1.数据仓库(Data Warehouse)
在日益激烈的商业竞争中,企业迫切需要更加准确的战略决策信息。在以往的关系型数据库系统中,企业拥有海量的数据,这些数据对于企业的运作是非常有用的,但是对于商业战略决策和目标制定的作用甚微,不是战略决策要使用的信息。
关系型数据库很难将这些数据转换成企业真正需要的决策信息,原因如下:
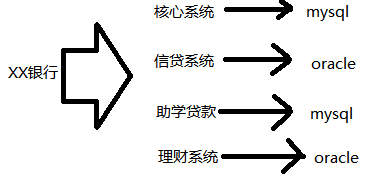
- 1.一个企业中可能有很多管理系统平台,企业数据分散在多种互不兼容的系统中。例如:一个银行中的系统分为:核心系统,信贷系统,企业贷款系统,客户关系系统,助学贷款系统,理财系统、反洗钱系统等,这些系统数据有可能存储在不同类型的关系型数据库中。
各个系统的数据库不同有的存在mysql,有的存在oracle,各个系统之间不统一,没有联系,因为传统的数据库不能满足数据分析
- 2.关系型数据库中存储的数据一般是最基本的、日常事务处理的、面向业务操作的数据,数据一般可以更新状态,删除数据条目等。不能直接反应趋势的变化。例如:用户登录网站购买商品,在关系型数据库中最终存储的数据是某个用户下了一个订单,订单状态为付款待发货。一般用户在网站浏览了什么商品,搜索了什么样的关键字,这些数据不会存储在关系型数据库中,往往这些数据更具价值。
- 3.对于战略决策来说,决策者必须从不同的商业角度观察数据,比如说产品、地区、客户群等不同方面观察数据,关系型数据库中数据不适合从不同的角度进行分析,只是面向基本的业务操作。(X度文库,X度音乐,X度贴吧的衰落让X乎有了机会)
所以我们需要对企业中各类数据进行汇集,清洗,管理,找出战略决策信息,这就需要建立数据仓库。

数据仓库,Data Warehouse,可简写为DW或DWH。数据仓库是面向主题的、集成的(非简单的数据堆积,比如财务系统的zs性别为”男”,但是生产系统的zs性别为”M”)、相对稳定的(一般数据只有增加和查询操作)、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程(OLAP)的支持。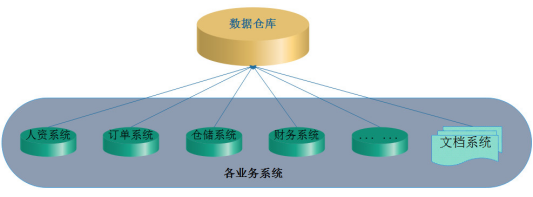
面向主题:主题是指使用数据仓库进行决策时所关心的重点方面,每个主题都对应一个相应的分析领域,一个主题通常与多个信息系统相关。
例如:在银行数据中心平台中,用户可以定义为一个主题,用户相关的数据可以来自信贷系统、银行资金业务系统、风险评估系统等,以用户为主题就是将以上各个系统的数据通过用户切入点,将各种信息关联起来。如下图所示:

数据集成:数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性(消除歧义),以保证数据仓库内的信息是关于整个企业的一致的全局信息,这个过程中会有ETL操作,以保证数据的一致性、完整性、有效性、精确性。
例如某公司中有人力资源系统、生产系统、财务系统、仓储系统等,现需要将各个系统的数据统一采集到数据仓库中进行分析。在人力系统中,张三的性别为“男”,可能在财务系统中张三的性别为“M”,在人力资源系统中张三的职称为“生产部员工”,在生产系统中张三的职称为“技术经理”,那么当我们将数据抽取到数据仓库中时,需要经过数据清洗将数据进行统一、精确、一致性存储。
相对稳定:数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,基本没有修改和删除操作,通常只需要定期的加载、刷新。
例如:某用户在一天中多次登录某系统,关系型数据库中只是记录当前用户最终在系统上的状态是“在线”还是“离线”,只需要记录一条数据进行状态更新即可。但是在数据仓库中,当用户多次登录系统时,会产生多条记录,不会存在更新状态操作,每次用户登录系统和下线系统都会在数据仓库中记录一条信息,这样方便后期分析用户行为。
反映历史变化:数据仓库中的数据通常包含历史信息,系统地记录企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
例如:电商网站中,用户从浏览各个商品,到将商品加入购物车,直到付款完成,最终的结果在关系型数据库中只需要记录用户的订单信息。往往用户在网站中的浏览商品的信息行为更具有价值,数据仓库中就可以全程记录某个用户登录系统之后浏览商品的浏览行为,加入购物车的行为,及付款行为。以上这些数据都会被记录在数据仓库中,这样就为企业分析用户行为数据提供了数据基础。
1.2数据仓库技术的发展历程
- 1.萌芽阶段(1978~1988年)。
数据仓库概念最早可追溯到20世纪70年代,MIT(麻省理工)的研究员致力于研究一种优化的技术架构,该架构试图将业务处理系统和分析系统分开,即将业务处理和分析处理分为不同层次,针对各自的特点采取不同的架构设计原则,MIT的研究员认为这两种信息处理的方式具有显著差别,以至于必须采取完全不同的架构和设计方法。但受限于当时的信息处理能力,这个研究仅仅停留在理论层面。 - 2.探索阶段。
20世纪80年代中后期,DEC公司(美国数字设备公司)结合MIT的研究结论,建立了TA2(Technical Architecture2)规范,该规范定义了分析系统的四个组成部分:数据获取、数据访问、目录和用户服务。其中的数据获取和数据访问目前大家都很清楚,而目录服务是用于帮助用户在网络中找到他们想要的信息,类似于业务元数据管理;用户服务用以支持对数据的直接交互,包含了其他服务的所有人机交互界面,这是系统架构的一次重大转变,第一次明确提出分析系统架构并将其运用于实践。 - 3.雏形阶段(1988年)
1988年,为解决全企业集成问题,IBM公司第一次提出了信息仓库(InformationWarehouse)的概念:“一个结构化的环境,能支持最终用户管理其全部的业务,并支持信息技术部门保证数据质量”,并称之为VITAL规范(VirtuallyIntegrated Technical Architecture Lifecycle)。并定义了85种信息仓库的组件,包括数据抽取、转换、有效性验证、加载、Cube开发和图形化查询工具等。至此,数据仓库的基本原理、技术架构以及分析系统的主要原则都已确定,数据仓库初具雏形。 - 4.确立阶段(1991年)
1991年,比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立。该书定义了数据仓库非常具体的原则,包括:
数据仓库是面向主题的(Subject-Oriented)、
1)集成的(Integrated)、
2)包含历史的(Time-variant)、
3)不可更新的(Nonvolatile)、
4)面向决策支持的(Decision Support)
5)面向全企业的(Enterprise Scope)
6)最明细的数据存储(Atomic Detail)
7)数据快照式的数据获取(Snap Shot Capture)
这些原则到现在仍然是指导数据仓库建设的最基本原则。凭借着这本书,Bill Inmon被称为“数据仓库之父”。

Bill Inmon主张自上而下的建设企业级数据仓库EDW (Enterprise Data Warehouse),认为数据仓库是一个整体的商业智能系统的一部分, 一家企业只有一个数据仓库,数据集市(数据集市中存储为特定用户需求而预先计算好的数据,从而满足用户对性能的需求)的信息来源出自数据仓库,在数据仓库中,信息存储符合第三范式,大致结构如下: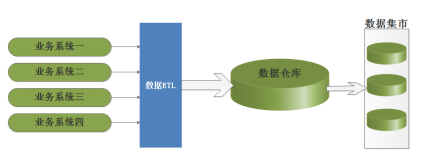
由于企业级数据仓库的设计、实施很困难,使得最早吃数据仓库螃蟹的公司遭到大面积的失败,除了常见的业务需求定义不清、项目执行不力之外,很重要的原因是因为其数据模型设计,在企业级数据仓库中,Inmon推荐采用3范式进行数据建模,但是不排除其他的方法,但是Inmon的追随者固守OLTP系统的3范式设计,从而无法支持决策支持(DSS -Decision Suport System )系统的性能和数据易访问性的要求。
1994年前后,实施数据仓库的公司大都以失败告终,这时,拉尔夫·金博尔(Ralph Kimball)出现了,他的第一本书《The DataWarehouse Toolkit》掀起了数据集市的狂潮,这本书提供了如何为分析进行数据模型优化详细指导意见。

Ralph Kimball主张自下而上的建立数据仓库,极力推崇建立数据集市,认为数据仓库是企业内所有数据集市的集合,信息总是被存储在多维模型当中,为传统的关系型数据模型和多维OLAP之间建立了很好的桥梁,其思路如下: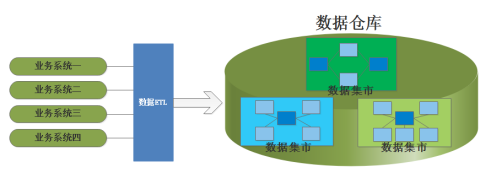
- 5.争吵与混乱(1996-1997年)
Bill Inmon(比尔·恩门)的《Building the Data Warehouse》主张建立数据仓库时采用自上而下 方式,以第3范式进行数据仓库模型设计,而Ralph Kimball(拉尔夫·金博尔)在《The DataWarehouse Toolkit》则是主张自下而上的方式,力推数据集市建设。企业级数据仓库还是部门级数据集市?关系型还是多维?Bill Inmon 和Ralph Kimball一开始就争论不休,其各自的追随者也唇舌相向,形成相对立的两派:Inmon派和Kimball派。
在初期,数据集市的快速实施和较高的成功率让Kimball派占了上风,由于数据集市仅仅是数据仓库的某一部分,实施难度大大降低,并且能够满足公司内部部分业务部门的迫切需求,在初期获得了较大成功。但是很快,他们也发现自己陷入了某种困境:随着数据集市的不断增多,这种架构的缺陷也逐步显现,公司内部独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致。解决问题的方法只能是回归到数据仓库最初的基本建设原则上来。
- 6.合并(1998-2001年)
两种思路和观点在实际的操作中都很难成功的完成项目交付,1998年,Bill Inmon提出了新的BI架构CIF(Corporation information factory),把Kimball的数据集市也包容进来。CIF的核心是将数仓架构划分为不同的层次以满足不同场景的需求,比如常见的ODS、DW、DM等,每层根据实际场景采用不同的建设方案,现在CIF已经成为建设数据仓库的框架指南,但自上而下还是自下而上的进行数据仓库建设,并未统一。
以上就是到目前为止,整体数仓建设来源的过程。
