因子分解机
因子分解机(Factorization Machine,简称FM),又称分解机器。是由Konstanz大学(德国康斯坦茨大学)Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决大规模稀疏数据下的特征组合问题。在系统介绍FM之前,我们先了解一下在实际应用场景中,稀疏数据是怎样产生的?
用户在网站上的行为数据会被Server端以日志的形式记录下来,这些数据通常会存放在多台存储机器的硬盘上。
以新~浪为例,各产品线纪录的用户行为日志会通过flume等日志收集工具交给数据中心托管,它们负责把数据定时上传至HDFS上,或者由数据中心生成Hive表。
我们会发现日志中大多数出现的特征是categorical类型的,这种特征类型的取值仅仅是一个标识,本身并没有实际意义,更不能用其取值比较大小。比如日志中记录了用户访问的频道(channel)信息,如”news”, “auto”, “finance”等。
假设channel特征有10个取值,分别为{“auto”,“finance”,“ent”,“news”,“sports”,“mil”,“weather”,“house”,“edu”,“games”}。部分训练数据如下:
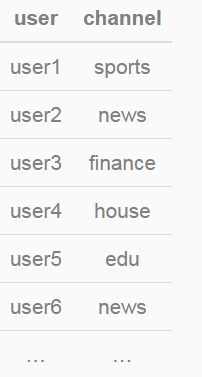
特征ETL过程中,需要对categorical型特征进行one-hot编码(独热编码),即将categorical型特征转化为数值型特征。channel特征转化后的结果如下:

可以发现,由one-hot编码带来的数据稀疏性会导致特征空间变大。上面的例子中,一维categorical特征在经过one-hot编码后变成了10维数值型特征。真实应用场景中,未编码前特征总维度可能仅有数十维或者到数百维的categorical型特征,经过one-hot编码后,达到数千万、数亿甚至更高维度的数值特征在业内都是常有的。
我组广告和推荐业务的点击预估系统,编码前是特征不到100维,编码后(包括feature hashing)的维度达百万维量级。
此外也能发现,特征空间增长的维度取决于categorical型特征的取值个数。在数据稀疏性的现实情况下,我们如何去利用这些特征来提升learning performance?
或许在学习过程中考虑特征之间的关联信息。针对特征关联,我们需要讨论两个问题:1. 为什么要考虑特征之间的关联信息?2. 如何表达特征之间的关联?
为什么要考虑特征之间的关联信息?
大量的研究和实际数据分析结果表明:某些特征之间的关联信息(相关度)对事件结果的的发生会产生很大的影响。从实际业务线的广告点击数据分析来看,也正式了这样的结论。
如何表达特征之间的关联?
表示特征之间的关联,最直接的方法的是构造组合特征。样本中特征之间的关联信息在one-hot编码和浅层学习模型(如LR、SVM)是做不到的。目前工业界主要有两种手段得到组合特征:
人工特征工程(数据分析+人工构造);
通过模型做组合特征的学习(深度学习方法、FM/FFM方法)
FM模型表达
为了更好的介绍FM模型,我们先从多项式回归、交叉组合特征说起,然后自然地过度到FM模型。
二阶多项式回归模型
我们先看二阶多项式模型的表达式:
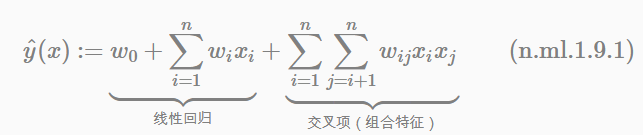
因为我们知道,回归模型的参数w的学习结果就是从训练样本中计算充分统计量(凡是符合指数族分布的模型都具有此性质),而在这里交叉项的每一个参数wij的学习过程需要大量的xi、xj同时非零的训练样本数据。由于样本数据本来就很稀疏,能够满足“xi和xj都非零”的样本数就会更少。训练样本不充分,学到的参数wij就不是充分统计量结果,导致参数wij不准确,而这会严重影响模型预测的效果(performance)和稳定性。How to do it ?
那么,如何在降低数据稀疏问题给模型性能带来的重大影响的同时,有效地解决二阶交叉项参数的学习问题呢?矩阵分解方法已经给出了解决思路。这里借用CMU讨论课中提到的FM课件和美团-深入FFM原理与实践中提到的矩阵分解例子。
在基于Model-Based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示。如下图所示。


这里我们只讨论二阶FM模型(degree=2),其表达式为:

公式解读:
线性模型+交叉项
直观地看FM模型表达式,前两项是线性回归模型的表达式,最后一项是二阶特征交叉项(又称组合特征项),表示模型将两个互异的特征分量之间的关联信息考虑进来。用交叉项表示组合特征,从而建立特征与结果之间的非线性关系。
交叉项系数 → 隐向量内积

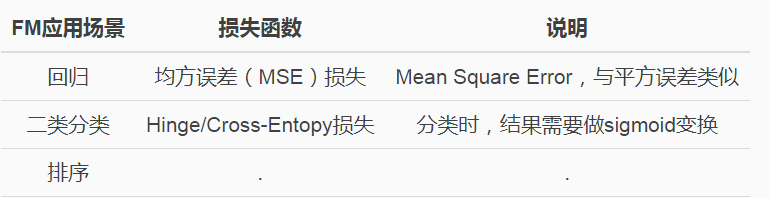
论文中还提到FM模型的应用场景,并且说公式(ml.1.9.1)作为一个通用的拟合模型(Generic Model),可以采用不同的损失函数来解决具体问题。比如:
FM参数学习
等式变换
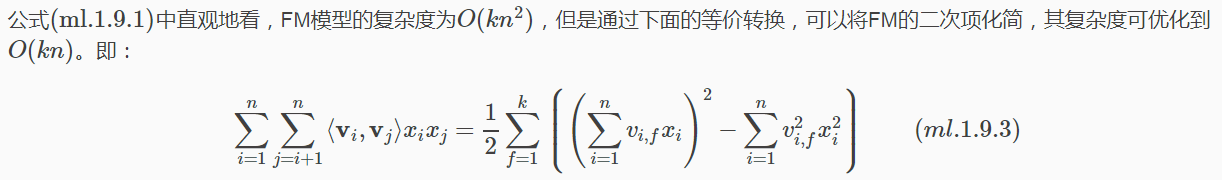
下面给出详细推导:

解读第(1)步到第(2)步,这里用A表示系数矩阵V的上三角元素,B表示对角线上的交叉项系数。由于系数矩阵V是一个对称阵,所以下三角与上三角相等,有下式成立:
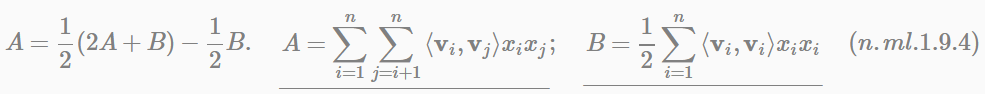
如果用随机梯度下降(Stochastic Gradient Descent)法学习模型参数。那么,模型各个参数的梯度如下:

FM训练复杂度

综上可知,FM算法可以在线性时间内完成模型训练,以及对新样本做出预测,所以说FM是一个非常高效的模型。
FM总结
上面我们主要是从FM模型引入(多项式开始)、模型表达和参数学习的角度介绍的FM模型,这里我把我认为FM最核心的精髓和价值总结出来,与大家讨论。FM模型的核心作用可以概括为以下3个:
-
FM降低了交叉项参数学习不充分的影响
one-hot编码后的样本数据非常稀疏,组合特征更是如此。为了解决交叉项参数学习不充分、导致模型有偏或不稳定的问题。作者借鉴矩阵分解的思路:每一维特征用k维的隐向量表示,交叉项的参数wij用对应特征隐向量的内积表示,即⟨vi,vj⟩(也可以理解为平滑技术)。这样参数学习由之前学习交叉项参数wij的过程,转变为学习n个单特征对应k维隐向量的过程。
很明显,单特征参数(k维隐向量vi)的学习要比交叉项参数wij学习得更充分。示例说明:

<女性,汽车>的含义是女性看汽车广告。可以看到,单特征对应的样本数远大于组合特征对应的样本数。训练时,单特征参数相比交叉项特征参数会学习地更充分。
因此,可以说FM降低了因数据稀疏,导致交叉项参数学习不充分的影响。 -
FM提升了模型预估能力
依然看上面的示例,样本中没有<男性,化妆品>交叉特征,即没有男性看化妆品广告的数据。如果用多项式模型来建模,对应的交叉项参数w男性,化妆品是学不出来的,因为数据中没有对应的共现交叉特征。那么多项式模型就不能对出现的男性看化妆品广告场景给出准确地预估。
FM模型是否能得到交叉项参数w男性,化妆品呢?答案是肯定的。由于FM模型是把交叉项参数用对应的特征隐向量内积表示,这里表示为w男性,化妆品=⟨v男性,v化妆品⟩。
用男性特征隐向量v男性和化妆品特征隐向量v化妆品的内积表示交叉项参数w男性,化妆品。
由于FM学习的参数就是单特征的隐向量,那么男性看化妆品广告的预估结果可以用⟨v男性,v化妆品⟩得到。这样,即便训练集中没有出现男性看化妆品广告的样本,FM模型仍然可以用来预估,提升了预估能力。 -
FM提升了参数学习效率
这个显而易见,参数个数由(n2+n+1)变为(nk+n+1)个,模型训练复杂度也由O(mn2)变为O(mnk)。m为训练样本数。对于训练样本和特征数而言,都是线性复杂度。
此外,就FM模型本身而言,它是在多项式模型基础上对参数的计算做了调整,因此也有人把FM模型称为多项式的广义线性模型,也是恰如其分的。
从交互项的角度看,FM仅仅是一个可以表示特征之间交互关系的函数表法式,可以推广到更高阶形式,即将多个互异特征分量之间的关联信息考虑进来。例如在广告业务场景中,如果考虑User-Ad-Context三个维度特征之间的关系,在FM模型中对应的degree为3。
最后一句话总结,FM最大特点和优势:
FM模型对稀疏数据有更好的学习能力,通过交互项可以学习特征之间的关联关系,并且保证了学习效率和预估能力。
场感知分解机
场感知分解机器(Field-aware Factorization Machine ,简称FFM)最初的概念来自于Yu-Chin Juan与其比赛队员,它们借鉴了辣子Michael Jahrer的论文中field概念,提出了FM的升级版模型。
通过引入field的概念,FFM吧相同性质的特征归于同一个field。在FM开头one-hot编码中提到用于访问的channel,编码生成了10个数值型特征,这10个特征都是用于说明用户PV时对应的channel类别,因此可以将其放在同一个field中。那么,我们可以把同一个categorical特征经过one-hot编码生成的数值型特征都可以放在同一个field中。
同一个categorical特征可以包括用户属性信息(年龄、性别、职业、收入、地域等),用户行为信息(兴趣、偏好、时间等),上下文信息(位置、内容等)以及其它信息(天气、交通等)。

这里以NTU_FFM.pdf和美团-深入FFM原理与实践都提到的例子,给出FFM-Fields特征组合的工作过程。
给出一下输入数据:
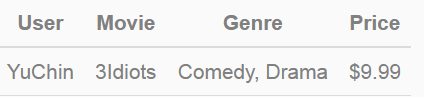
Price是数值型特征,实际应用中通常会把价格划分为若干个区间(即连续特征离散化),然后再one-hot编码,这里假设$9.99对应的离散化区间tag为”2”。当然不是所有的连续型特征都要做离散化,比如某广告位、某类广告/商品、抑或某类人群统计的历史CTR(pseudo-CTR)通常无需做离散化。
该条记录可以编码为5个数值特征,即User^YuChin, Movie^3Idiots, Genre^Comedy, Genre^Drama, Price2。其中GenreComedy, Genre^Drama属于同一个field。为了说明FFM的样本格式,我们把所有的特征和对应的field映射成整数编号。

其中,红色表示Field编码,蓝色表示Feature编码,绿色表示样本的组合特征取值(离散化后的结果)。二阶交叉项的系数是通过与Field相关的隐向量的内积得到的。如果单特征有n个,全部做二阶特征组合的话,会有
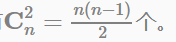
FFM应用场景
在我们的广告业务系统、商业推荐以及自媒体-推荐系统中,FFM模型作为点击预估系统中的核心算法之一,用于预估广告、商品、文章的点击率(CTR)和转化率(CVR)。
在鄙司广告算法团队,点击预估系统已成为基础设施,支持并服务于不同的业务线和应用场景。预估模型都是离线训练,然后定时更新到线上实时计算,因此预估问题最大的差异就体现在数据场景和特征工程。以广告的点击率为例,特征主要分为如下几类:
- 用户属性与行为特征:
- 广告特征:
- 上下文环境特征:
为了使用开源的FFM模型,所以的特征必须转化为field_id:feat_id:value格式,其中field_id表示特征所属field的编号,feat_id表示特征编号,value为特征取值。数值型的特征如果无需离散化,只需分配单独的field编号即可,如历史pseudo-ctr。categorical特征需要经过one-hot编码转化为数值型,编码产生的所有特征同属于一个field,特征value只能是0/1, 如用户年龄区间、性别、兴趣、人群等。
开源工具FFM使用时,注意事项(参考新浪广告算法组的实战经验和美团-深入FFM原理与实践):
样本归一化:
特征归一化:
省略0值特征:
回归、分类、排序等。推荐算法,预估模型(如CTR预估等)
更多案例请关注“思享会Club”公众号或者关注思享会博客:http://gkhelp.cn/
