1. 引言
此前的博客中,我们已经介绍了几个分类算法。
k 近邻算法
决策树的构建算法 – ID3 与 C4.5 算法
朴素贝叶斯算法的推导与实践
本文介绍的是另一个分类算法 – 逻辑斯蒂回归。
他凭借易于实现与优异的性能,拥有着十分广泛的使用,他不仅可以进行二分类问题的解决,也可以解决多分类问题,简单起见,本文我们只讨论二分类问题。
它的基本思想是利用一条直线将平面上的点分为两个部分,即两个类别,要解决的问题就是如何拟合出这条直线,这个拟合的过程就称之为“回归”。

2. 逻辑斯蒂算法推导
2.1. 几率函数与 logit 函数
假设一个事件发生的概率是 p,不发生的概率就是 1-p,那么 p/(1-p) 被称为事件发生的“几率”。
f§ = p/(1-p) 就是几率函数,举个简单的例子,足球赛上,A队对抗B队,胜率是 90%,那么通过几率函数可以求得 f(0.9) = 9,也就是说,在10场比赛中,A队可以平均获胜9场,在实际的生活中,几率函数比概率更为实用。
对几率函数取对数就是 logit 函数:
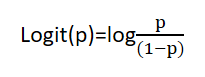
2.2. logistic 函数
我们将上面的例子看作在条件 X = 10 场比赛下,A队获胜概率为 90% 时得到的 A 队获胜 9 场的特征结果。
但我们需要解决的是符合一定特征的样本其属于某个类别的概率,这就需要队上面的函数求反,从而得到 logistic 函数,也称为 Sigmoid 函数:

2.3. 绘制 Sigmoid 函数图
通过下面的 python 代码我们可以绘制出 Sigmoid 函数的函数图:
import matplotlib.pyplot as plt
import numpy as np
def sigmoid(z):
return 1.0/(1.0 + np.exp(-z))
if __name__ == '__main__':
z=np.arange(-6, 6, 0.05)
plt.plot(z, sigmoid(z))
plt.axvline(0.0, color='k')
plt.axhline(y=0.0, ls='dotted', color='k')
plt.axhline(y=1.0, ls='dotted', color='k')
plt.axhline(y=0.5, ls='dotted', color='k')
plt.yticks([0.0, 0.5, 1.0])
plt.ylim(-0.1, 1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
plt.show()

3. 代价函数
假设我们的样本 x 具有 x1、x2、x3 。。。xn 等多个特征,通过添加系数 θ 可以得到下面的公式:
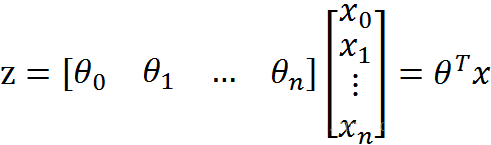
从而得到:
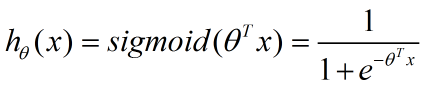
因为我们要解决二分类问题,所以我们只关心发生和不发生的概率,也就是 y=0 与 y=1 的解:
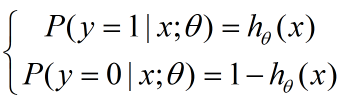
因为 y 只有 0 和 1 两个取值,我们可以通过下面函数将上面两个函数整合在一起:
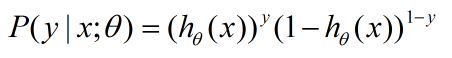
这个函数就是代价函数。
4. 极大似然估计
有了代价函数,我们只要找到所有的 θ 使得对于我们的所有样本都能成立就可以了,这个找 θ 的过程就是极大似然估计。
极大似然估计的目的就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值,从而将概率密度估计问题转化为参数估计问题。
但他有一个明显的前提需要保证:训练样本的分布能代表样本的真实分布。
p(x1, x2, x3, …, xn|θ) 被称为 {x1, x2, x3, …, xn} 的 θ 的似然函数。
在假设全部特征 x1, x2, x3 …, xn 均为独立特征的前提下,我们可以得到:
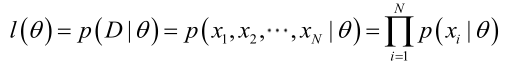
5. 梯度上升法求解极大似然函数
5.1. 准备求解
让 l(θ) 函数获得最大值的 θ 值就是我们想要的值。

正如上一篇日志中所写的,连续积运算通过对数转换为累加是数学中的常用方法,因此我们对上面函数两边求 log。
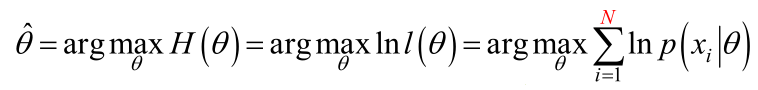
假设函数连续且任一点可导,那么,要计算一个函数结果取到极值时的参数值,我们通常只需要让函数的导数为 0 即可计算出函数取极值时的参数值。
我们定义梯度因子为:
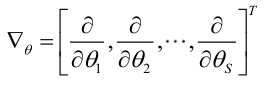
那么我们希望求解:
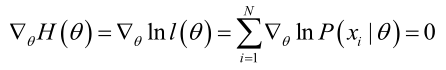
这个函数的直接求解太过复杂,因此不能直接求解,有几种方法可以通过迭代的方式得到近似的估计值,例如牛顿-拉菲森迭代方法。
本文我们介绍另一种迭代方法 – 梯度上升法,梯度上升算法和牛顿迭代相比更加易于理解,但收敛速度慢,因为梯度上升算法是一阶收敛,而牛顿迭代属于二阶收敛。
5.2. 梯度上升法
梯度上升法的原理是像爬坡一样,一点一点的向上爬,等到爬到山顶,那就已经非常接近我们的极值点了。
也就是说,每次比较上一次的函数值和本次的函数值,如果本次的函数值大于上一次的函数值,说明正处于上升阶段,否则说明已经进入了下降阶段,那么上次的点就是极值点。

但是这里有一个上升步长的问题,如果我们步子迈得太大,那么很容易就越过山顶了,最后只把半山腰上的某个点认成了极值点,而如果步子迈得太小,那么就会耗费更加大量的时间去不断地爬坡。
根据我们的经验,函数的导数是随着我们接近极值点而逐渐减小的,所以我们只要让步长正比于函数的导数,就可以让我们的步子随着极值点的接近越来越小,因此我们定义上升函数:
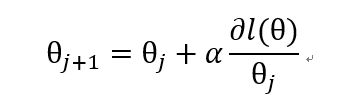
α 是步长系数。
5.3. 求解 l(θ) 的导数
现在,我们只要求出 l(θ) 导数带入上面的公式就可以利用梯度上升算法,求解 l(θ) 的极大值了。
接下来就是数学推导过程了:
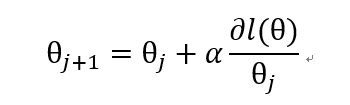
通过添加项的方法,我们可以将求导问题归类为三部分的求解:
- 第一部分
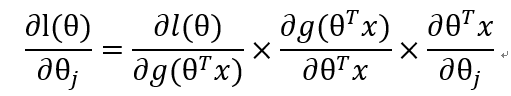
- 第二部分
根据:
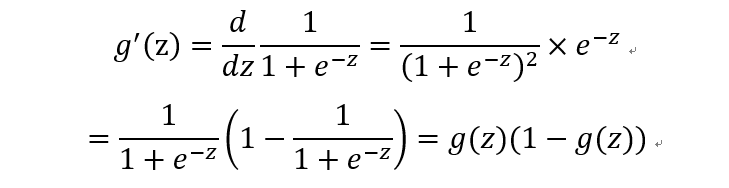
可得:
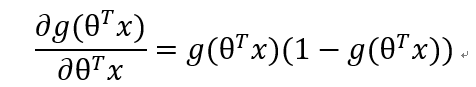
- 第三部分
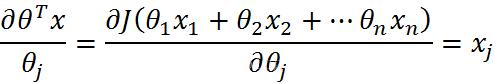
综上:
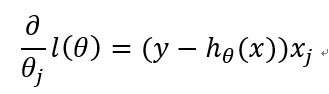
从而得到梯度上升迭代公式:
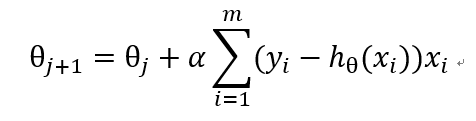
6. 参考资料
https://en.wikipedia.org/wiki/Maximum_likelihood_estimation。
https://en.wikipedia.org/wiki/Gradient_descent。
https://zlatankr.github.io/posts/2017/03/06/mle-gradient-descent。
https://blog.csdn.net/c406495762/article/details/77723333。
https://blog.csdn.net/zengxiantao1994/article/details/72787849。
https://blog.csdn.net/sinat_29957455/article/details/78944939。
https://blog.csdn.net/amds123/article/details/70243497。
https://blog.csdn.net/gwplovekimi/article/details/80288964。
https://www.cnblogs.com/HolyShine/p/6395965.html。