1、维度建模定义?
维度模型是专为统计分析优化的数据模型,维度模型的设计由业务流程驱动,每一个业务流程对应一张事实表以及若干维度表。
2、一个数值数据元素是事实属性还是维度属性?(属于事实表还是维度表)
在对每项业务做统计分析时,我们所关心的指标记录在事实表中,如交易金额、利润、销售量等;过滤与分组的条件则记录在维度表中,如交易时间,地区,商品种类等。
在设计事实表中,一个原则就是我们要尽量存储可加的指标。
3、为何更多使用描述性文字?
在业务数据库中,我们常常用标志位,布尔值或是操作代码做为字段的内容。在维度表,我们更推荐使用描述性的文字。比如,在客户表中有一个 membership 字段来表示该客户是否为会员。在业务表中,该字段会用布尔型的 0/1 表示。但是在维度表中,该字段应该为文本型。可以用 Yes/No 做为属性值,但更好的选择是用 Member/Non-member 做为属性值。当你做分组或是透视表时就可以看出差别,由后者产生的报表描述更清晰。
4、增加时间元素的重要性?
为加入到数据仓库的数据增加时间元素,标注该数据的时间版本。随着时间增长,企业经营的规模增加,原有数据类型不能符合现有业务的需求,需要进行修改,此时在数据仓库中基于原有字段增加一个新的数据字段,通过时间版本可以快速区分老版本和新版本。
5、数据仓库严格遵循规范化设计带来的问题?
数据仓库如果严格遵循操作型数据库的范式设计,一方面:
数据访问I/O次数多,严重影响数据访问的效率;
索引建立复杂而且索引数据量庞大。
6、数据仓库常见的反规范化设计?
(1)将经常同时访问的两个不同表的数据可以进行合并;
(2)对于某些经常访问的(不变的)基础数据表可以冗余存放到不同表中,取消基础数据表。
(3)对于同一张表中某一个字段访问特别多,可以将该字段抽离出该表。
7、数据仓库三种事实表:
事务事实表: 事务事实表记录的事务层面的事实,保存的是最原子的数据,也称“原子事实表”。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新;
周期快照事实表: 周期快照事实表的粒度是每个时间段一条记录, 周期快照事实表的日期维度通常是记录时间段的终止日,记录的事实是这个时间段内一些聚集事实值;
累积快照事实表:通常具有多个日期字段,用来记录整个生命周期中的关键时间点。
8、通俗理解数据仓库的粒度确定
数据粒度可以理解为:在同一维度下,数据的粗细程度。
最小粒度是指:根据业务需求,确定当前数据的不可分割的程度。
比如:我们要分析用户的购物和时间维度的关系。从时间维度来说,用户下单时间最细粒度精确到分钟,那么我们可以统计出一分钟有多少用户下单,由此可知系统一分钟的最大并发数量。由于最低粒度是分钟,我们可以在此基础上进行维度上钻,可以统计出一小时,一天,一个月等不同时间维度上用户的购物数量。
维度建模实例:
比如一次购买行为我们就可以理解为是一个事实,下面我们上示例
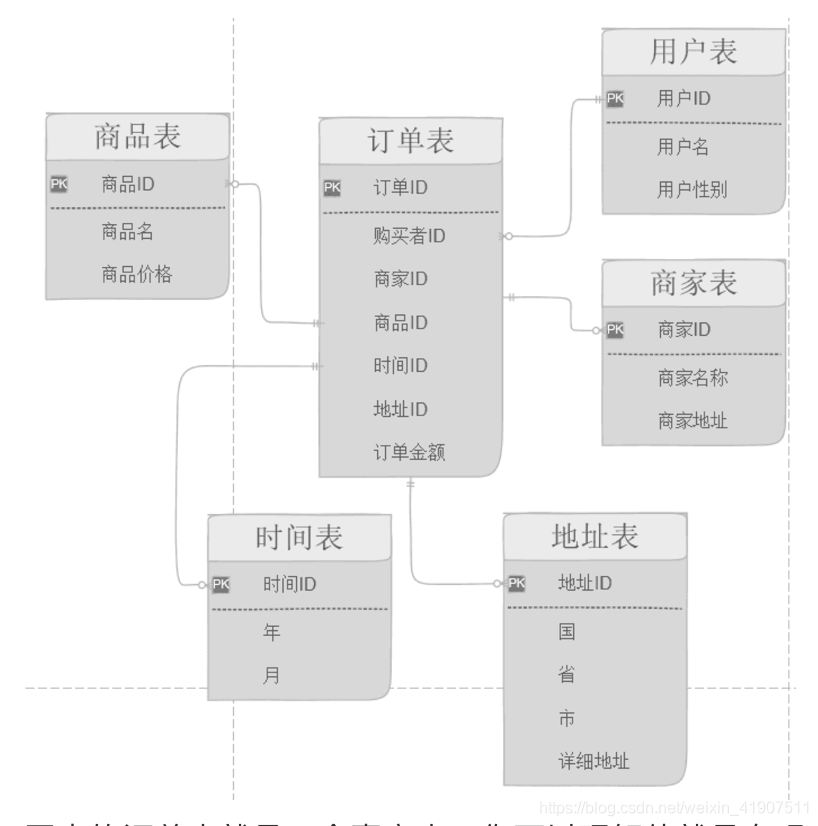
图中的订单表就是一个事实表,你可以理解他就是在现实中发生的一次操作型事件,我们每完成一个订单,就会在订单中增加一条记录。
我们可以看一下事实表的特征,在事实表里没有存放实际的内容,他是一堆主键的集合,这些ID分别能对应到维度表中的一条记录。
维度模型的优缺点:
数据冗余小(因为很多具体的信息都存在相应的维度表中了,比如用户信息就只有一份)
结构清晰(表结构一目了然)
便于做OLAP分析
增加使用成本,比如查询时要关联多张表
数据不一致,比如用户发起购买行为的时候的数据,和我们维度表里面存放的数据不一致