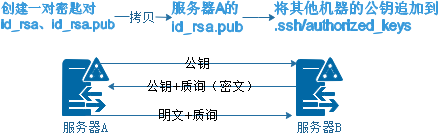
零、SSH密码认证流程
一、HDFS架构
- 简单了解HDFS
- HDFS借鉴了GFS的数据冗余度思想
存在批量的硬盘;【DataNode 数据节点】
HDFS默认冗余度为“3”,就是一份同样数据保存三份;
利用“水平复制”提升上传效率;
以“数据块”作为单位进行数据传输(1.x版本 64m、2.x版本 128m);
存在一个“管理员”进行管控调度【NameNode 名称节点】 - HDFS区别其他分布式文件系统:
①是一个高容错性系统——高容错性(fault-tolerant)
②提供高吞吐量的数据访问——高吞吐量(high throughput)
③廉价机器,成本低——(low-cost)
④超大数据存储——超大数据集(large data set)
- 架构图
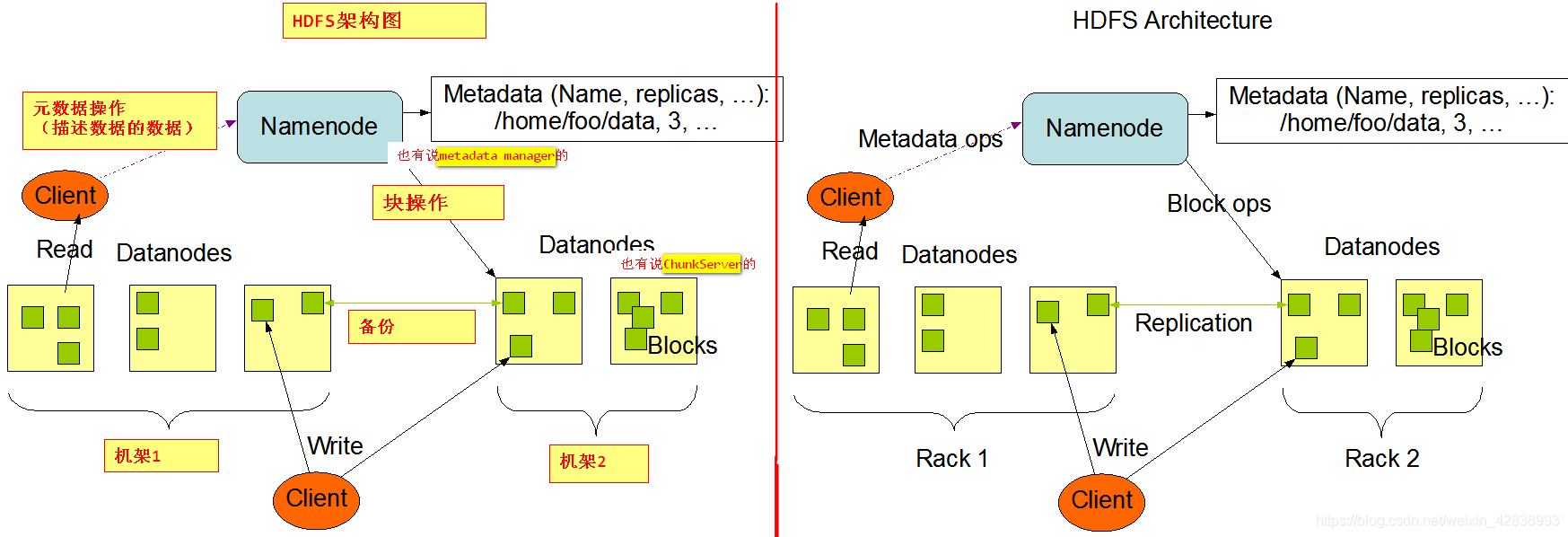
- 名词解释
namenode:管理block的元数据,管理Datanode对块的常规操作,接受来自于客户端的元数据操作,同时响应来自于datanode定期block信息汇报。(耗内存)
【服务对应一台具体的pc机。namenode用来保存文件的元信息;
元信息分两大类:
fsimage(镜像):保存文件的属性信息
editslog(操作日志):记录客户端对hdfs中文家您的写操作日志,便于进行数据恢复和namenode的数据同步
】
datanode:存储块的节点,负责块数据读写操作。(耗磁盘)
secondaryNameNode:此服务不是namenode的备用节点。定期的将namenode上的fsimage和editslog进行何斌,放置editlog过大,导致重启时间过长。
block:128 MB 尺度,切分文件尺度,HDFS是以块为单位存储文件dfs.blocksize= 134217728。
【是hdfs存储数据的基本单元,一个block默认128M,block是打散了分布式各个datanode上,默认每个block块三个副本】
rack:机架,对datanode做物理编排,用于优化存储和计算(优先机架内部通信,备份是到其他机架)
- 思考,为何说 HDFS不擅长存储小文件?
| 文件描述 | Name Node(内存) | Data Node(磁盘) |
|---|---|---|
| 1 个 128 MB文件 | 1个块逻辑 | 128 MB 存储 |
| 10000个小文件合计 128 MB | 10000个块逻辑 | z 存储 |
不适合存储海量的小文件,namenode需要在内存中存储metadata,还量消耗大量内存。
1、小文件过多,会过多占用namenode的内存,并浪费block。
- 文件的元数据(包括文件被分成了哪些blocks,每个block存储在哪些服务器的哪个block块上),都是存储在namenode上的。
HDFS的每个文件、目录、数据块占用150B,因此300M内存情况下,只能存储不超过300M/150=2M个文件/目录/数据块的元数据 - dataNode会向NameNode发送两种类型的报告:增量报告和全量报告。
增量报告是当dataNode接收到block或者删除block时,会向nameNode报告。
全量报告是周期性的,NN处理100万的block报告需要1s左右,这1s左右NN会被锁住,其它的请求会被阻塞。
2、文件过小,寻道时间大于数据读写时间,这不符合HDFS的设计:
HDFS为了使数据的传输速度和硬盘的传输速度接近,则设计将寻道时间(Seek)相对最小化,将block的大小设置的比较大,这样读写数据块的时间将远大于寻道时间,接近于硬盘的传输速度。
三、Hadoop Map Reduce
- MapReduce是一种编程模型。主要是:Map(映射)和Reduce(归约)。
- 它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
函数式编程语言: 由原先的面向对象参数传递的思想,反转到函数到数据侧进行运行。数据通信传递“方法”。
特点:数据不变,代码在网络间传递,提升运行效率。
矢量编程语言: 把任务分成若干阶段,阶段必须逐步完成。
-
概念
MapReduce 是Hadoop当中的一款并行的计算框架 (源自于google Map Reduce),其思想是将一个任务拆分成两个阶段分别为Map阶段和Reduce阶段。无论是Map阶段还是Reduce阶段,所有的计算都是并行执行的。
MapReduce框架充分利用存储节点(datanode)所在的物理主机的内存、CPU、网络、少许磁盘进行数据的分布式计算(即在datanode上再跑些服务,避免资源浪费),本质上在Data Node节点运行的物理主机上再运行一个Node Manager服务 ,该服务用于管理该物理主机上的计算资源(CPU、内存、网络、少许磁盘)。
所有的Node Manager 都要听从Resource Manager 的调度和指挥,Node Manager会向Resource Manager汇报自己资源的占用情况,ResourceManager会根据整个集群计算资源占用情况合理分配计算任务给对应的NodeManager。 -
Map和Reduce
Map阶段:在进行一个任务计算的前期,框架会将任务拆分成若干个小任务(程序计算得到 任务切片),每个小任务会对应一个MapTask,因此第一阶段任务计算并行度由任务切片决定。该阶段MapTask主要完成对数据的归类分析(局部计算) ,并且将计算结果存储在本地磁盘。Reduce阶段:在任务计算前期,框架早已经设置好了第二阶段任务并行度(手动指定),对第一阶段计算的临时结果做数据的汇总 ,得到最终计算结果,并且将结果写到目的地(RDBMS、HDFS等)。
-
例如——计算点击
select sum(1),ip from t_address group by ip;
reduce阶段 Map阶段
言简意赅的说:就是一个group by,一个select
- MapReduce 计算模型 【Map——Shuffle——Reduce】
归类依据,统计的值
Map: 行输入 --- Map 转换 --- (key,value)
-----------------------------------------
Shuffle: 黑匣子
-----------------------------------------
归类依据,统计的值的集合 任意key,任意值
Reduce:(key,value[])--- Reduce 汇总逻辑 ---- (key,value)
#即相同ked的所有record都在一起被同时操作,不同key在不同的group下,可以独立运行。
- wordcount的MapReduce 模型
Input——>Spliting——>Mapping——>Shuffling——>Reducing——>Reducing——>Final result
四、MapReduce任务执行流程
YARN (MapReduce 2)
MapReduce是基于Yarn资源管理框架的产物,Yarn(Yet Another Resource Negotiator)
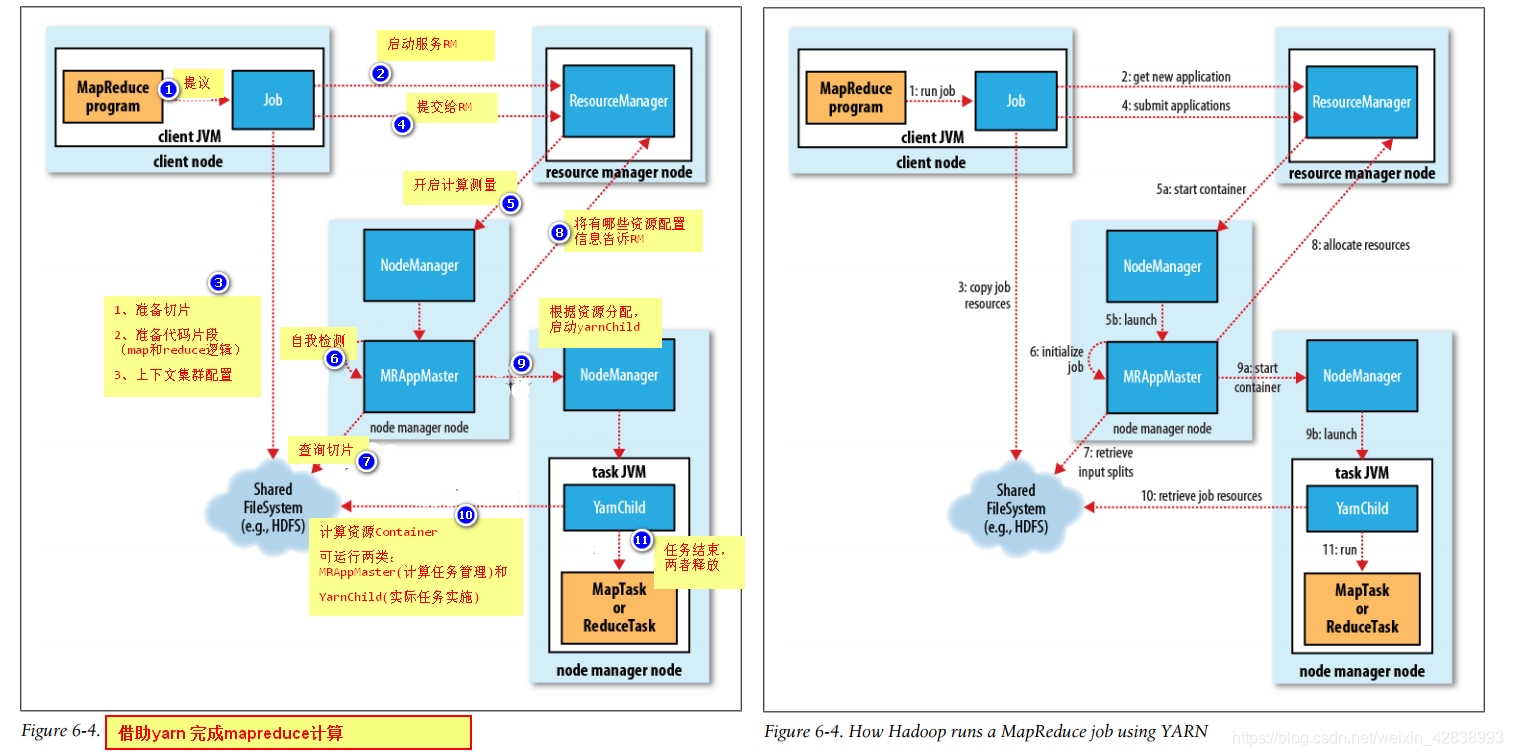
ResourceManager:资源调度中心,接受所有Node Manager 资源Container汇报。
【主要功能接收客户端job请求,协调job所需要所有资源,会产生一个job_id值,和appMaster通信,监听任务开始与结束】
Node Manager:本地资源管理者,管理本地Container,汇报自身信息给Resource Manager。
【运行在各个datanode上,负责RM和AM进行通信。由NM启动各个yarnChild】
Container:是计算资源的抽象 表示一组 内存、CPU、网络占用。(JVM启动参数)
【逻辑上的概念,表示执行所需的内存】
MRAppMaster:一个任务只有一个MRAppMaster监控Yarnchild执行,向ResourceManager 申请计算资源。
【在运行mr的时候会被启动,是由RM在各个NM中指定一个机器启动。负责从hdfs中下载job运行的资源,同时,分发到NM,监听各个yarnChild的运行状态。yarnChild失败,就在其他机器上启动yarnChild】
YarnChild:表示一个计算资源抽象,可能是MapTask或者ReduceTask。
【运行map程序和reduce程序的时候,会启动。负责具体的map程序和reduce程序的执行。同时将自己的运行状态汇报给AM。】
MRAppMaster和YarnChild都是任务执行期间的临时进程,任务执行结束,进程结束,对应的Container资源归还给NodeManager
- 生活中的例子
job:
建筑公司
钢筋,水泥,沙子 — job运行的资料
项目总监:— resourceManager
项目经历:— MRAppMaster(若干包公=工头里面选一个当经理)
包工头:— nodeManager
工人:— yarnChild
map任务
reduce任务
五、MapReduce环境搭建
- 修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> <!--洗牌,上方的黑匣子操作-->
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property>
- 将mapred-site.xml.template 修改成 mapred-site.xml(去掉.template)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 启动Yarn
[root@CentOS ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop-2.6.0/logs/yarn-root-resourcemanager-CentOS.out
CentOS: starting nodemanager, logging to /usr/hadoop-2.6.0/logs/yarn-root-nodemanager-CentOS.out
[root@CentOS ~]# jps
1648 DataNode
1795 SecondaryNameNode
8453 ResourceManager
8537 NodeManager
1533 NameNode
stop-yarn.sh #停止服务
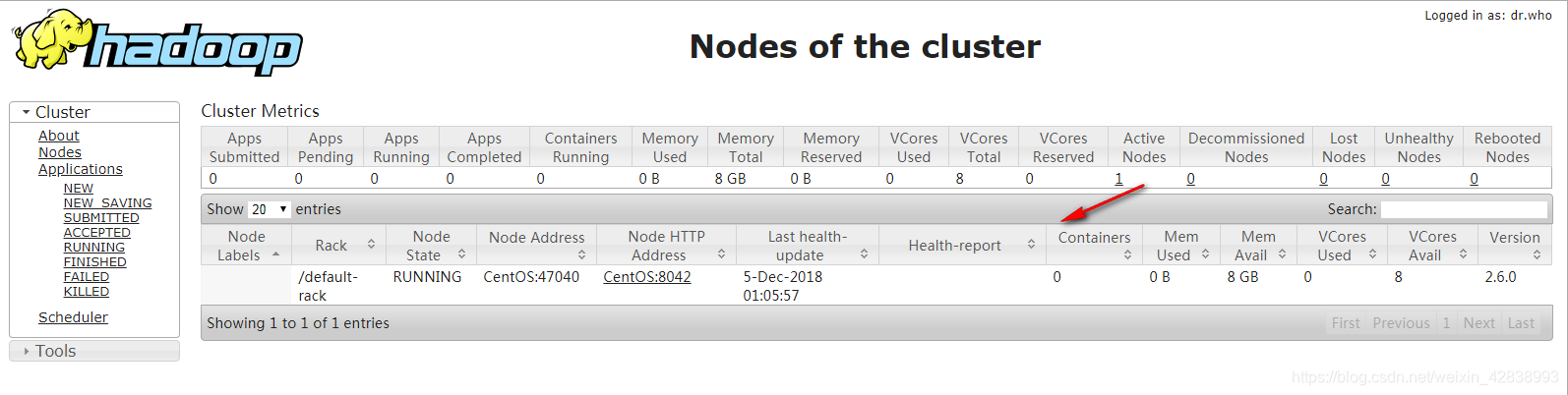
可以查看http://CentOS:8088查看yarn任务列表
六、MapReduce简单的任务执行案例
- 导入依赖
<!--MapReduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<!--HDFS-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
#数据
INFO 192.162.0.1 QQ 2018-10-01 10:10:00
INFO 192.162.104.1 QQ 2018-10-01 10:10:00
INFO 192.162.0.1 QQ 2018-10-01 10:10:00
INFO 192.162.0.1 QQ 2018-10-01 10:10:00
#请使用Map Reduce统计出ip出现的次数的完整代码?
- Map逻辑
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
* KEYIN: 文本行在文件当的中字节偏移量(暂不用)
* VALUEIN:表示一行文本输入(即一行数据)
* KEYOUT:归类依据
* VALUEOUT:统计的值
*
* Created by Turing on 2018/12/4 19:10
*/
public class TestMap extends Mapper<LongWritable, Text,Text, IntWritable> {
//INFO 192.162.0.1 QQ 2018-10-01 10:10:00
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split(" ");
String ip=tokens[1];
context.write(new Text(ip),new IntWritable(1));
}
}
- Reduce逻辑
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
*
* KEYINT/VALUEIN:必须保证和Map端输出类型保持一致(规定)
* KEYOUT/VALUEOUT:根据最终统计需求定义类型
*
* Created by Turing on 2018/12/4 19:24
*/
public class TestReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
- MapReduce封装一个任务!!!
面试点:如何封装一个任务
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* ①封装Job任务对象(需要conf配置)
* ②设置处理数据格式(读入/写出)
* ③设置数据路径(HDFS上 读入和写出)
* ④设置任务处理逻辑 Mapper/Reducer
* ⑤说明Map和Reduce的输出k-v
* ⑥提交任务
*
* 典型的 适配器 设计模式
* Created by Turing on 2018/12/4 19:36
*/
public class CustomJobSubmitter extends Configured implements Tool {
//书写执行代码
public int run(String[] args) throws Exception {
//①封装Job任务对象(需要conf配置)
Configuration conf=getConf();
Job job= Job.getInstance(conf);
job.setJarByClass(CustomJobSubmitter.class); //jar包发布
//②设置处理数据格式(读入/写出)
job.setInputFormatClass(TextInputFormat.class); //注意jar包选择长的
job.setOutputFormatClass(TextOutputFormat.class);
//③设置数据路径(HDFS上 读入和写出)
Path src = new Path("/t_time");
TextInputFormat.addInputPath(job,src);
Path dst = new Path("/demo/results"); //必须为null,即结果必须是自己自动生成
TextOutputFormat.setOutputPath(job,dst);
//④设置任务处理逻辑 Mapper/Reducer
job.setMapperClass(TestMap.class);
job.setReducerClass(TestReduce.class);
//⑤说明Map和Reduce的输出k-v
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//⑥提交任务
//job.submit();
job.waitForCompletion(true); //执行打印进程任务--类似日志
return 0;
}
//作为执行入口
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmitter(),args);
}
}
应用场景:支付宝年终账单统计,模糊推荐
七、任务发布
- jar发布(用的最多)
//否则 MapReduce 框架找不到Mappre和Reducer
job.setJarByClass(CustomJobSubmitter.class);
- 上传jar文件,并执行
[root@CentOS ~]# ll
total 347184
-rw-------. 1 root root 1101 Dec 3 23:54 anaconda-ks.cfg
-rw-r--r--. 1 root root 4692 Dec 4 19:57 day2_MapReduce-1.0-SNAPSHOT.jar
-rw-r--r--. 1 root root 180217413 Aug 2 2016 hadoop-2.6.0_x64.tar.gz
-rw-r--r--. 1 root root 8815 Dec 3 23:54 install.log
-rw-r--r--. 1 root root 3384 Dec 3 23:53 install.log.syslog
-rw-r--r--. 1 root root 175262413 May 8 2018 jdk-8u171-linux-x64.rpm
-rw-r--r--. 1 root root 162 Dec 5 03:21 t_time
start-dfs.sh #不要忘记启动HDFS
#且要将t_time上传到hdfs文件系统中
[root@CentOS ~]# hadoop jar day2_MapReduce-1.0-SNAPSHOT.jar com.abc.CustomJobSubmitter #权限定名
运行中,查看进程,可以看到会达到2G或3G,消耗的内存分配给了MRAppMaster和YarnChild
运行结束后,又再释放资源
hdfs dfs -rm -r -f /demo/results #执行太快,没看清,可以删除文件再看一遍
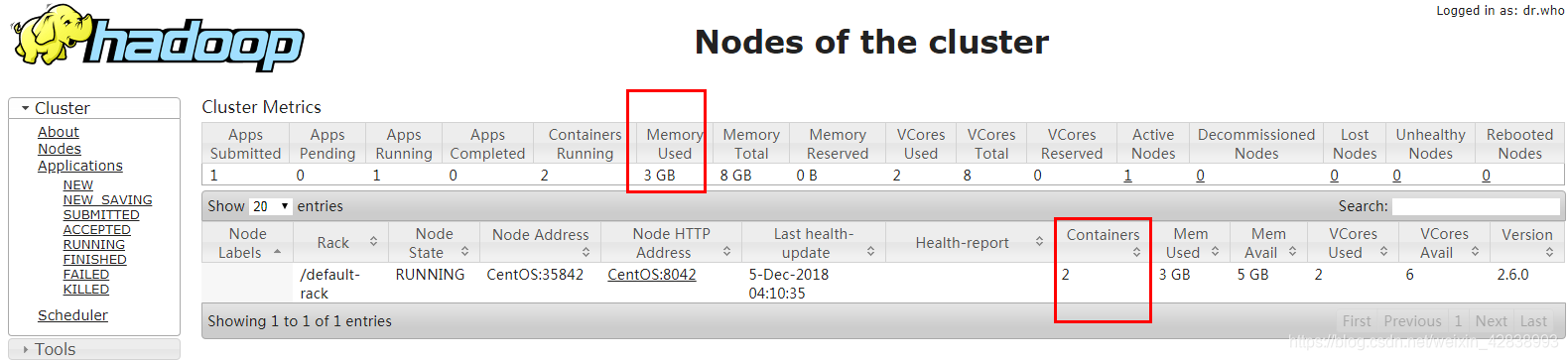
- 运行成功
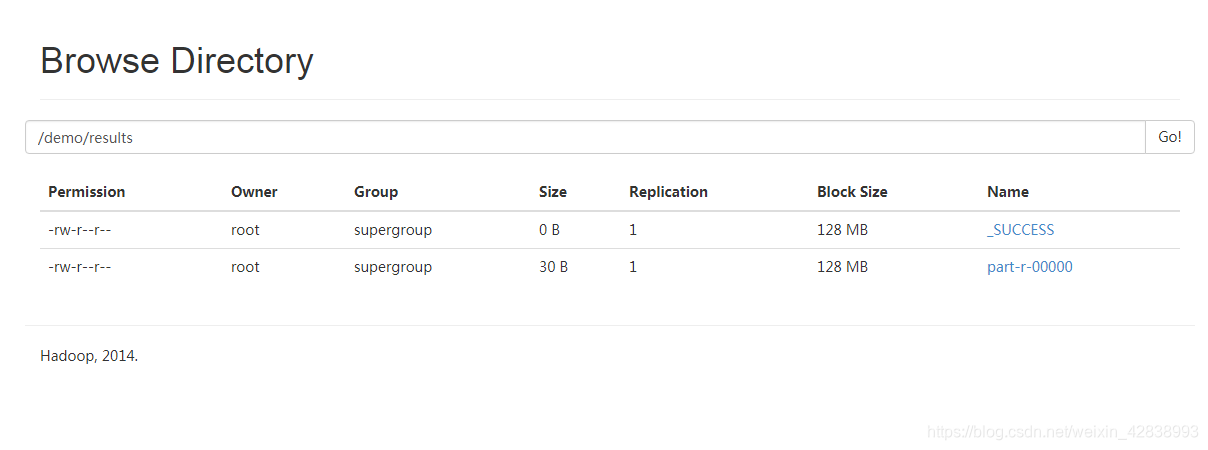
#命令查看
[root@CentOS ~]# hadoop fs -cat /demo/results/part-r-00000
192.162.0.1 3
192.162.104.1 1
[root@CentOS ~]#
- 本地仿真(推荐 学习测试)
用户可以不依赖Yarn环境测试自己的本地代码,只需要修改路径参数file://xxx直接执行代码,会抛出异常:NativeIO$Windows
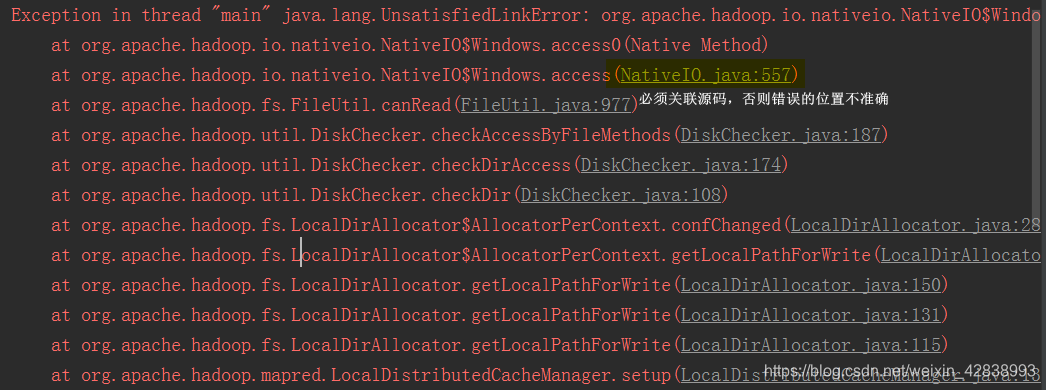
解决方案,对当前NativeIO中的access方法做短路。
【原理:优先执行用户代码类加载器,再加载系统加载器,利用类加载器,去间接修改源码】
加上log4j达到日志的目的。
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
// return access0(path, desiredAccess.accessRight());
}
- 跨平台发布
用户在windows上提交代码,任务是在CentOS上执行。
- 拷贝core|hdfs|yarn|mapred-site.xml到系统的resource目录
- 添加配置信息到mapred-site.xml,开启跨平台提交
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
- 使用maven的package指令打包项目
- 修改提交代码添加以下内容
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("mapred-site.xml");
conf.addResource("yarn-site.xml");
conf.set("mapreduce.job.jar","file:///xxx.jar的路径信息");
其他、
- CAP理论
分布式系统(distributed system)正变得越来越重要,大型网站几乎都是分布式的。
分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
目前,CAP(Consistency一致性、Availability可用性、Partition-tolerance分区可容忍性)理论普遍被当作是大数据技术的理论基础。同时,根据该理论,业界有一种非常流行、非常“专业”的认识,那就是:关系型数据库设计选择了C(一致性)与A(可用性),NoSQL数据库设计则不同。其中,HBase选择了C(一致性)与P(分区可容忍性),Cassandra选择了A(可用性)与P(分区可容忍性)。
该说法现在似乎已经成为一种经典认知,无论是初学大数据技术,还是已经有了相当经验的技术人员,都将其奉为真理。大家大概是认为,从CAP这样著名的理论推导出来的结论,当然是权威而又正确的,最起码在形式上感觉是专业而又严肃的。有人甚至还将这种认知画成一个三角形图,三个顶点分别是C、A、P,三条边分别是关系型数据库、HBase与Cassandra,这样一来,CAP理论就显然更加神圣了。

- 协同过滤算法
提示:机器学习与数据挖掘的区别?
数据挖掘是从已有的历史数据中挖掘、总结知识,这个知识是已经碎片化存在的,和你是否进行挖掘无关。比如你看了很多电影,你对什么类型电影感兴趣你自己心里很清楚,而我并不知道。但是当你一五一十的把你看过的全部电影都跟我讲述一遍后,我便从你看过的电影中了解到你的电影偏好。这个电影偏好便是知识,知识是需要去挖掘去总结,才能更直观的被人所了解。
机器学习同样是基于已有的历史数据,但是不同的是机器学习是从已有的知识中产生新的知识。这个知识可能是推荐、预判等。比如,我在了解了你的电影偏好后,我可以迅速给你推荐你没看过但是感兴趣的电影;了解了历年每个时间段机票的价格,我可以预判未来某个时刻机票的大致情况。
经常有人(包括我自己)会混淆数据挖掘与机器学习的内涵。现在看来,机器学习是在数据挖掘基础之上的。数据挖掘把碎片化的知识规整在一起,机器学习是从碎片化知识中产生新知识。
- 推荐算法是机器学习算法的一种。
推荐算法有很多,其中协同过滤算法便是其中最常用的一种。什么是协同过滤算法呢?直白点说,就是你不知道怎么选择,大家来帮你选择。这个大家可能是用户,和你有相同偏好的人帮你选择你没有而他们有的;也可能是物品本身,和你历史物品相似的物品把自己推荐给你。对应的算法分类也就是基于用户的协同过滤算法和基于物品的协同过滤算法。前述可知,基于用户的协同过滤算法的关键是找到相同偏好的用户,找到了偏好最近的几个用户,他们偏好的物品便是要给你推荐的目标。而基于物品的协同过滤算法的关键是计算其它物品和历史物品的相似度,相似度最近的几个物品便是要推荐的物品。(换句话说,协同过滤算法的关键是解决相似度问题)。
提示:如何理解用户偏好和用户相似度?
举个例子,四川人喜欢吃辣的食物就是一种关于饮食的用户偏好。在饮食方面,四川人A和四川人群的饮食偏好程度 > 四川人A和湖南人群的饮食偏好程度 > 四川人A和湖北人群的饮食偏好程度。某人和某XX在某方面的偏好程度,也可以描述为用户相似度。请四川人吃饭点辣的食物,这就是基于用户的协同过滤算法的生活场景之一。见下图,帮A推荐食物的不是湖南人、不是湖北人,而是四川人这个集体。因为A和四川人群在饮食方面的用户相似度最高。
提示:如何理解物品相似度?
理论上,两个物品在某方面的属性或表现相似,就可以说两个物品在某方面是相似的。换句话来说,判断两个物品是否相似,必须找到一个评判的依据。这个依据是随意的,可以从物品内在的性质、外在的表现或者社会化的属性。比如,小明喜欢A、B和C,小丽喜欢A、C和D,小张喜欢B、E和F。观察三人拥有的物品,可以知道拥有A的也拥有C,可知AC的关联程度很高,即AC相似度很高。如果此时我已经拥有A,请问给我推荐什么商品最合适,显然应该把C推荐给我。这种人们拥有商品的关联程度是一种社会化的属性,是由人们的行为而产生的社会化结果。