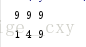列表生成式
生成器(边循环边计算机制,节省空间)
函数式编程
高阶函数
Map/reduce
Filter
Sorted
返回函数
列表生成式
import os
L1=[x*x for x in range(1,11)]
print L1
M=[x*x for x in range(1,11)if x%2==0]
print M
N=[m+n for m in 'ABC' for n in 'XYZ'] 双层循环
print N
F=[d for d in os.listdir('.')]查询python_workspace 下的所用文件
print F
D1={'x':'A','y':'B','z':'C'}
for k,v in D1.iteritems():
print k,'=',v
D2={'x':'A','y':'B','z':'C'}
print [k+'='+'v' for k,v in D2.iteritems()] 输出字典中的key与value
A=['Hello','Nihao']
print [s.lower() for s in A]
L2 = ['hello', 'world', 18, 'apple', None]
print [s.lower() if isinstance(s, str) else s for s in L2] 将list中的字符全部转为小写输出

生成器(边循环边计算机制,节省空间)
g=(x*x for x in range(10))将列表生成式的[]改为(),为generator
print g.next()通过generator的next()方法打印
for n in g: 通过for循环打印
print n
def fib(max):
n,a,b=0,0,1
while n<max:
print b
a,b=b,a+b
n=n+1
fib(6)
def fib_gen(max):
n,a,b=0,0,1
while n<max:
yield b 将fib函数改为一个生成器(定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator)
a,b=b,a+b
n=n+1
for n in fib_gen(6): #一般是使用for循环来查询,而不用next()方法
print n

函数式编程
1.在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。
而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。
2.函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
3.函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言
高阶函数(Higher-order function)(一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数)
def add(x,y,f): return f(x)+f(y) print add(-5,4,abs)
Map/reduce
map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回
def f(x):
return x*x
L=map(f,[1,2,3,4,5,6,7,8])
print L
M=[]
for n in [1,2,3,4,5,6,7,8]:
M.append(f(n))
print M
S=map(str,[1,2,3,4,5,6,7,8])
print S

Reduce()reduce把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
def add(x,y):序列求和
return x+y
print reduce(add,[1,2,3,4,5,6])
def fn(x,y): 把序列1,2,3,4,5,6转换为整数123456
return x*10+y
print reduce(fn,[1,2,3,4,5,6])
def char2num(s): 将字符串str转化为int
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
print reduce(fn,map(char2num,'12345'))
def str2int1(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
return reduce(fn, map(char2num, s))
print str2int1('1324234323')
def str2int2(s):
return reduce(lambda x,y: x*10+y, map(char2num, s))
print str2int2('12345')
def normalize(s): #把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字
return(s[0].upper() + s[1:].lower())
print map(normalize, ['adam', 'LISA', 'barT'])
def times(x, y):# 接受一个list并利用reduce()求积
return x * y
def prod(t):
return reduce(times,t)
print prod(range(1,5))

Filter(filter 函数用于过滤序列) filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
def is_odd(n): 一个list中,删掉偶数,只保留奇数
return n%2==1
print filter(is_odd,[1,2,4,5,6,9,10,11])
def not_empty(s): 把一个序列中的空字符串删掉
return s and s.strip() s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符
s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
这里的rm删除序列是只要边(开头或结尾)上的字符在删除序列内,就删除掉(
print filter(not_empty, ['A', '', 'B', None, 'C', ' '])
def not_prime(x): 删除1~100的素数
if x == 1: return True
dividend = range(2, int(x ** 0.5 + 1))
return not all(map(lambda t: x % t, dividend)) all是一个函数,用于判断是否数组中所有元素都为真(非零或true)lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数
print filter(not_prime, range(1, 101))

Sorted排序
# -*- coding: utf-8 -*-
L=sorted([23,1,34,3,25,21])
print L
def reversed_cmp(x, y):#倒序排序
if x > y:
return -1
if x < y:
return 1
return 0
M=sorted([23,1,34,3,25,21], reversed_cmp) sorted()函数也是一个高阶函数,它还可以接收一个比较函数来实现自定义的排序
print M
print sorted([36, 5, 12, 9, 21], lambda x, y: y - x)
print sorted([36, 5, 12, 9, 21])[::-1]
print sorted(['dsa','ADD','23','dfeeeee'], lambda x, y: cmp(y,x)) cmp(x,y) 函数用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
S=sorted(['bob', 'about', 'Zoo', 'Credit'])
print S
def cmp_ignore_case(s1, s2):
u1 = s1.upper()
u2 = s2.upper()
if u1 < u2:
return -1
if u1 > u2:
return 1
return 0
N=sorted(['bob', 'bbout', 'Zoo', 'Credit'], cmp_ignore_case)
print N
返回函数
函数作为返回值(高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回)
我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力 def calc_sum(*args): ax = 0 for n in args: ax = ax + n return ax print calc_sum(1,2,3,4) def lazy_sum(*args): def sum(): ax = 0 for n in args: ax = ax + n return ax return sum f=lazy_sum(1,2,3,4) print f() f1=lazy_sum(1,2,3,4) f2=lazy_sum(1,2,3,4) print f1==f2 当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数,f1()和f2()的调用结果互不影响,
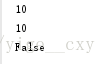
闭包
def count1():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count1() 返回的函数并没有立刻执行,而是直到调用了f()才执行
print f1(),f2(),f3() 返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9
def count2(): 返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
fs = [] 如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变
for i in range(1, 4):
def f(j):
def g():
return j*j
return g
fs.append(f(i))
return fs
f4, f5, f6 = count2()
print f4(),f5(),f6()