wordcount是MapReduce中最经典的一个案例 就是简单的统计一个文件中单词的个数
下面我们使用Java代码 编写一个一样功能的jar包,然后可以把这个jar包上传到Hadoop中 功能和wordcount一样
先导入依赖:
<dependencies>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<!-- hadoop版本必须和window下的hadoop版本一致 不然可能会报错-->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/jdk.tools/jdk.tools -->
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<!-- <systemPath>C:/Program Files/Java/jdk1.8.0_101/lib/tools.jar</systemPath>-->
<!--这里会报红 但是不用管 不影响我们的操作 -->
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
然后就可以编写代码了
mapper:
package com.jee.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//WcMapper类 用于处理map阶段的任务
//map阶段的任务 就是 我们一开始拿到的数据的格式 可能不是我们想要的格式 我们将它转化成我们想要的格式 然后交给reduce任务处理
// Mapper类的参数 : LongWriter就是Java中的long类型 第一个LongWriter表示我们接受到的数据的偏移量(偏移量就是这个数据离所在文件的头部的距离)
// Text 就是 Java中的String类型 第一个Text 表示我们所要处理的数据
// 最后两个参数表示我们转化后想要的类型 key-value Text表示字符串 IntWritable表示 int 就是Java中的 map<String,int>类型
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//我们将接受到的数据进行处理后 转化成map<String,int>类型 再交给reduce处理
//由于我们是统计单词个数 所以我们将接受到的数据转化成字符串 然后split 就可以得到一个个的单词 使用map类型 就是<单词,数量>
//将源数据转化成字符串
String line = value.toString();
//将字符串根据空格拆分成一个个的单词
String[] words = line.split(" ");
//遍历数组,将单词变成<word,1>的格式交给框架 由框架再交给reduce任务处理
for(String s : words){
word.set(s);
//写给框架
context.write(word,new IntWritable(1));
}
}
}
reduce:
package com.jee.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//reduce接受map任务处理好以后的数据 再对其进行处理
//Reduce的四个参数 : 前面两个是map任务传递给reduce任务的数据的格式 后面两个是reduce任务给MapReduce框架的key-value格式
public class WcReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable total = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//由于我们模拟的是统计单词的jar map任务就是把数据拆分成一个个的 <String,int> 格式,reduce任务就是对map任务处理后的数据在进行合并
int sum = 0;
//key代表我们map任务中统计的每个单词 values是一个迭代器
for(IntWritable I : values){
//累加
sum += I.get();
}
//包装结果 并输出
total.set(sum);
context.write(key,total);
}
}
driver:
package com.jee.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取一个Job实例
Job job = Job.getInstance(new Configuration());
//2.设置我们的类路径
job.setJarByClass(WcDriver.class);
//3.设置Mapper和Reduce
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReduce.class);
//4.设置Mapper和Reduce的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//5.设置输入输出数据
//args[0/1] 表示这个函数的参数
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//6.提交我们的Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
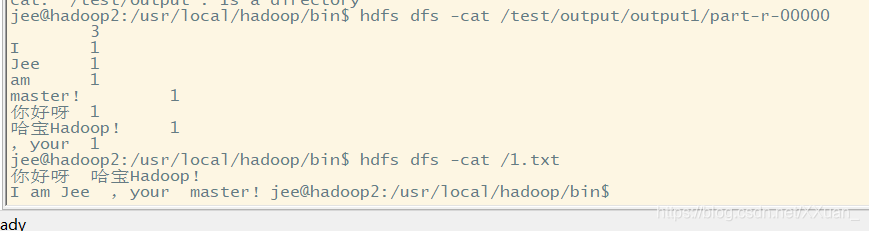
这样我们自定义的wordcount就写完了 我们可以将它打包成jar包 然后上传到我们的集群中 然后使用 hadoop jar 1.jar(jar包名) com.jee.wordcount.WcDriver(driver类的全名) /1.txt /test/output/output1 就可以运行我们自己写的jar包了

然后查看一下结果
下面来实现一个类的在Hadoop中的序列化 在Java中 类实现序列化是实现Serializable接口 , 而想还Hadoop中序列化一个类 需要实现Writable接口 并实现其方法 (这里是一个很简单的案例 我们要从一个文件中计算出 它的序号和总共使用的流量大小) 文件分多行 序号可能有重复 流量大小是每一行倒数第二的数值加上倒数第三个的数值
序列化的类
package com.jee.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//实现Writable接口 就可以实现一个类在Hadoop中的序列化
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
@Override
public String toString() {
return "FlowBean{" +
"upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
public void set(long upFlow,long downFlow){
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
}
public FlowBean() {
}
//序列化方法
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
//反序列化方法
// !!!! 注意 我们序列化的顺序和反序列化的顺序一定要相同 不然数据不匹配!!
public void readFields(DataInput dataInput) throws IOException {
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
sumFlow = dataInput.readLong();
}
}
Mapper类
package com.jee.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
//序号
private Text t = new Text();
//传递给reduce任务的自定义类
private FlowBean bean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//每一行不同数据之间用一个\t 制表符分隔
String[] items = line.split("\t");
t.set(items[1]);
bean.set(Long.parseLong(items[items.length-3]),Long.parseLong(items[items.length-2]));
context.write(t,bean);
}
}
Reducer类
package com.jee.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
private FlowBean r = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long upFlow = 0;
long downFlow = 0;
for(FlowBean flowBean : values){
upFlow += flowBean.getUpFlow();
downFlow += flowBean.getDownFlow();
}
r.set(upFlow,downFlow);
context.write(key,r);
}
}
Driver类
package com.jee.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job实例
Job job = Job.getInstance(new Configuration());
//2.设置类路劲
job.setJarByClass(FlowDriver.class);
//3.设置Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4.设置输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//5.设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//6.提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0: 1);
}
}
