1、环境需求
idea开发工具
maven 3.3.9
hadoop-2.7.7
jdk1.8
以上版本非必须,可根据自己的版本并修改下面的pom.xml对应版本号
基于windows本地hadoop实现
2、开始创建项目
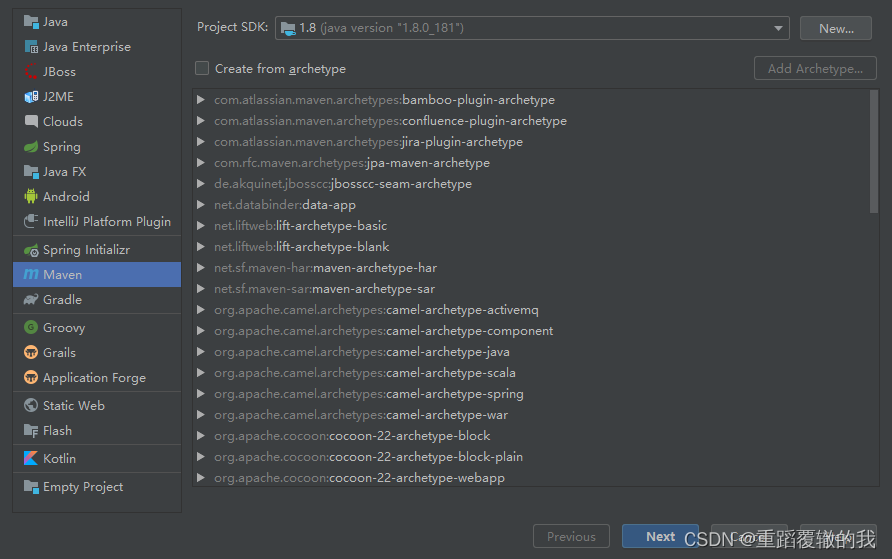
(1)、打开idea、创建maven项目。并选择SDK为jdk1.8,然后点击next。
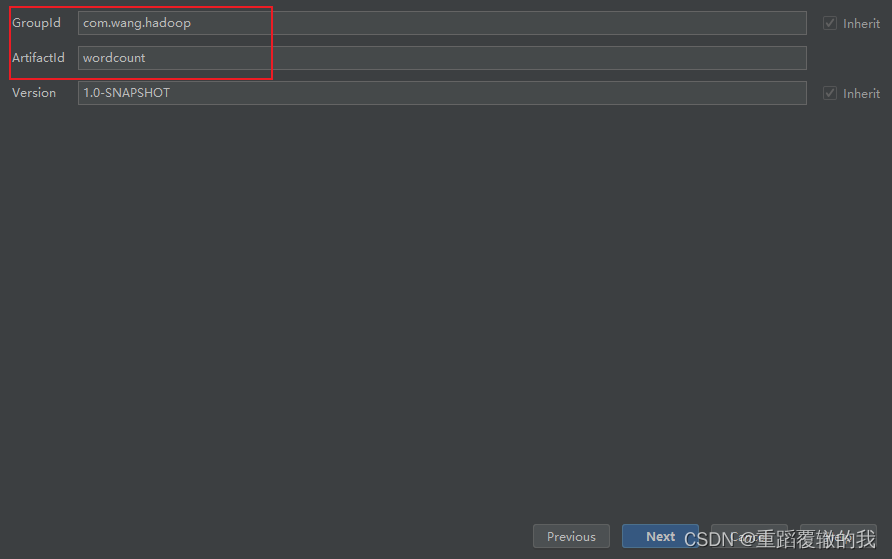
(2)、填写groupid和artifactid,然后点击next。
GroupId(俗称:包结构):GroupID是项目组织唯一的标识符,一般包含多段,第一段为域,第二段为公司名称,
实际对应项目的包名称;
ArtifactId(俗称:项目名):ArtifactID 就是项目的唯一的标识符,实际对应项目名称
(3)、填写项目名称和项目位置,然后点击finlsh,完成maven项目创建。
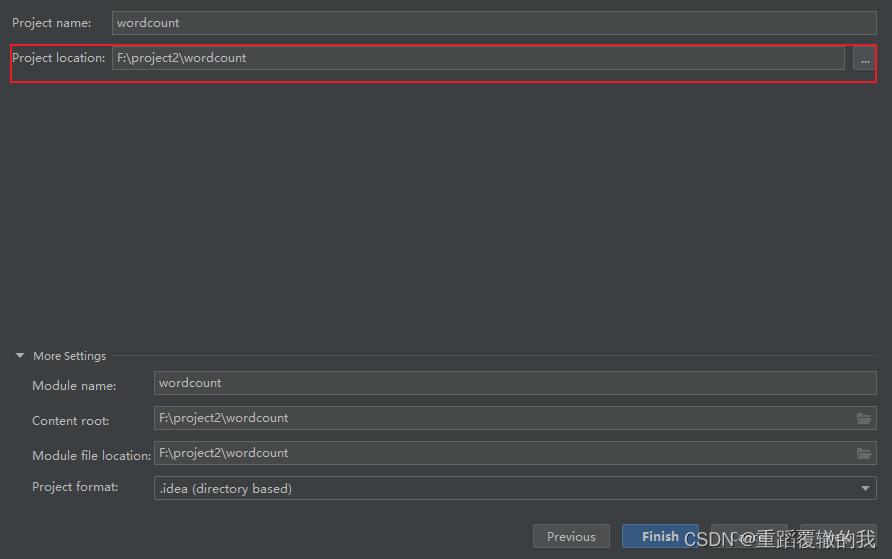
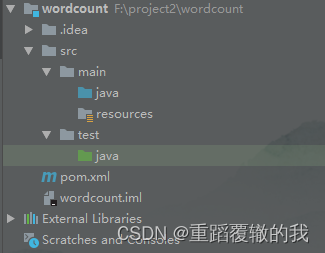
创建完成后的项目目录结构
3、pom中添加hadoop相关依赖
在pom.xml文件中添加hadoop相关依赖
<!--依赖版本管理 -->
<properties>
<java.version>1.8</java.version>
<hadoop.version>2.7.7</hadoop.version>
<log4j.version>1.2.14</log4j.version>
<junit.version>4.8.2</junit.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
</dependencies>
4、创建WordCountMapper
idea中可以使用 Ctrl+O快速重写父类方法。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取数据并将数据hadoop hive spark hive 按照空格进行切分,生成单词字符串数组。
String[] words = value.toString().split(" ");
//循环数组生成(hadoop,1),并由context上下文将数据输出。
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
5、创建WordCountReducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
//对(hadoop,1)(hadoop,1)...等,进行循环取值进行求和。
for(IntWritable v:values){
count += v.get();
}
//将聚合后的结果进行输出。
context.write(key,new IntWritable(count));
}
}
6、创建主程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public static void main(String[] args) throws IOException,
IllegalArgumentException, ClassCastException, ClassNotFoundException, InterruptedException, IOException {
// 加载配置类
Configuration conf = new Configuration();
// 获取Job对象
Job job = Job.getInstance();
// 设置jar存储的位置
job.setJarByClass(WordCount.class);
// 关联Mapper 和 reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置Mapper输出阶段的数据键值的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出阶段的数据键值的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输出和输入路径
FileInputFormat.setInputPaths(job, new Path("data/words.txt"));
FileOutputFormat.setOutputPath(job, new Path("data/out"));
//提交job
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
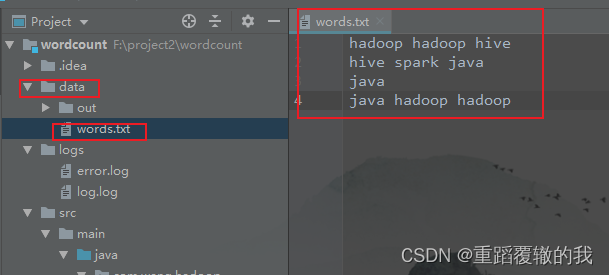
7、创建需要统计的数据文件
hadoop hadoop hive
hive spark java
java
java hadoop hadoop
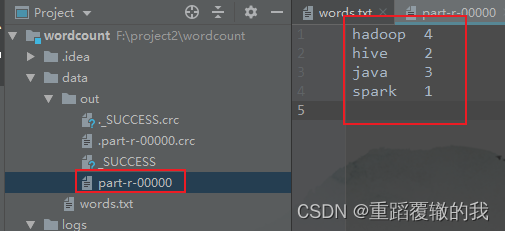
8、运行主类,并查看运行结果
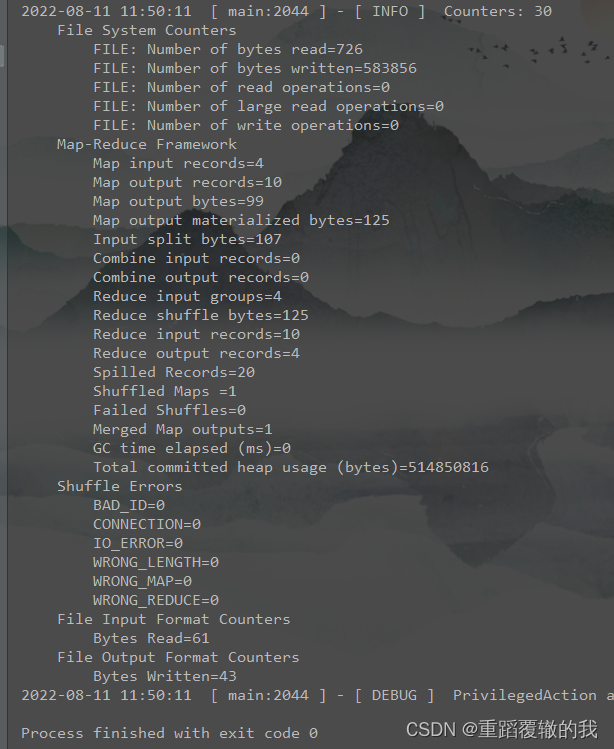
查看结果。