(002)最近要研发一款数据传输服务的产品需要用到Hadoop集群,之前搭建过后来长时间不用就给忘记了,这次搭好来记录一下搭建方法与经验总结
Hadoop集群的搭建
原料:
- VM虚拟机
- JDK1.8
- hadoop2.7.3
注:将jdk1.8.tar.gz和hadoop-2.7.3.tar.gz放在/opt/bigdata目录下(没有请自行创建)
附件:
链接:https://pan.baidu.com/s/1oII8j97sAEQDokE9kYJTzA
提取码:eau1
设计集群
以一主两从为例搭建集群环境,在VM虚拟机中创建三个
具体设计如下:
192.168.225.100 -- master(主机),namenode, datanode,
jobtracker, tasktracker -- master(主机名)
192.168.225.101 -- slave1(从机),datanode, tasktracker -- slave1(主机名)
192.168.225.102 -- slave2(从机),datanode,tasktracker -- slave2(主机名)
创建用户
命令:
# useradd hadoop
# id hadoop
# passwd hadoop
注:我这里设置的密码是123456,需要打两遍
使hadoop用户成为sudoers,以root用户修改文件/etc/sudoers,
命令:
# vim /etc/sudoers
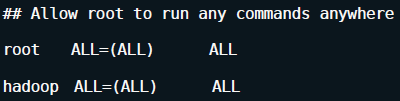
修改文件夹权限
我未来准备将hadoop安装到/opt/bigdata文件夹下,所以希望修改该文件夹权限,使hadoop用户能够自由操作该文件夹下的所有文件
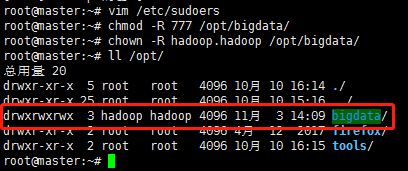
安装JDK
解压文件

移动文件夹

删除文件夹

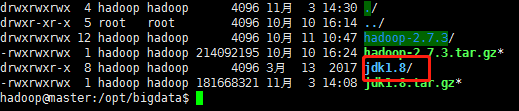
注:移动文件夹和删除文件夹这两步可以不做,应该是我拿到这个jdk安装包中间多打了两层目录,如果其他包没有这个问题就不用做这两步,最后做到如下图目录效果就可以了
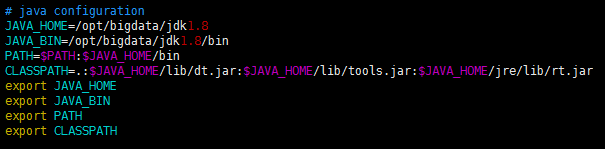
配置JDK环境变量(以root身份配置)
使profile文件生效

使用java命令查看jdk版本以验证是否安装成功

搭建Hadoop集群
解压文件

查看目录列表
在hadoop目录下建立tmp目录,并将权限设定为777
命令:
$ mkdir tmp
$ chmod 777 tmp
$ mkdir dfs
$ mkdir dfs/name
$ mkdir dfs/data
修改hadoop配置文件
待修改清单:
-
core-site.xml
-
hdfs-site.xml
-
mapred-stie.xml
-
yarn-site.xml
-
masters
-
slaves
进入hadoop配置文件目录
修改 hadoop-env.sh


修改 mapred-env.sh

修改 yarn-env.sh

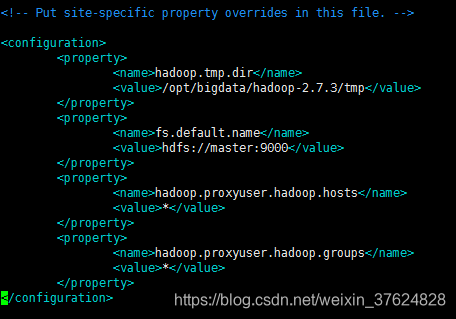
修改 core-site.xml
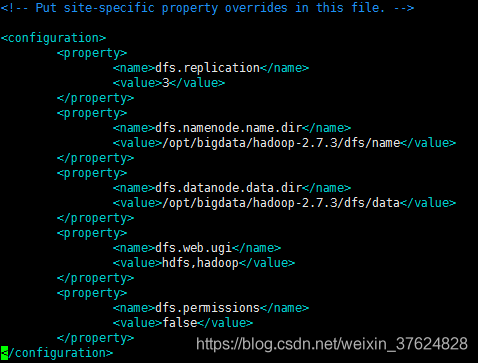
修改 hdfs-site.xml
修改 mapred-site.xml
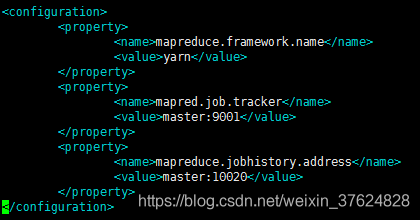
修改 yarn-site.xml
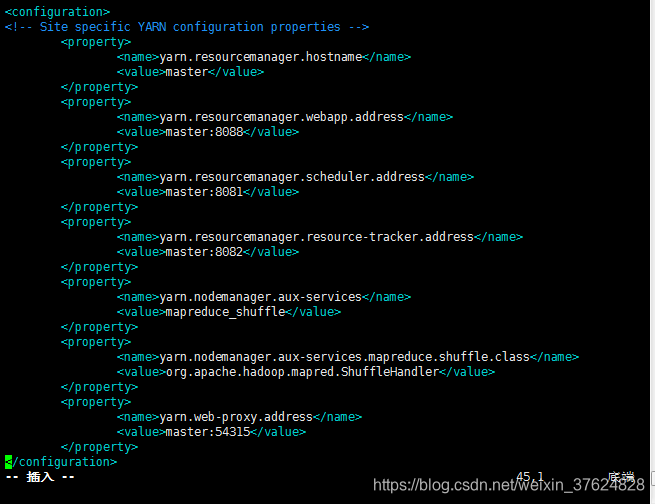
修改 slaves (master、slave1和slave2均作为datanode)

配置系统变量
命令:
$ sudo su - root
123456
#vim /etc/profile

使配置生效(切换回hadoop用户)
命令:
$ source /etc/profile
将hadoop、jdk、以及配置文件发送到slave1、slave2节点
命令:(以slave1为例,slave2同理)
$ scp -r /opt/bigdata/hadoop-2.7.3 hadoop@slave1:/opt/bigdata/
$ scp -r /opt/bigdata/jdk1.8 hadoop@slave1:/opt/bigdata/
注:slave1和slave2的/etc/profile文件按照master/etc/profile重新配置一遍(我是利用xftp从master下载并分别上传至slave1和slave2中的)
修改hosts文件(使用root用户)
为了使外部应用可以访问到服务(slave1和salve2同理)
命令:
#vim /etc/hosts
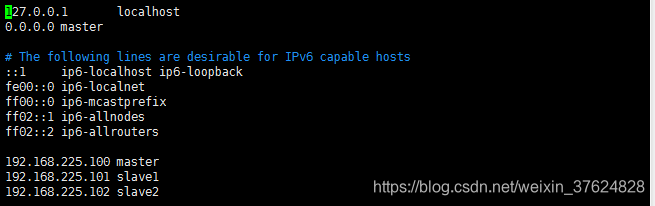
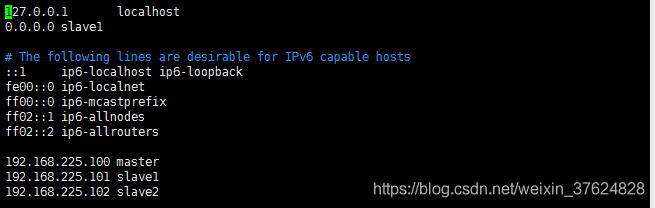
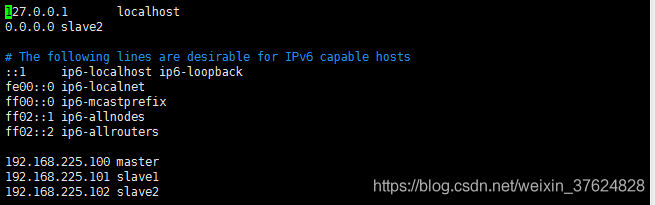
授权(hadoop用户,目录定位到home目录即:~(这个符号代表的home 目录,不是表情……)
master给自己和salve1,slave2发证书
命令:(初次授权一路回车)
$ ssh-keygen
$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@master
$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@slave1
$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@slave2slave1给master发证书(基础状态和master一致)
$ ssh-keygen
$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@masterslave2给master发证书(基础状态和master一致)
$ ssh-keygen
$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@master
测试
使用ssh从master登录到slave1,然后再从slave1登录到master,接着从master登录到slave2,最后从salve2登录到master
命令:(从master主机开始)
$ ssh slave1
$ ssh master
$ ssh slave2
$ ssh master
启动集群
启动集群有两种方法,一种是全部启动,一种是分步启动
方法一(全部启动):
定位到/opt/bigdata/hadoop-2.7.3/sbin/目录下,输入./start-all.sh命令
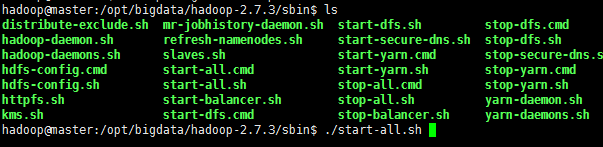
方法二(分布启动)
启动HDFS
命令:
$ ./start-hdfs.sh
启动YARN
$ ./start-yarn.sh
验证
web界面
在浏览器中输入 http://192.168.225.100:50070
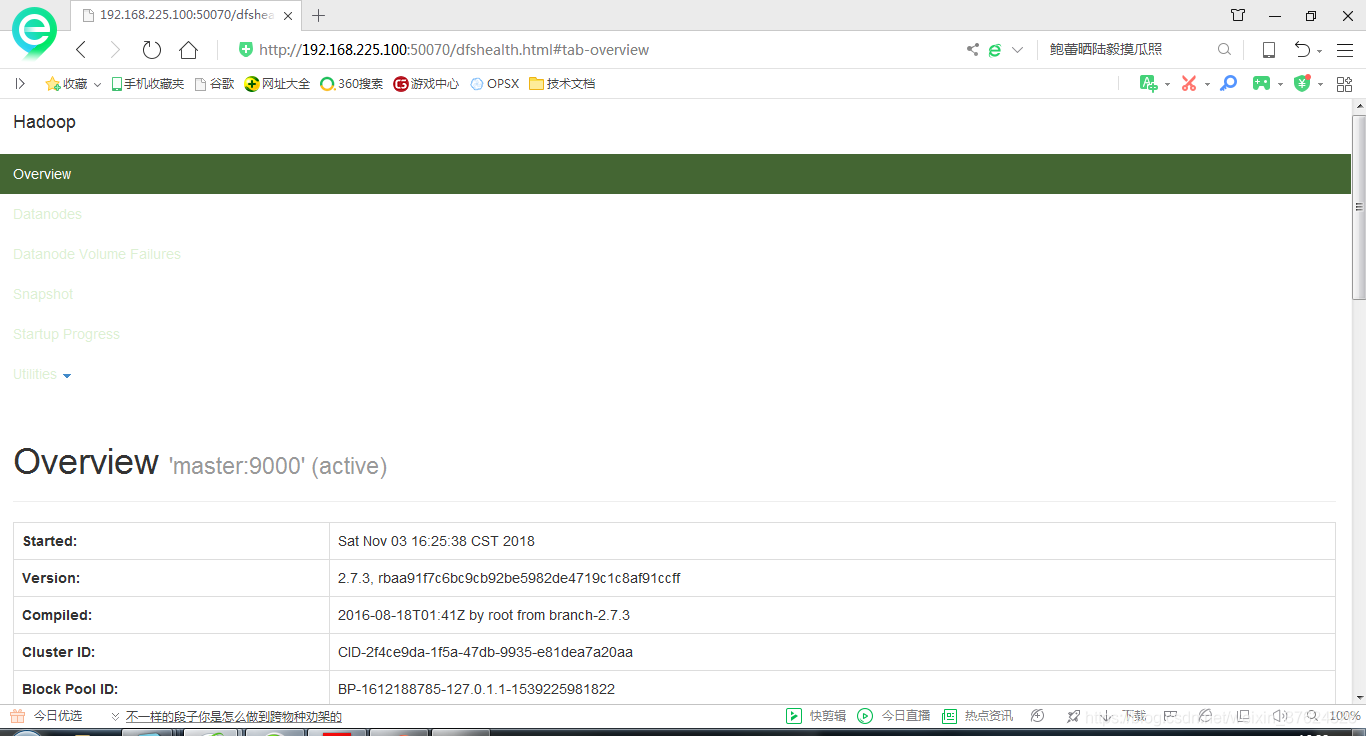
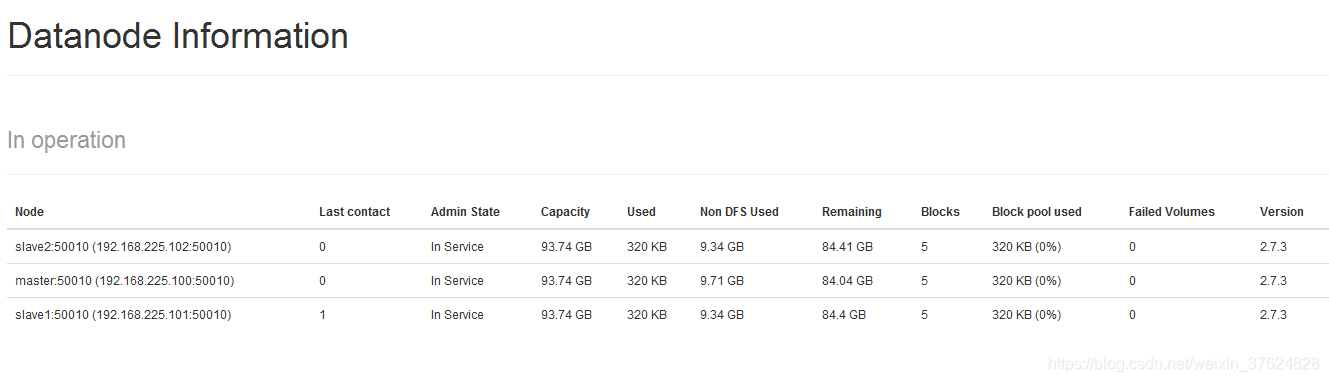
点击Datanodes页面
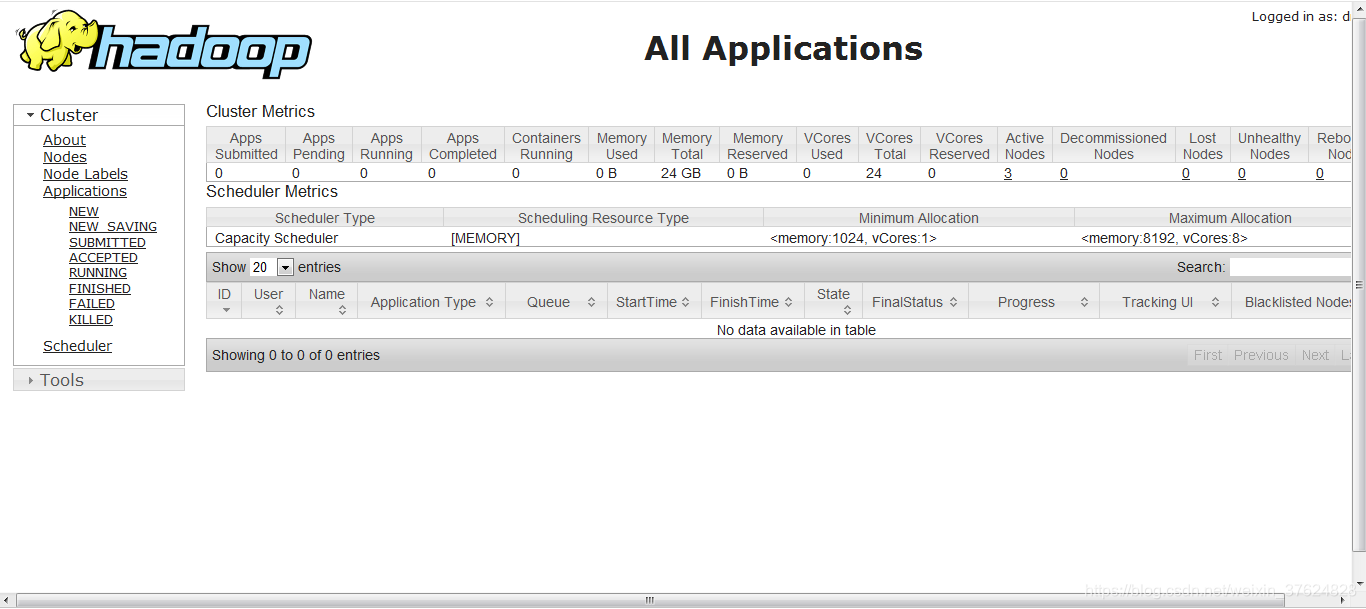
在浏览器中输入http://192.168.225.100:8088
测试程序
在集群上运行一个小程序来测试一下我们的集群有没有问题
以wordcount程序为例
使用hadoop命令创建一个测试目录
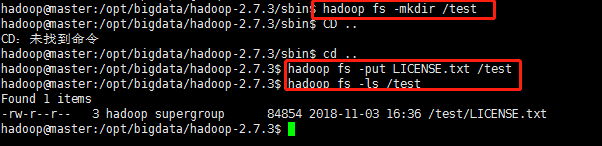
执行如下命令:

查看结果:
$ hadoop fs -cat /test/part-r-00000

注:部分结果。
坑
1. 修改由于拷贝造成的datanodeid重复
命令:(slave1和slave2同理)
$ vim /opt/bigdata/hadoop-2.7.3/dfs/data/current/VERSION
master:

slave1:

slave2:

注:我这里改动了datanodeUuid的后两位
2. 执行作业报如下异常
18/11/03 16:50:10 INFO input.FileInputFormat: Total input paths to process : 1
18/11/03 16:50:10 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1249)
at java.lang.Thread.join(Thread.java:1323)
at org.apache.hadoop.hdfs.DFSOutputStream
DataStreamer.endBlock(DFSOutputStream.java:370)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546)
这个异常据网上说是hadoop的一个bug可以忽略……,不影响集群的正常工作,如果谁知道是什么原因的话可以告诉我,谢谢啦!
总结
一个完美的集群是很需要花时间和心思研究它的每一个细节的……