前言
笔者在工作刚接触这部分知识的时候,翻阅了各种文档想要到一个比较通俗的理解数据仓库相关的介绍或是理解。之前只是在工作涉及数仓这块的一些业务,理论上有一定的缺失,所以最近准备刷一刷《数据仓库工具箱》这本书,顺便就将读完的一些理解和知识点在简书这边记录下来,算是对自己未来学习计划的一个鼓励和督促。
笔者是个渣渣,如有理解上的错误或者偏差,希望大家指点出来,互相学习讨论。
本文的目的主要是介绍数据仓库等一些概念或者是一些理解,所以涉及到一些资料,就直接附链接了。。
数据仓库和商业智能
基本概念的初步了解
在计算机领域,数据仓库(英语:data warehouse,也称为企业数据仓库)是用于报告和数据分析的系统,被认为是商业智能的核心组件。[1] 数据仓库是来自一个或多个不同源的集成数据的中央存储库。数据仓库将当前和历史数据存储在一起[2],用于为整个企业的员工创建分析报告。[3]
存储在仓库中的数据从运行系统(例如营销或销售)上传。这些数据可能会通过一个ODS数据库,并且可能需要进行额外操作的数据清理[2],以确保数据质量,然后才能在数据仓库中用于报告。
商业智能(Business Intelligence, BI),又称商业智能或商务智能,指用现代数据仓库技术、在线分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
商业智能的概念经由Howard Dresner(1989年)的通俗化而被人们广泛了解。当时将商业智能定义为一类由数据仓库(或信息市集)、查询报表、数据分析、数据挖掘、数据备份和恢复等部分组成的、以帮助企业决策为目的技术及其应用。
– wiki
前言中提到找一个比较通俗的理解,先附上链接:
文中主要提到了DW/BI,DM,元数据and数据元,ETL等概念,我觉得讲的挺不错的,篇幅也不长。

数据获取与数据分析
在大部分的企业架构中,一般会分为业务平台系统和数据处理系统。
其中平台组维护的业务平台确保了用户操作性数据的正常运转,比如用户的注册、登录,提交订单,上架商品等都算做事操作性数据。一般每一条数据都代表了一个事务记录,这些操作都是可预测的,成功commit,失败则rollback,所以对于操作系统来说,并不需要所有的历史数据,只需要时刻能反应整个业务系统的最新状态即可。
而DW/BI需要处理的是成千上万级别的事务记录用于分析并判断操作性数据是否处理一个正确的状态或者是对平台提供一个历史数据的直观性。
比如:本周与上周同一个店铺的环比分析,或者更细粒度的商品维度;亦或是在在实时数仓下风控业务中对于一些异常行为的预警。
为什么要有数据仓库?
请点击查看下面的链接,写的也很不错,通俗易懂。
说白了,在没有DW/BI之前,我们也可以完成数据分析,但是,因为数据量过大,存取数据或者是对数据的切片方便吗?数据指标正确吗?能够快速便捷的来应对不同维度的决策吗?数据中设计到用户的一些敏感信息的安全性怎么解决?
数据仓库的设计需求
由上面问题带来的业务需求如下:
-
方便的存取数据
DW/BI系统下的内容必须是易于理解的。这体现了数据的直观性,业务用户能以各种形式应对分割和合并数据,即:简单,快捷
-
数据的一致性
DW/BI系统的数据必须是可信的。对于DW的数据来源有业务系统的操作性数据、前端埋点数据、各种途径的采集日志。这些途径下带来的数据往往都是不同格式的,所以需要实现数据清洗(ETL),确保质量。
-
DW/BI系统必须能够适应变化
对于现实世界中或是业务系统无时不刻的改变的背景下,在设计DW/BI系统的时候一定要考虑到能够方便的处理无法避免的变化,这对操刀者对于数据的理解和业务上的需要有很深的理解,这样设计中来的系统才具有一定的适应性。
当业务问题发生变化,或者新数据增加DW中时,已经存在的数据和应用不应该被改变或者破坏。最后,如果必须修改DW/BI系统的描述性数据,要能以适当的方式描述变化,对于用户来说应该是透明的。
-
DW/BI系统的及时性
目前业内主流的的传统离线数仓(HADOOP,HIVE,KYLIN等)和近些年兴起的实时数仓(KAFKA,FLINK等)。前者一般为T+1的数据反馈,后者则可以依据窗口来实现各种窗口语义下的数据反馈。
-
DW/BI系统的安全性
数据仓库中设计到用户敏感信息的安全性问题,一般会进行脱敏,或者权限访问的控制,防止数据泄露。
现如今各大厂商的app或者应用都在无时不刻的采集用户的行为数据和轨迹分析,笔者有幸接触了某省*安的数据,越来越理会到:互联网时代,我们每个人都像是穿着衣服的裸体人。
-
DW/BI的权威性
DW/BI系统主要使用来分析和决策的,而这些决策的正确性也体现了DW/BI系统的影响和价值。所以在维护系统时,必须保证数据的准确性和权威性。
-
DW/BI系统的成功标志是业务群体接受DW/BI系统
我对这方面的理解是DW/BI的合理设计下,一些指标数据可以嵌入在业务系统中,来对用户提供数据上的直观性和一些决策。
例如,某app的商户信息中会在T+1展示前一天用户的PV,UV统计及TOP,商品受欢迎的TOP等,丰富了业务系统的功能和便捷性。
对于一个DW/BI系统的设计者来说,引用书上的一句话:
如果将DW/BI的管理者做一个类比,应该像一个高质量的杂志主编,应该有广阔的空间来管理杂志的内容,风格和发行。
维度建模
为什么要有维度建模?
一般在操作型业务业务系统中广泛使用了第三范式(3NF)来消除冗余。数据库常用的三范式感兴趣的可自行百度。
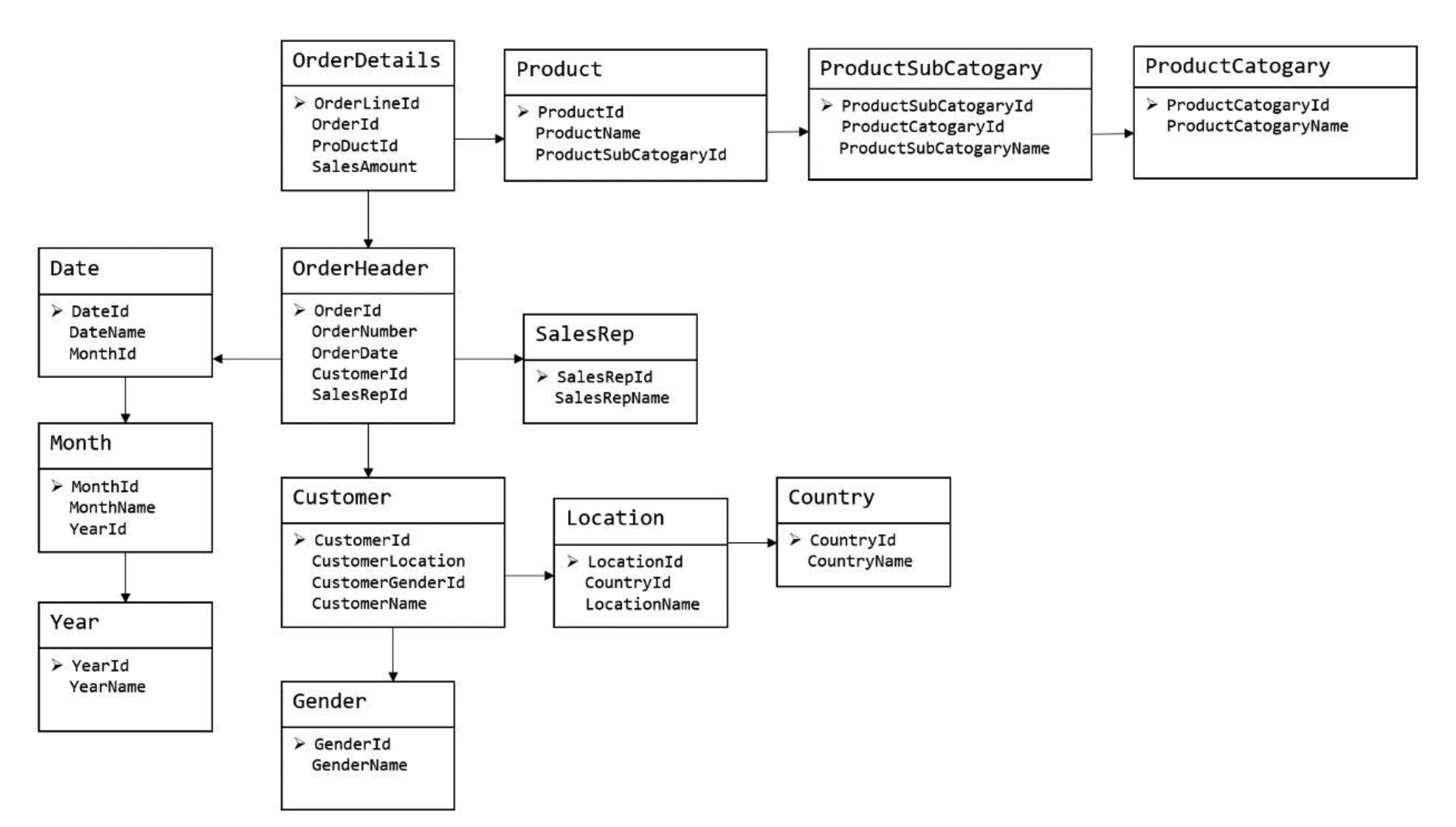
关系模型如上图所示,严格遵循第三范式(3NF),从图中可以看出,整个表结构之间较为松散、零碎, 物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地 被应用,功能性较强。关系模型主要应用与 OLTP 系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
但是,这样的设计直接使用在DW/BI系统中会导致模型的过度复杂以及查询上的性能灾难。试想一下你想统计在某个时间下的某个市场的某个商品的销售额,在传统数据库中需要关联多少张表。
凡事应该尽量简单,直到不能再简单为止。 – 爱因斯坦
维度建模解决了模式过分复杂的场景,其满足了一下两个场景的需求:
-
以商业用户可理解的方式发布数据
例如上述统计在某个时间下的某个市场的某个商品的销售额,这恰恰就是商业用户想知道的。
-
提供高效的查询性能
避免了多表关联导致的性能灾难。
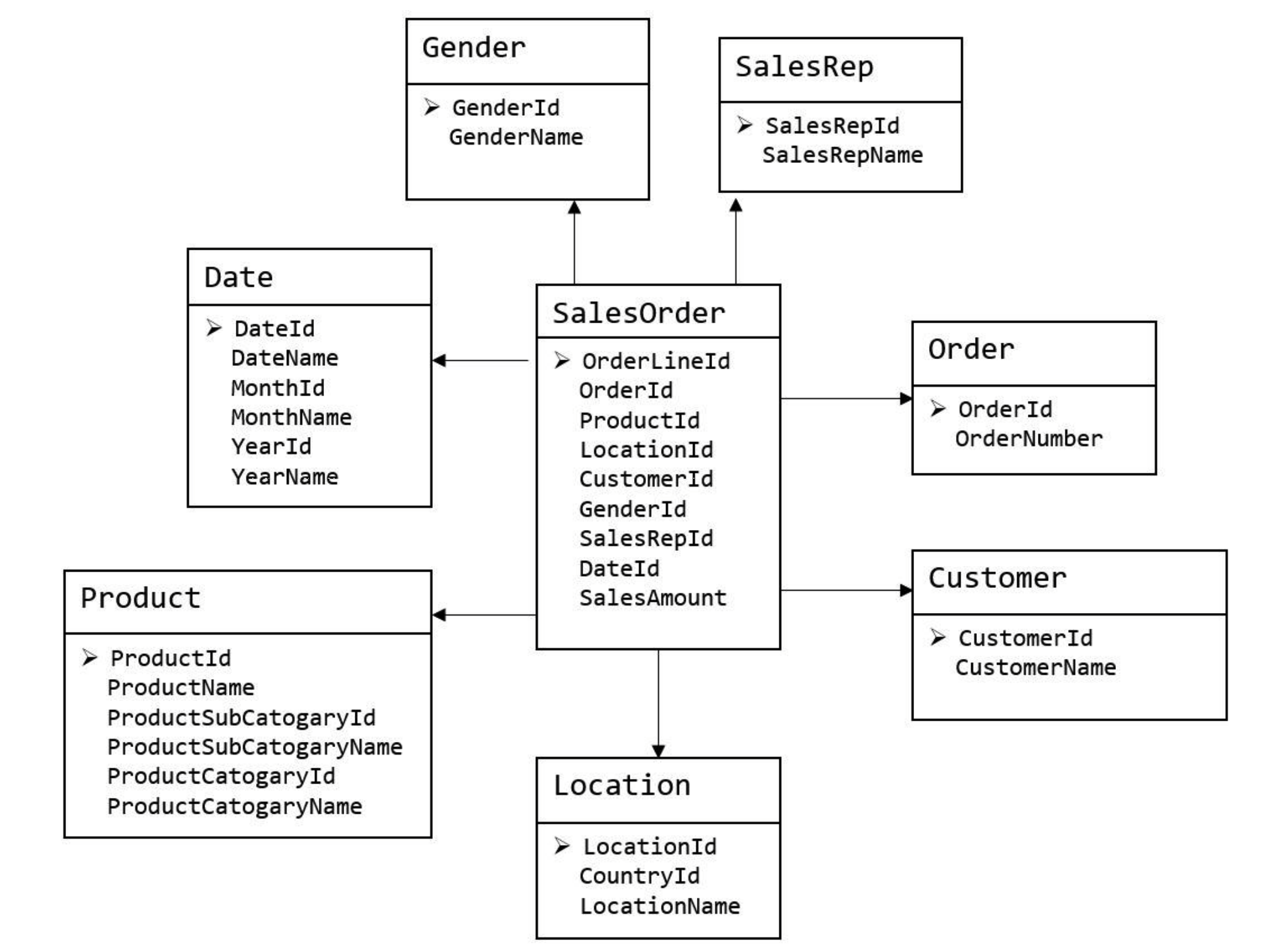
维度模型如图所示,主要应用于 OLAP 系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。例如业务用户可以用通过增加或者删除其中的属性,开展上钻和下钻操作,获得良好的分析性能,不需要提出新的查询。
可以看出,维度建模并不是遵守第三范式(3NF),严格上来说,维度建模是对某些表做了一定程度上的降维。
事实表和维度表
在了解维度建模的模型之前,先简要的介绍一下数据仓库设计中的两种表类型:事实表和维度表。
-
事实表
事实表中的每行对应一个度量(可统计次数、个数、件数、金额等)事件(下单、支付、退款、评价等。
每行中的数据是一个特定级别的细节数据,称为粒度。例如,销售事务中用一行来表示每个卖出的产品。维度建模的核心原则之一是同一事实表中的所有度量行必须具有相同的粒度。
事实通常以连续值作为描述,这样做有助于区分到底是事实还是维度属性的问题。
事实表通常包含多个外键用来与维度表的主键进行关联。
在存储上,事实表需要考虑空间的利用问题(ORC,PARQUET)。
事实表的特征:
-
非常的大 。
-
内容相对的窄:列数较少 。
-
经常发生变化,每天会新增加很多。
事实表的的粒度具体可以化分为3类:事务型事实表、周期性快照事实表、累计快照事实表。这里大家先简单知道这个概念。之后会专门结合具体案例来了解这3类事实表。
-
-
维度表
维度表一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。
例如:用户、商品、日期、地区等。
在存储上,维度表关注的是简单性和可访问性。
维表的特征:
-
维表的范围很宽(具有多个属性、列比较多) 。
-
跟事实表相比,行数相对较小:通常<10万条 。
-
内容相对固定:编码表。
-
维度建模之三种模型
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
- 星型模型
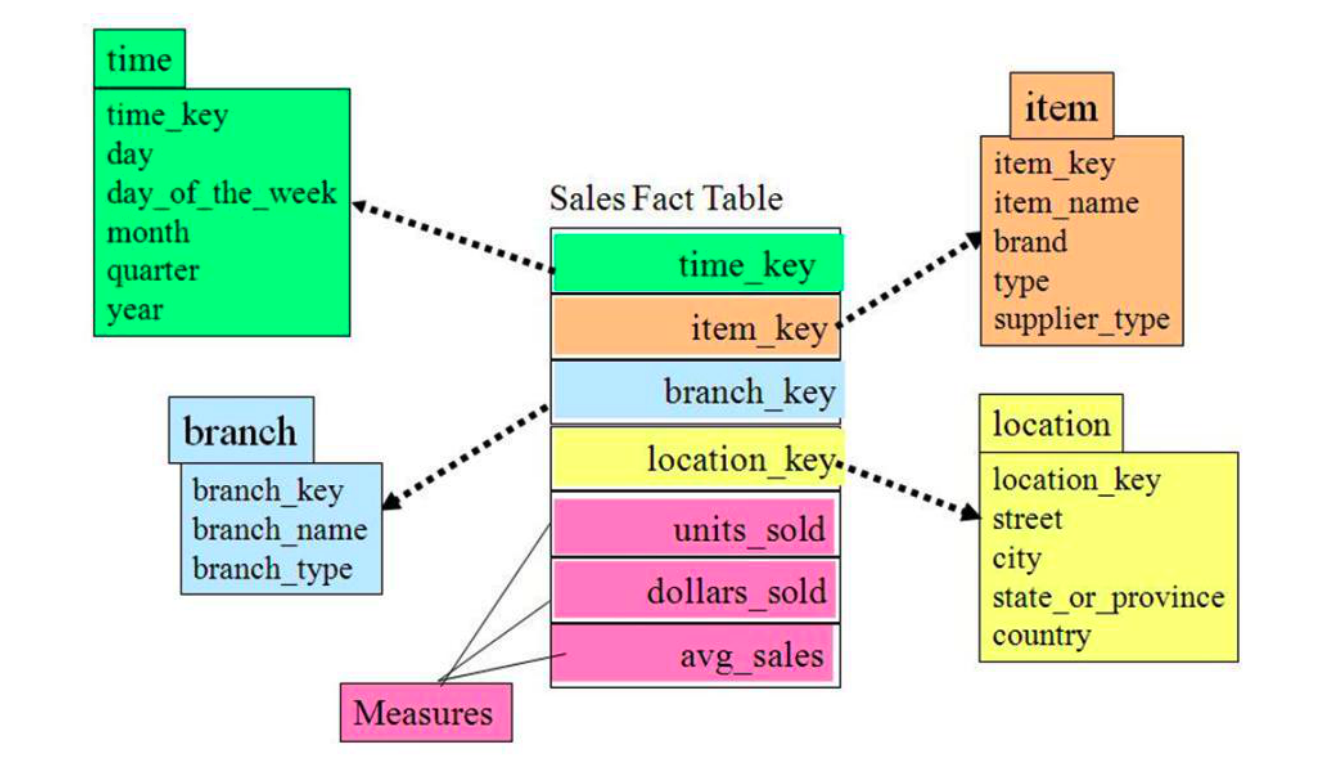
星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
特点:
-
维度表只和事实表关联,维度表之间没有关联。
-
每个维度表主键为单列,且该主键放置在事实表中,作为俩边连接的外键。
-
以事实表为核心,维度表围绕核心呈现星星分布
-
雪花模型
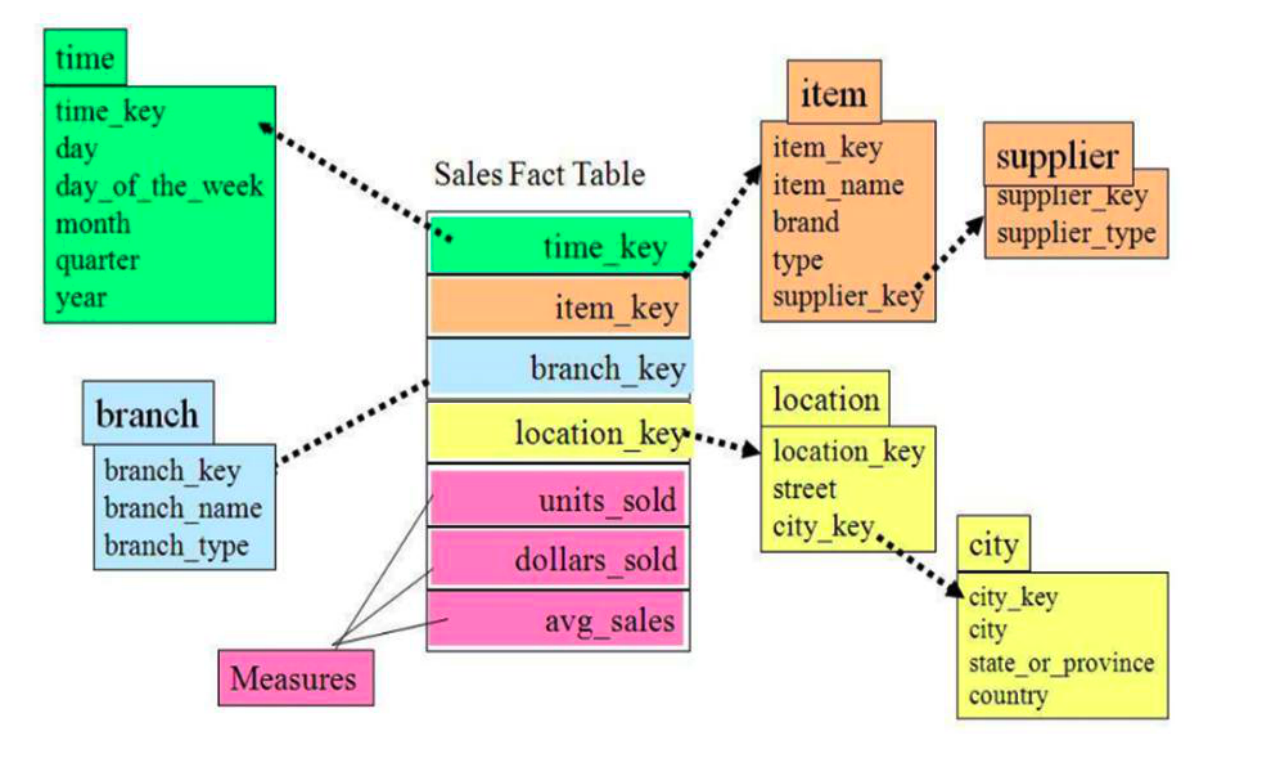
雪花模式的的维度表可以拥有其他维度表的但是由于这种模型维护成本太高,而且性能方面需要关联多层维度表,性能也比星型模型低。所以一般不常用。
-
星座模型
星座模式是由星型模式延伸而来**,**星型模式是基于一张事实表,而星座模式是基于多张事实表,而且共享维度表信息。在业务发展后期,绝大部分维度建模都采用的是星座模式
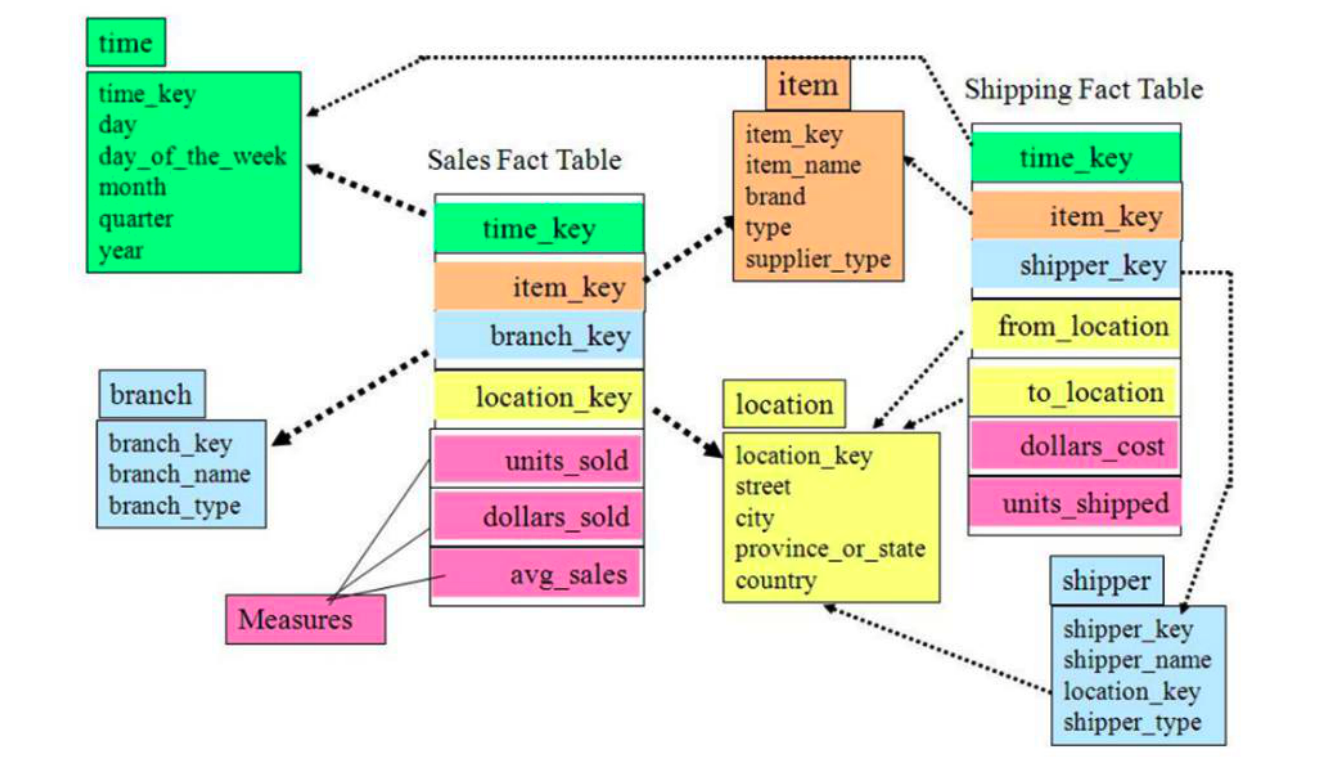
总的来说,雪花模型和星型模型的区别主要在于维度的层级,由上图可见,雪花模型更像关系型数据库的3NF,但是也不是完全遵守(3NF带来的性能成本过高),所以灵活性更高,冗余性更低,但相对的就是查询性能低下。在设计数仓的一种可能是维度表会在设计中使用雪花模型,因为维度表相对事实表来说小的多,影响不大。而标准的星型模型,周边的维度层级只有一层,也就是说对一些维表进行了一定程度上的降维。
所以说,性能优先,选星型模型;灵活性优先,选雪花模型。但从业界整体来看,更倾向于星型模型,因为在目前的大数据技术上来看,减少join就是减少了shuffle。
至于星座模型,在数据仓库汇中包含多个事实表的情况下,自然就构成了星座模型,所以星座模型和前两种模型是不冲突的。
总结
多数情况下,数据仓库的好坏直接取决于维度属性的设置;分别能力取决于维度属性的质量和深度。此外维度建模后表数量的减少(降维等操作)以及使用有意义的业务描述更容易被查询,减少了错误的发生。再者维度属性也带来了性能方面的好处,并且非常适于变化,维度模型可预测的框架可适应用户行为的变化。
by 俩只猴