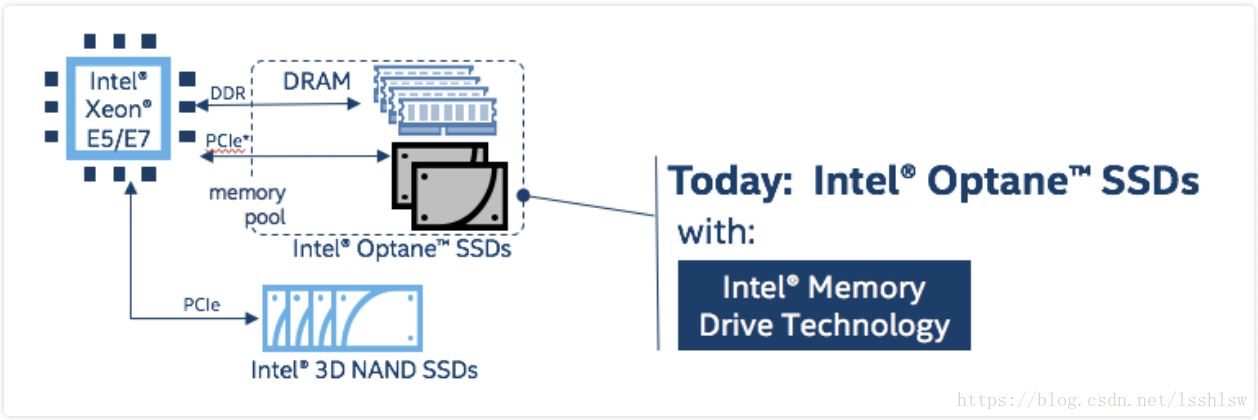
验证是否可以通过 IMDT 技术来降低内存成本。
测试
配置
| group ID | 内存配置 | 可用内存(G) | 其余配置 | 运行环境 |
| A | 256G DRAM | 250 | CPU: 2 * Intel® Xeon® Gold 5118 Processor DISK: 11 * HDD(8T) + 1 * SSD(1T) NIC: 2 * 10Gbps |
CentOS 7.4 CDH 5.15 java 8 Update 162 Apache Spark 2.3.1 Intel® Memory Drive Technology |
| B | 64G DRAM + 375G Optane | 342 | ||
| C | 256G DRAM + 375G Optane | 566 |
tip: 由于配置所限,有条件的话最好能增加一组 DRAM = DRAM + Optane 的对照组
测试方法
- 测试框架: Hibench
- 运行模式:standalone 单机模式
- executor配置: 2C, 20G
| group id | 配置 |
|---|---|
| A | A机器 7 executors |
| B | B机器 7 executors |
| C | C机器 7 executors |
| B-1 | B机器 14 executors |
| C-1 | C机器 14 executors |
- A,B,C 三组用来判断相同spark参数在不同硬件上的表现
- B-1,C-1 用于对比在 A 已经没有内存资源情况下的表现
Benchmark
Cache
| group ID | data size(on Disk) | data size(on Mem) | cost(m) |
|---|---|---|---|
| A | 4.3G | 19G | 1.9 |
| B | 4.3G | 19G | 2.4 |
| C | 4.3G | 19G | 2 |
| A | 16.2G | 63G | 6.3 |
| B | 16.2G | 63G | 6.9 |
| C | 16.2G | 63G | 6.6 |
使用spark.cache()对数据进行缓存。
Wordcount
| group ID | data size | cost (minutes) |
| A | 100G | 3.1 |
| B | 3.5 | |
| C | 3 | |
| A | 250G | 7.9 |
| B | 8.3 | |
| C | 7.9 |
Terasort
| group ID | data size | cost (minutes) |
| A | 50G | 4.7 |
| B | 6.8 | |
| C | 4.9 | |
| A | 250G | 14 |
| B | 22 | |
| C | 15.3 |
KMeans
| group ID | data information | run params | cost (minutes) |
| A | size: 19G nums: 100M clusters: 5 dimension: 20 |
iteration: 5 k: 10 | 2 |
| B | 3.7 | ||
| C | 1.8 | ||
| A | size: 56G nums: 500M clusters: 5 dimension: 20 |
5.8 | |
| B | 18.3 | ||
| C | 4.9 | ||
| C-1 | 3.5 |
总结
Optane IMDT 的目标是解决DRAM价格昂贵和单机内存容量瓶颈的问题,例如单机达到数十T内存。
在不同的 case 下,应用的性能差别非常大,在DRAM运行时间的 30-95% 之间波动,IO密集型的应用表现最好,其次是计算密集型,内存带宽是瓶颈的应用性能下滑严重。
建议用法: 部分节点使用Optane扩展内存,使用yarn的node label或mesos的role机制将内存带宽不敏感的任务调度到相应节点,能在一定程度上减少成本和提升运行效率的目的。
Q: 为什么和官方测试的数据有出入?
A: 官方的测试是假定内存容量是瓶颈(cpu/IO等资源充裕)的场景。然后让本来只能启动30个 7C 17G executor的应用,变成 42 个 10C 40G 的executor,从而达到增加20%的机器成本达到3.5倍的性能提升效果。
容量说明
目前单机最多扩展8块OPTANE内存。
本文使用最佳性能模式,比最大容量模式内存会有所下降。
375G 的 P4800X,模拟成内存使用时,与 64G 内存组合时容量为 280G,与 256G 内存组合时容量为316G,比最大容量模式的 320G 略低。
成本相关
2018.9
- P4800X:$3.36/G
- 内存:$10/G
适合的场景
- 大量的顺序读取,例如 OLAP
- 列式读取的数据库或者KV数据库的缓存
- 容器/虚拟机,多租户
- cpu密集型任务
可能适合snappydata或redis等场景(未测试)
不适合的场景
- 内存密集型的任务不适合,内存带宽会成为应用的瓶颈。
- 没有大量并行化(parallelization)的内存随机访问任务。
参考
EXPANSION OF SYSTEM MEMORY USING INTEL®MEMORY DRIVE TECHNOLOGY
apache-spark-optimization-technology-brief
A closer look at Intel Memory Drive Technology (IMDT), with Intel’s Ravikanth Durgavajhala