Python爬虫框架Scrapy介绍加实战项目
Scrapy框架是异步处理框架,可配置和可扩展程度非常高,是Python中使用最广泛的爬虫框架,这个框架非常的强大,几乎能用来配合任何爬虫项目。
项目要求:爬取腾讯招聘上的招聘信息(链接: link.)
爬取数据要求:需要爬取,职位名称、职位链接、职位类别、招聘人数、工作地点、发布时间
简单介绍一下楼主的的环境 python3.6.4 + Windows +Anacodnda 4.4.10
1.开始一个 Scrapy 项目
安装 Scrapy : 在Windows中使用Anacodnda安装是最方便的,不知道Anacodnda的自己百度
Anacodnda中安装命令:conda install scrapy
cmd::建议安装pip 使用 pip install Scrapy安装项目 (注意权限问题)
Linux环境下:sudo pip3 install Scrapy (需要下面配置响应的依赖环境)
Mac OS:下载安装包,配置环境变量
在安装成功后就可以开始自己的第一个Scrapy项目
在(Anacodnda)终端命令下输入:scrapy startproject 项目名称 可以新建项目
(base) C:\Users\Python>scrapy startproject Tengxun
命令执行后,会创建一个Tencent文件夹,结构如下
Tengxun/
├── scrapy.cfg #项目基本配置文件,不用修改
└── Tengxun
├── __init__.py #项目初始化函数,可以用来配置项目环境,导入模块
├── items.py # 定义爬取数据的结构
├── middlewares.py # 下载器中间件和蜘蛛中间件实现
├── pipelines.py # 处理数据
├── settings.py # 项目全局配置
└── spiders # 存放自己爬虫程序
├── __init__.py
2.根据项目要求编写items.py文件,根据需要爬取的内容定义爬取字段
import scrapy
class TengxunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
zhName = scrapy.Field()
# 职位链接
zhLink = scrapy.Field()
# 职位类别
zhType = scrapy.Field()
# 招聘人数
zhNum = scrapy.Field()
# 工作地点
zhAddress = scrapy.Field()
# 工作时间
zhTime = scrapy.Field()
'''scrapy.Field()是用来创建需要爬取字段,可以接受的值没有任何限制,设置Field对象
的主要目就是在一个地方定义好所有的元数据'''
3.进入Tencent目录,使用命令创建一个基础爬虫类并编写:
(base) (base) C:\Users\Python\Tengxun\Tengxun>scrapy genspider tengxun hr.tencent.com
请注意在 Linux 环境中 域名需要增加引号
执行命令后会在spiders文件夹中创建一个tengxun.py的文件,现在开始对其编写:
# -*- coding: utf-8 -*-
import scrapy
from Tengxun.items import TengxunItem
class TengxunSpider(scrapy.Spider):
"""
功能:爬取腾讯招聘具体信息
"""
# 爬虫名
name = 'tengxun'
allowed_domains = ['hr.tencent.com']
# 定义1个基准的url,方便后期拼接290个URL
url = "https://hr.tencent.com/position.php?start="
#start初始值,用于拼接url
start = 0
# 拼接初始的url
start_urls = [url + str(start)]
# parse函数是第1次从start_urls中初始URL发请求后
# 得到响应后必须要调用的函数
def parse(self, response):
for i in range(0,2891,10):
# scrapy.Request()
# 把290页的URL给调度器入队列,然后出队列给下载器
yield scrapy.Request\
(self.url + str(i),
callback=self.parseHtml)
#callback设置回调函数
def parseHtml(self,response):
# 每个职位的节点对象列表,通过响应对象xpth方法匹配获取
baseList = response.xpath('//tr[@class="odd"] | //tr[@class="even"]')
for base in baseList:
# 初始化模型对象
item = TengxunItem()
# 匹配页面中的具体招聘职位
item["zhName"] = base.xpath('./td[1]/a/text()').extract()[0]
# 匹配具体链接
item["zhLink"] = base.xpath('./td[1]/a/@href').extract()[0]
# 匹配具体职位类别,经过测试,这个字段可能在网页中没有值,由此增加判断,增加缺省值
item["zhType"] = base.xpath('./td[2]/text()').extract()
if item["zhType"]:
item["zhType"] = item["zhType"][0]
else:
item["zhType"] = "无"
# 匹配具体招聘人数
item["zhNum"] = base.xpath('./td[3]/text()').extract()[0]
# 匹配具体工作地点
item["zhAddress"]= base.xpath('./td[4]/text()').extract()[0]
# 匹配具体发布时间
item["zhTime"] = base.xpath('./td[5]/text()').extract()[0]
# 每次循环生成一个对象
yield item
4.编写pipelines.py项目管道文件
pipelines.py是项目管道文件,主要用于数据的处理,例如:将数据存入MySQL数据库,或者存入csv文件等,具体保存数据的方式可自定。为了简化代码,本文仅打印一下在终端输出方便理解。
class TengxunPrintPipeline(object):
'''管道文件名称,可以自己定义,定义完需要在settings.py中添加设置'''
def process_item(self, item, spider):
'''处理数据的函数,名称不能改变'''
print("=================")
print('职位名称:' + item["zhName"])
print('职位链接:' + item["zhLink"])
print('职位类型:' + item["zhType"])
print('招聘人数:' + item["zhNum"])
print('工作地点:' + item["zhAddress"])
print('发布时间:' + item["zhTime"])
print("=================")
# 返回对象,可以继续写下一个pipeline类处理数据
return item
5.settings.py文件设置
Windows环境下创建的项目没有添加User-Agent、指定如何处理数据等,具体设置可能需要根据项目来定,本文仅演示一些必须设置的地方
# 设置请求头部,添加url
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#不遵循robots协议
ROBOTSTXT_OBEY = False
# 设置管道文件 指定处理数据
ITEM_PIPELINES = {
'Tengxun.pipelines.TengxunPrintPipeline': 300,
#指定管道文件处理数据,可以指定多个,按照优先级依次运行,300代表优先级,数字越大,优先级越低
}
6.在spiders文件夹中执行命令
C:\Users\Python\Tengxun\Tengxun\spiders>srcapy crawl tengxun
执行结果
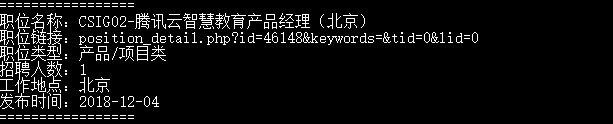
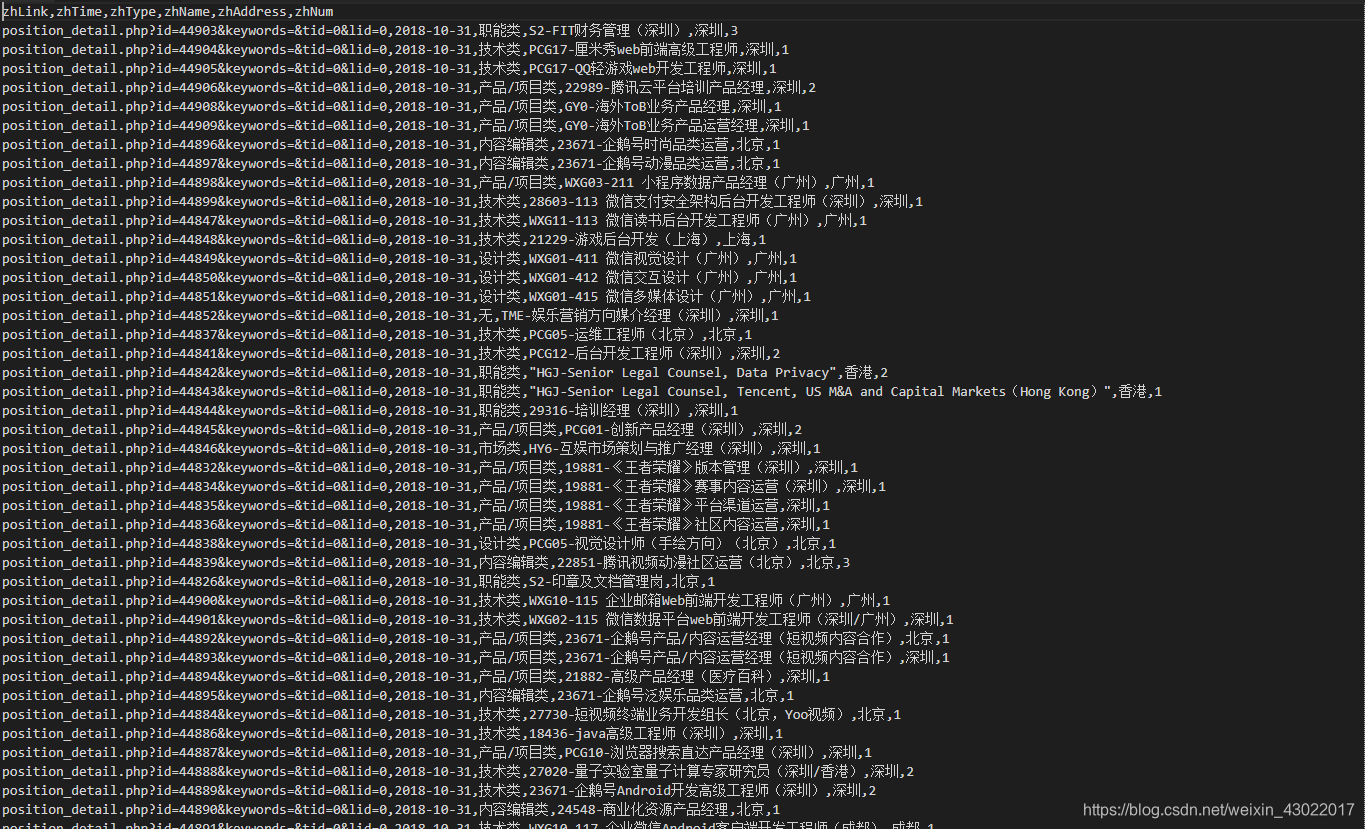
部分数据
本文仅仅用于演示交流,源码地址 github.
源码加入了两个管道文件可以用mysql与mangodb数据库存储数据,有兴趣的朋友可以自己去下载看看