一、MongoDB副本集概要
- 什么是MongoDB副本集?
副本集是一组mongodb进程,它维护了同样的数据集。副本集提供了信息冗余和高可用,是所有生产部署的基础。
客户端,读写操作主节点,然后将数据复制到副节点中。
- 节点
-
Primary Node 主节点,一个副本集只能有一个主节点,主要作用接受客户端所有写操作(默认情况下,也可以读取数据),并记录主节点操作日志,副节点复制主节点日志,用其同步数据。
-
Secondary Node 副节点,复制主节点的操作,并同步其数据,实际上副节点是主节点数据的备份。如果主节点挂掉的话,剩余的副节点会触发选举算法,将其中的一个副节点,选举为主节点。
-
Replication 通信机制
-
Heartbeat 心跳检测,主副、副副间都要心跳检测
二、搭建MongoDB副本集(Replication)
主节点中插入一条数据,副节点当中查看是否有同步数据
- 准备工作,并启动起来三个服务
至少3台服务器
准备3份数据存放目录
//bin目录下,运行server,当作主服务器
./mongod --port 28000 --dbpath=/data/node1/ --bind_ip_all --replSet rs
//再分别启动两个副服务器
./mongod --port 28001 --dbpath=/data/node2/ --bind_ip_all --replSet rs
./mongod --port 28002 --dbpath=/data/node3/ --bind_ip_all --replSet rs
- 副本集初始化(使用客户端连接任意Mongo Server)
关闭防火墙
./mongo 192.168.153.136:28000 //连接上一个服务
//# 初始化副本集(注意:_id的名字应该和启动参数 `--replSet` value一致)
rs.initiate( {
_id : "rs",
members: [
{ _id: 0, host: "192.168.153.136:28000" },
{ _id: 1, host: "192.168.153.136:28001" },
{ _id: 2, host: "192.168.153.136:28002" }
]
})

rs.status() //查看副本集状态 "stateStr" : "PRIMARY" //主节点、"SECONDARY" //副节点
- 测试副本集数据同步
先再主节点,插一条数据看看
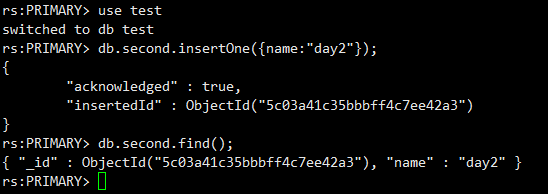
连接到其他server
./mongo 192.168.153.136:28001
//查看时,报错,"errmsg" : "not master and slaveOk=false",
- 原因是因为副本集中默认使用主节点读写数据,副节点只做数据备份,不参与读操作。
db.getMongo().setSlaveOk() //开启副节点读功能
- 高可用?选举算法,选副为主
低版本有主从集群,高版本使用副本集代替
//停掉主节点服务,再在测试状态,rs.status()
//原主节点:"stateStr" : "(not reachable/healthy)"
//其他节点,有一个副节点变成主节点
三、MongoDB基于副本集完成读写分离
利用Mongo副本集可以搭建一个高可用的集群环境。但是在默认情况下,读写操作都在Primary主节点上进行,在高并发的环境下,Primary的负载较大。那如何解决这个问题呢?,我们可以利用读写分离,就是让,Primary负责写操作,Secondary负责读操作,分摊Primary的压力。
主写副读
- MongoDB驱动程序支持的5中读优先级模式
| 读取首选模式 | 使用 |
|---|---|
| primary | 默认,从主节点读取数据 |
| primaryPreferred | 在主节点不可用时,从副节点读取数据 |
| secondary | 所有的读操作,从副节点读取数据 |
| secondaryPreferred | 在副节点不可用时,从主节点读取数据 |
| nearest | 从网络延迟最小的节点获取数据 |
- 配置
db.getMongo().setSlaveOk() /所有副节点开启可读
- 代码
- Spring Data MongoDB
在这里我们使用Spring Data提供的MongoTemplate操作ReplSet(类似Spring Data Redis) - 依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-mongodb</artifactId>
<version>2.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>
- 配置文件 applicationContext.xml
四、MongoDB分片集(Sharding)
-
Sharding(分片)是一种方法:
分片是一种支持海量数据存储并进行高吞吐量操作的方式。(mysql的分库分表也是分片的体现)
在大数据集和高吞吐量操作的情况下,对单一的服务器硬件要求较高(一般要求算力优异的CPU提供运算能力,RAM或者DISK也要足够大)。
传统的方式就是对服务器硬件进行升级,而这样的做的成本往往很高(垂直扩展)。
而MongoDB提供的分片,其实上就是使用多数的廉价服务器构建成集群,提供海量的数据存储以及并行计算的能力(水平扩展)

-
分片集群的组件
- shard server
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障。 - config server
顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。 - mongos server
数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
与springboot整合:http://www.gaozhy.cn/blog/2018/04/12/springboot-mongodb/
五、MongoDB总结
- mongoDB适合存储:海量数据、变化的数据、json形式数据
- 使用场景:日志、物流信息、商品信息、订单信息、全文检索、巨额查询、地理位置查询(例:附近情况)
- 副本集和分片集 会搭建,了解即可(非重点,是加分项)