1、写mapper、reducer和submitter的程序
mapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word:words)
{
context.write(new Text(word), new IntWritable(1));
}
}
}
reducer
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext())
{
IntWritable value = iterator.next();
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
submitter
/**
* 用于提交mapreduce job的客户端程序
* 功能:
* 1、封装本次job运行时所需的必要参数
* 2、跟yarn交互,运行mapreduce程序
*/
public class JobSubmitter {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//设置job运行时要访问的默认文件系统
conf.set("fs.defaultFS", "hdfs://192.168.137.128:9000");
//设置job提交到哪里
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "192.168.137.128");
Job job = Job.getInstance(conf);
//1、封装参数: 指定job所在的jar包
job.setJarByClass(JobSubmitter.class);
//2、封装参数: 本次job要调用的mapper实现类、reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//3、封装参数: 本次job的mapper、reducer实现类产生的结果数据的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//4、封装参数:本次job要处理的输入数据集所在的路径、最终输出结果的输出路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input/"));
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output/")); //输出路径必须不存在。否则会抛异常
//5、封装参数
job.setNumReduceTasks(2);
//6、提交job给yarn
boolean res = job.waitForCompletion(true);
}
}
2、将写好的程序倒出成jar文件。
idea中选择File --> Project Structure -->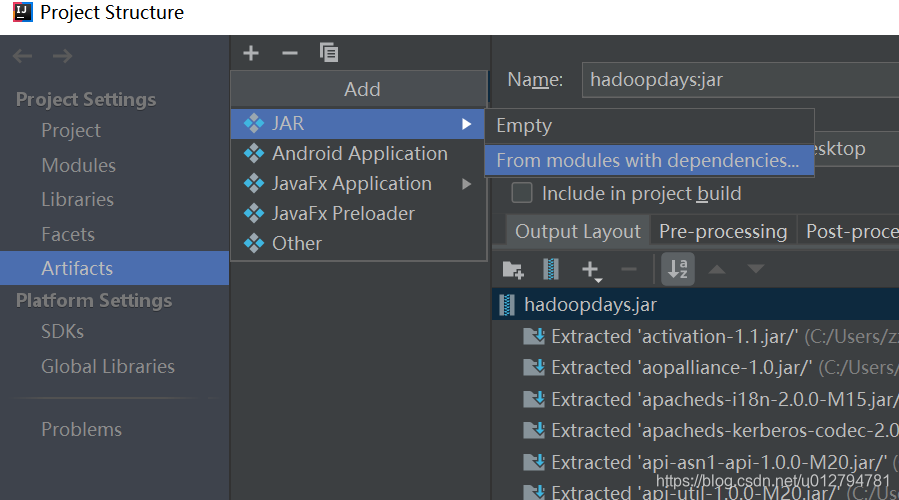
–> 选择main函数 --> 选择倒出的目标路径,确认。
在Build中选择Build Artifacts。
3、将jar文件上传到装有hadoop的服务器,并运行。
#hadoop jar hadoopdays.jar hadoopdays.src.main.java.JobSubmitter
最终在hdfs中的/wordcount/output中产生2个文件。
-rw-r--r-- 1 root supergroup 0 2018-12-04 09:28 /wordcount/output/_SUCCESS
-rw-r--r-- 1 root supergroup 18 2018-12-04 09:28 /wordcount/output/part-r-00000
-rw-r--r-- 1 root supergroup 44 2018-12-04 09:28 /wordcount/output/part-r-00001
内容如下:
lu 1
nihao 1
xy 1
hello 5
jim 1
tim 1
word 1
xh 1
zbx 2
zzx 2