评估+设计杂谈
评估模型(假设函数)
当要对我们的预测误差作故障排除,不外乎通过以下这几种方式:
- 增加更多的训练样本
- 减少特征种类
- 增加特征种类(增加额外的特征或者多项式特征 )
- 增加或减少惩罚参数
但是如何确定应该采取的方式?
训练集+测试集
训练得到的假设函数可能对于训练集来说误差低,但是在预测新样本时不够准确(过拟合),因此,我们需要把训练样本分为训练集和测试集,比例为7:3。
所以评估过程为:
- 采用训练集训练得到假设函数
- 计算测试集在假设函数下的代价函数(计算测试集的平均误差)
测试集的误差
-
线性回归
-
逻辑回归
2.1 分类误差 0/1
上式将错误分类用0或1进行了标识,所以测试集的平均误差为:
上式揭示了根据测试集的输入特征错误分类的比例。
2.2 代价函数
训练集+验证集+测试集
如果有多个模型可以选择,例如可以选择多个多项式次数不同的模型,那么,可以通过验证集对模型进行选择,再利用测试集评估泛化误差。(如果只有训练集和测试集,用测试集同时进行模型选择和误差评估是不合理的,因为通过模型选择后,测试集已经与模型相匹配,很难再用于泛化评估)
训练集、验证集和测试集的比例为6:2:2。
诊断:偏差 vs 方差
高偏差指欠拟合;高方差指过拟合。
- 多项式次数与偏差和方差诊断的关系

随着假设函数中多项式次数(特征)的增多,对于训练集的误差越来越小,而对于验证集的误差先降后升。
训练集误差和验证集误差均高且近似相等时诊断为高偏差;
训练集误差低,而验证集误差高时诊断为高方差。
- 正则化和偏差/方差
正则化参数 过小时,有可能过拟合,过大时,有可能欠拟合。
随着 增大,对于训练集的误差越来越大,而对于验证集的误差先降后升。
训练集误差和验证集误差均高且近似相等时诊断为高偏差;
训练集误差低,而验证集误差高时诊断为高方差。
可以通过以下步骤选择合适的
:
2.1 生成若干个
,如
2.2 生成一系列模型,对应不同的
2.3 通过训练集训练得到各模型的模型参数
2.4 通过验证集计算验证误差(计算时忽略代价函数中的正则项),并选出验证误差最小的模型作为最优模型
2.5 将测试集应用于最优模型以预测泛化性能。
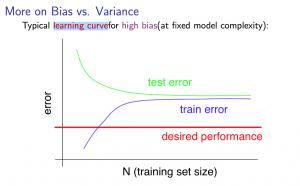
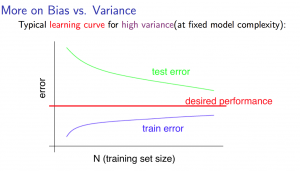
- 学习曲线(训练样本/训练集数量与偏差和方差)
当训练样本增多,训练集的误差越来越大,而验证集的误差却越来越小。在训练样本数量达到一定程度后,训练集和验证集的误差近似。
-
如果增加训练样本的情况下,训练集的误差和验证集的误差不变,且均高于理想水平,则有可能高偏差(同时可见,增加训练样本不能解决高偏差的问题)PS:快速聚拢的就是高偏差,因为如果是正常情况,则两种误差应当相似,如果一开始验证集误差比训练集误差高,则要么高偏差,要么高方差
-
如果在增加训练样本的情况下,验证集的误差平缓下降,训练集的误差平缓上升,且它们之间有明显的差距,则有可能高方差(同时可见,增加训练样本可以解决高方差时,它们向理想水平靠拢)PS:训练样本增加到一定程度后,两者之间在很长一段期间内还保持一定差距,那就说明是高方差了
诊断后的调整
调整方式可列举如下:
- 增加训练样本 - 高方差
- 减少特征 - 高方差
- 增加特征(额外的特征或增加多项式次数) - 高偏差
- 减小 - 高偏差
- 增加 - 高方差
评估神经网络
过拟合/欠拟合
- 一个简易的神经网络倾向于欠拟合(计算量小)
- 一个大型的神经网络倾向于过拟合(计算量大;可以使用正则化来解决过拟合)
平衡偏差和方差
- 利用训练集,从训练包含一个隐藏层的神经网络依次到训练包含若干隐藏层的神经网络
- 利用验证集,挑选表现最好(误差最低)的神经网络
无论是对于模型还是神经网络来说,低阶多项式意味着高偏差低方差,高阶多项式意味着高方差低偏差,因此,在实际当中,更希望找到平衡偏差和方差的模型,泛化性能不错,同时也能够比较好的拟合数据。
设计杂谈
邮件分类
- 选择输入特征
- 理论上,用成千上百的单词作为输入特征,如果邮件样本中存在输入特征中指示的单词,则对应的输入特征为1,否则,对应的输入特征为0。
- 实际中,在邮件样本里遍历所有单词,找出其中使用频率最高的作为特征(一般找到1万到5万个单词)。
- 建立垃圾邮件分类器
2.1 如何减少误差
- 收集更多的数据,比如"honeypot"计划,用假的邮箱地址泄露给发垃圾邮件的人,那么就能收到大量的垃圾邮件来锻炼学习算法
- 基于邮件头信息(发件人、服务器、邮件标题等)、正文扩展(单词的词性变化,单复数,名词形容词,大小写)创建复杂的特征
- 使用复杂的算法去检测误写(垃圾邮件故意拼成b00k,m0rtgage,med1cine,w4tches等;使用大量特殊的标点符号)
误差分析(作用于验证集)
推荐方法
- 先从简单的算法开始训练得到模型,然后在验证集中验证。
- 画出学习曲线去考虑增加样本,增加特征是否有帮助
- 人为检查算法应用出错(比如应当输出y=1的,结果输出了y=0)的实例(在验证集中),看看你是否识别到关于出错的实例倾向于哪种类型
示例
比如验证集中有500个样本,结果有100个被误判,然后人工分析这100个误判的样本,然后基于以下因素分类:
- 这些误判的邮件分别是什么类型
- 什么线索(特征)能够帮助算法将他们准确分类
数值评估
- discount、discounts、discounted、discounting视为同一个单位吗
- semming 和 porter stemmer算是同一个意思的词吗
利用词干提取软件可以实现,将多个形态的单词视为一个,但是有可能误判,比如universe和university。
因此,在实际中,应该采用交叉验证,验证不用词干提取与使用词干提取的算法的错误率有何差异。
偏斜类
偏斜类指的是在分类问题中,样本的类型偏极端化,比如y=1的样本很少,但y=0的样本却很多。
这样的话,用分类预测准确率(预测对了的样本数量除以全部样本)来衡量算法是否足够好是不合理的,因为在样本中y=1的情形很少时,有可能模型很差也能得到不错的预测准确率,比如说虽然模型只能给出y=0的预测,但因为样本里本来y=1的情形就少,反而还能得到不错的准确率。
查准率
(对预测患有癌症的病人(y=1),有多大把握预测准确)
查准率为分类y=1在算法中的预测准确率,等于预测y=1正确的样本的数量除以预测结果为y=1的样本的数量。
召回率
(如果所有病人都有癌症(y=1),怎么评估是否正确检测他们都得了癌症)
召回率为分类y=1在实际中的预测准确率,等于预测y=1正确的样本的数量除以实际上y=1的样本的数量。
查准率和召回率都能用于解决在偏斜类情况时难以评估算法模型的问题(y=1是少数情况,y=0是多数情况时)。
平衡查准率和召回率
如果提高预测的可信度,可以改变判断准则,比如:
但这样存在高查准率,低召回率,预测范围小了,更准确了,但漏网之鱼也多了。
如果宁可预测错也不能放过(比如不想放过每一名可能患上癌症的病人),可以:
但这样存在低查准率,高召回率,预测范围大了,更模糊了,但错误也也更多了。
综上,实际中,查准率与召回率的关系大概如下图:
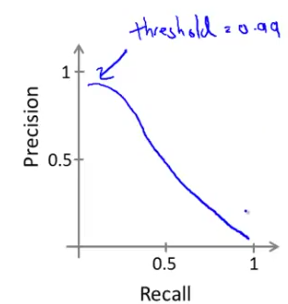
上图中,横坐标为召回率,纵坐标为查准率。
评估度量值
-
取查准率P和召回率R的平均值是不可取的,因为无论何种情况,它们的平均值是相近的,如上图。
-
可取F值(可称为F1值), ,F值越大,证明两者平衡越好,证明设置的判断y分类的临界值对于 来说越合理。
PS:在验证集上进行上述评估度量。
算法悖论
在训练样本规模极大化时,劣化算法表现出的性能要比高等算法好。
前提是,输入特征x要能够准确预测y(衡量标准:人类专家是否能够根据x预测y)
- 先使用多特征多隐藏层网络来保证低偏差
- 再通过大量训练样本保证低方差。