【清华AI自强计划】-第三讲课程笔记-1
数据归一化中的“一”是什么意思?
将不同变量的量纲都转化为1,消除单位的影响。
明确课程定位:
垂直行业从业者&爱好者:
听课目标:0->0.5 定性理解,专注落地
算法科学家:
听课目标:0->1 初步入门,加强算法
提升方法:共享论文
AI工程师:
需要的代码工程能力更强,和真实业务环境相结合,如大量数据需要并行计算,有项目需要上线
听课目标:0->1 初步入门,加强代码 能力
提升方法:工程问题,做作业的时候将每个函数都弄清楚,再做些上下游的工作,如数据是怎么爬取的,将项目上线等。
第三讲目标:训练“识别手写数字”的算法
数据集介绍:
MNIST:
M 指是modified,数据集中原来高中生和公务员的手写数字分别作为测试集和训练集,modified版本将其混合,即将测试集和训练集混合。
如何用逻辑回归解决这一问题?(用二分类解决十分类的问题,One vs All)
训练10个分类器,每个分类器只打1个类别,想解决10分类的问题,训练10个分类器即可。(A defense of one-vs-all classification)
计算机看图是一个数字矩阵:

60000个图片样本,每个样本对应2828的维度,形成上图右边的输入矩阵。
训练结果:样本数量设置为55000时,最后输出预测精度刚超过50%:泛化能力不行。
而当训练样本数为500时,预测精度反而达到90%。
为什么样本数量少,精度反而更高呢?
拟合出来的模型相当于在2828维度的空间中画出决策边界,样本数非常少,以至于随便画条线都可以很好把样本分隔开。
NN神经网络的历史渊源:
生物学神经元衍生出数学模型:
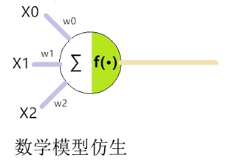
小于一个阈值不激活,大于一个阈值将数据往后传。
神经元多了–>感知机——>(有监督)BP神经网络
无监督:布尔计算机
了解模型是什么样子的,参数在哪儿,怎么输入的,
触及到核心知识时是没有任何捷径的,要仔细弄懂每个符号,每个运算过程。
只有输出没有输入的圆圈代表偏置,作用是让拟合曲线离开原点。
输入层:神经元个数为特征个数
输出层:二分类输出层只有一个,多分类情况下分类类别等于输出层神经元个数。
隐藏层:神经元个数任意指定。
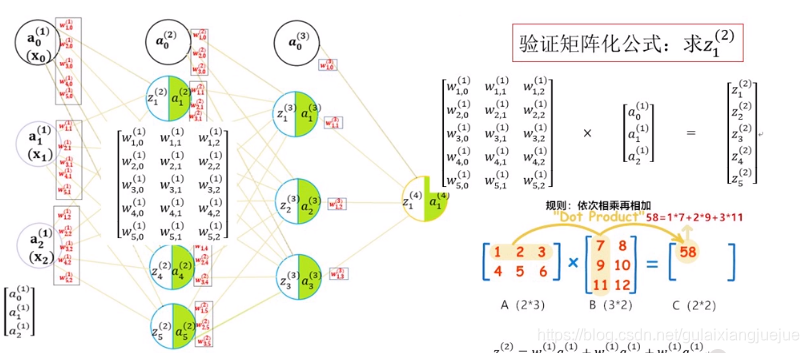
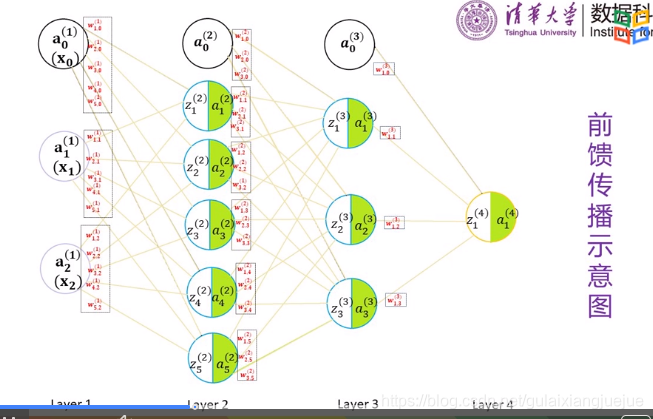
前馈传播示意图解析:
上图中字母上角标括号内的数字代表层数
a,z,x下角标为在此层中的序号
w为模型参数,下角标有两位,前面一位为指向神经元的序号, 后面一位是自己的序号。
全连接:前层每一个神经元和下一层所有神经元都要相连


变量及参数解析:

信号传导下一层神经元先加和到z,再经过激活函数输出a。
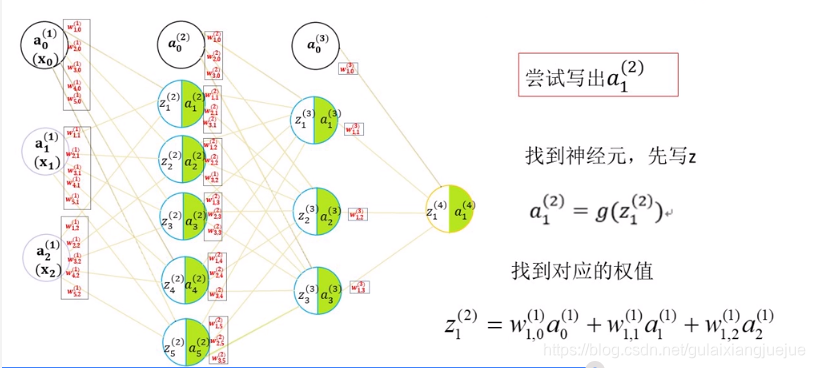
矩阵化表示,更加简洁:
第二层的z等于第一层的权值乘以数值。