一、基础环境搭建
详情请见另一篇博客:https://mp.csdn.net/postedit/83112439
二、SSH设置
1、创建hadoop用户,以及权限设置
为所有节点创建hadoop用户,以后操作均在该用户下操作,操作如下:
1、useradd hadoop
2、passwd hadoop
3、sudo vim /etc/sudoers修改内容如下:
1、root ALL=(ALL) ALL
2、hadoop ALL=(root) NOPASSWD:ALL修改完按esc,键入:wq保存文件并退出。
然后切换到hadoop用户:
1、su hadoop2、修改hosts文件,构建映射关系
一般,在访问局域网中的其他服务器时,需要输入难以记住的IP地址。因此,为了方便访问,我们可以在hosts文件中建立IP映射关系,这样以后访问的时候直接输入服务器名就可以了。(所有节点设置相同)
1、sudo vi /etc/hosts在文件尾部添加如下几行:
1、192.168.1.100 master
2、192.168.1.101 slave1
3、192.168.1.102 slave2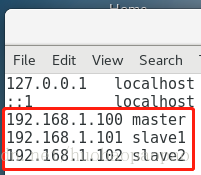
3、ssh设置
为使节点间双向免密登录,需进行如下操作:
1、ssh-keygen -t rsa //生成master的rsa密钥,设置按回车取默认值
2、cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //将生成的rsa追加写入授权文件
3、chmod 600 ~/.ssh/authorized_keys //给授权文件权限(只有属主有读写权限)
4、ssh maste r //进行本机ssh测试
5、sudo scp ~/.ssh/id_rsa.pub hadoop@slave1:~/ //将master上的authorized_keys传到其他slave节点
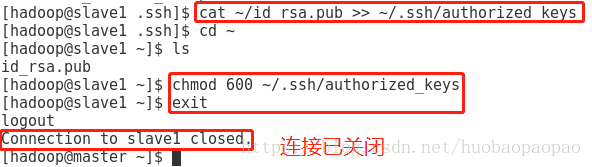
6、$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //登陆到slave1操作:$ssh slave1输入密码登陆
7、chmod 600 ~/.ssh/authorized_keys //修改authorized_keys权限(只有属主有读写权限)
8、exit //退出slave节点
9、ssh slave1 //进行免密ssh登陆测试(以slave1为例)
三、hadoop安装配置
0、装前配置
所有节点关闭防火墙以及selinux。
1、sudo systemctl stop firewalld.service //关闭
2、sudo systemctl disable firewalld.service //开机禁用
3、sudo vim /usr/sbin/sestatus //修改sestatus文件在文件中找到SELinux status参数并设定为关闭状态:
SELinux status: disabled1、hadoop安装
操作顺序:在master节点进行hadoop安装配置,之后scp到其他节点
下载Hadoop(选择自己需要binary的版本,或使用文中版本)压缩包至主机,使用Xshell(下载地址在基础环境搭建里)传到master的~/用户主目录下。
tar -zxvf ~/hadoop-2.8.1.tar.gz -C ~/hadoop/2、hadoop的master节点配置
修改~/hadoop/etc/hadoop目录下的配置文件,core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。
1、cd ~/hadoop/etc/hadoop
2、vi core-site.xml/hdfs-site.xml/mapred-site.xml/yarn-site.xml/slaves //这几个文件需轮流修改配置文件内容:
1、core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
2、hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
3、mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4、yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
5、slaves
slave1
slave2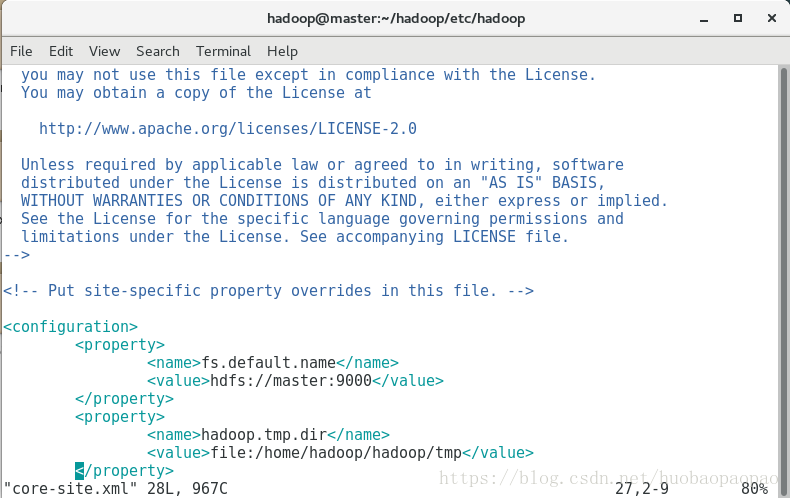
3、Hadoop的其他节点配置
由于之前已经配置过免密ssh登录节点机,故配置好的hadoop可直接由master传到其他slave节点上。
1、scp -r ~/hadoop hadoop@slave1:~/ //复制hadoop文件至slave1(其他节点类似)4、Hadoop环境变量配置
配置环境变量需修改~/.bashrc文件,添加行(以master节点为例,其他节点类似):
#hadoop environment vars
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使环境变量生效:
1、source ~/.bashrc //使环境变量生效
四、Hadoop启动
1、hadoop namenode -format //格式化namenode
2、start-all.sh //启动hadoop
3、jps //启动后需在各节点查看启动情况master节点jps查看启动情况:
- Jps XXXX(线程数,下同)
- ResourceManager XXXX
- SecondaryNameNode XXXX
- NameNode XXXX
slave节点jps查看启动情况:
- Jps XXXX
- NodeManager XXXX
- DataNode XXXX
浏览器输入127.0.0.1(或节点ip):50070,查看管理界面。
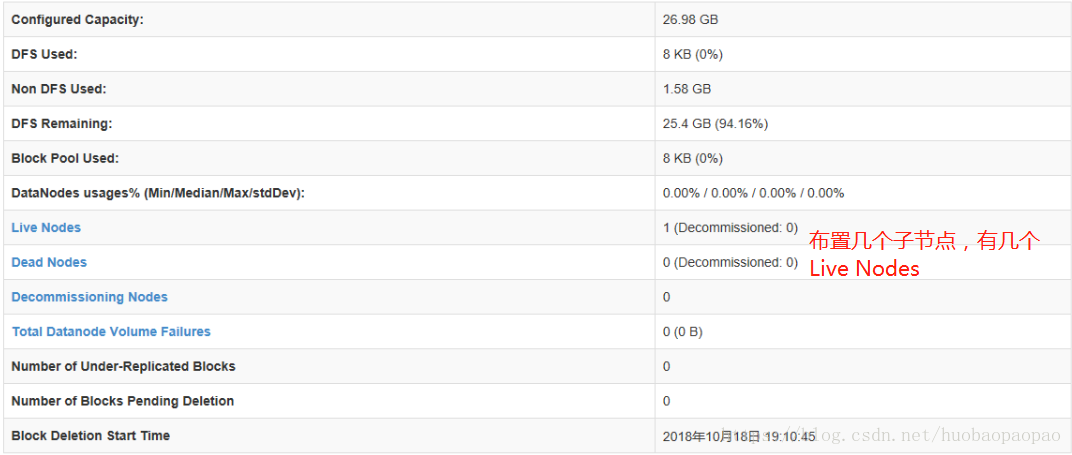
问题Tips:
布置过程中有可能出现There are 0 datanode(s) running and no node(s) are excluded in this operation这样的问题,删除dfs.namenode.name.dir设置的(file:///dfs/data)目录下的current 文件夹即可解决。(原因:地址丢失)
五、hadoop测试
使用mapreduce实现wordcount(单词计数),证明部署正确
1、echo "hadoop test." >> hadoopTest //生成文件hadoopTest
2、hadoop fs -mkdir /hadoopTestInput //创建hadoop文件夹hadoopTestInput
3、hadoop fs -put hadoopTest /hadoopTestInput //将文件hadoopTest上传至hadoopTestInput文件夹
4、hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /hadoopTestInput /hadoopTestOutput //执行wordcount程序,并将结果放入hadoopTestOutput文件夹(/hadoopTestOutput文件夹必须是没有创建过的文件夹)
5、hadoop fs -ls /hadoopTestOutput //查看生成文件夹下的文件
1、hadoop fs -cat /hadoopTestOut/part-r-00000 //在hadoopTestOut/part-r-00000可以看到程序执行结果
参考:http://hadoop.apache.org/docs/r1.0.4/cn/cluster_setup.html
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html