实验目的:
- 掌握选择排序、冒泡排序、合并排序、快速排序、归并排序的算法原理
-
分析不同排序算法的时间效率和时间复杂度,以及理论值与实测数据的对比分析。
一、冒泡排序
算法伪代码:
for i=1 to n
for j=0 to n-i
if ( data[j]>=data[j+1])
swap(data[j],data[j+1])算法思路:
第一个循环表示n-1趟即可完成排序。每一趟将最大的数调换位置到未排序数字的末尾。

数据分析:
由图1.冒泡排序的曲线图可以看出冒泡排序的时间增长基本符合二次增长,先选取以n=10000的实际时间t1作为理论时间的基准。
当n=20000时,t2=t1*(2/1)2、
当n=30000时,t3=t1*(3/1)2,以此类推做出表1。
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
171.1 |
669.75 |
1513.8 |
2580.85 |
3956.85 |
| 理论时间 (ms) |
171 |
684 |
1539 |
2736 |
4275 |
表1.10000为基准
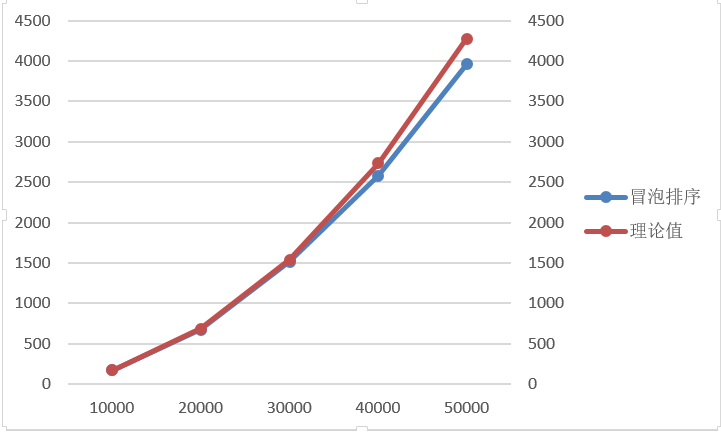
图1.冒泡排序
由图一可得,以n=10000为基准时,n=50000时理论和实际有一些偏差。怀疑是n=10000的实测时间可能是高于平均时长,所以我又以n=50000为基准做出下表。
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
171.1 |
669.75 |
1513.8 |
2580.85 |
3956.85 |
| 理论时间 (ms) |
158.274 |
633.096 |
1424.466 |
2532.384 |
3956.85 |
表2.以n=50000为基准
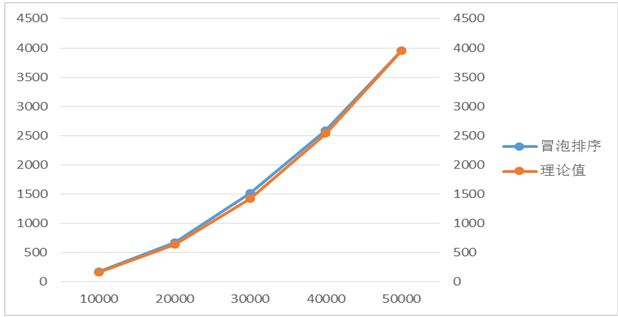
两条曲线基本拟合,说明当n=10000时所测得的实际时间比平均时间略长一点,所以导致后面的理论值偏大。
时间复杂度分析:
冒泡排序最好情况:数据本来已是正序,仅需要进行n-1次比较操作即可,时间复杂度为O(n)
冒泡排序最坏情况:数据是倒序排列,需要进行次的比较操作,还需要进行3* n(n-1)/2次的赋值移动操作。时间复杂度为O(n2)
冒泡排序的平均时间复杂度:第i趟排序需要进行n-i次比较,一共要进行n-1趟排序,所以由求和公式得一共要进行n(n-1)/2次的比较操作,移动操作次数也在n2级别,所以时间复杂度为O(n2)
二、选择排序
算法伪代码:
for i=0 to n-1{
k<-i
for j=k+1 to n-1{
if data[j]>data[k]
k<-j
}
If i!=k
Swap(data[i],data[k])
}算法思路:
在未排序数据中找到最小值,放到起始位置当成已排序数据,然后再从剩余序列中重复上述过程直到初始位置为数组最末尾。

数据分析:
由图2.选择排序的曲线图可以看出选择排序的时间增长基本符合二次增长,先选取以n=10000的实际时间t1作为理论时间的基准。
当n=20000时,t2=t1*(2/1)2、
当n=30000时,t3=t1*(3/1)2,以此类推做出表3
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
41.25 |
167.1 |
350.15 |
595.75 |
908.65 |
| 理论时间 (ms) |
41.25 |
165 |
371.25 |
660 |
1031.23 |
表3.以10000为基准的选择排序
由图2看出当数据规模到达40000、50000时理论值与实际值的误差较大,所以再以50000的实测时间作为基准,做出表4
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
41.25 |
167.1 |
350.15 |
595.75 |
908.65 |
| 理论时间 (ms) |
36.346 |
145.384 |
327.114 |
581.536 |
908.65 |
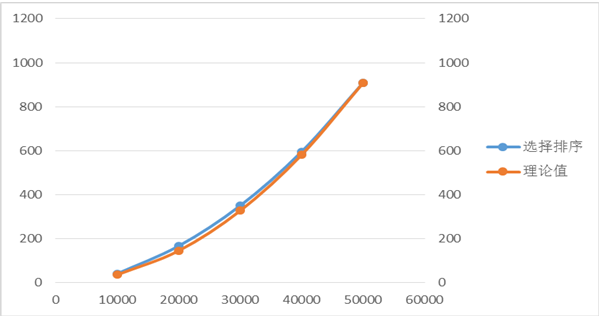
表4.以50000为基准的选择排序
以50000实测时间为基准时做出的理论值预测更贴近实际时间,我认为n=10000的实测时间比平均时间略大,且由曲线贴合程度也能得出此结论。
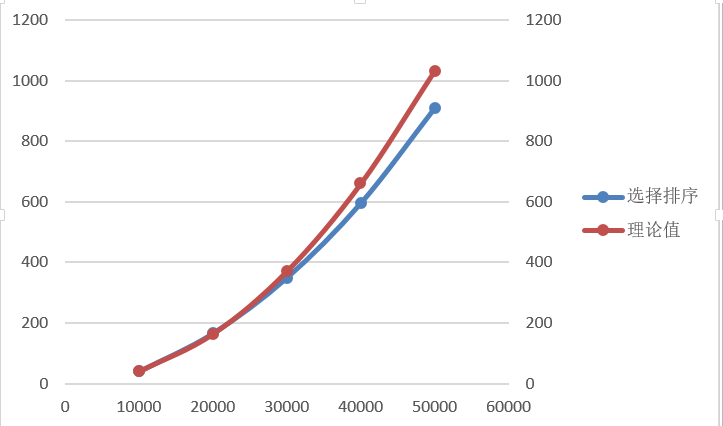
图2.选择排序
时间复杂度分析:
选择排序最好情况:数据已经为正序,则需要进行n(n-1)/2次比较操作但是移动操作次数为0。
选择排序最坏情况:数据为完全反序,则需要进行n(n-1)/2次比较操作和3(n-1)次移动操作。
选择排序的平均时间复杂度:需要选择n-1次最小数,第i次选择时需要遍历大小为n-i的数组。所以比较操作一定需要进行n(n-1)/2次。所以无论移动次数进行多少次,平均时间复杂度为O(n2).
三、插入排序
算法伪代码:
for i=1 to n-1{
insertNode<-data[i]
for j=i-1 to 0 when insertNode<data[j]
data[j] move backward
data[j]<-insertNode
}算法思路:
从第一个元素开始,此元素看做已排序元素,取出下一个元素向已排序元素中插入,从后向前扫描,直至所有元素插入已排序序列。就像打牌的时候,按牌的大小顺序整理牌的过程。

数据分析:
由图3.可以看出插入排序的时间增长也是基本符合二次增长,选取以n=10000的实际时间t1作为理论时间的基准。
当n=20000时,t2=t1*(2/1)2、
当n=30000时,t3=t1*(3/1)2,以此类推做出表5
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
18.2 |
79.6 |
173.75 |
287.5 |
471.35 |
| 理论时间 (ms) |
18.2 |
72.6 |
163.8 |
291.2 |
455 |
表5.以10000为基准

图3.插入排序
时间复杂度分析:
插入排序最好情况:数据为正序,则每次插入前仅需和前面一个数据比较,一共比较了n-1次,时间复杂度为O(n)。
插入排序最坏情况:数据为反序,则每次插入前要和前面的每一个数据比较,一共比较了n(n-1)/2次。时间复杂度为O(n2)
插入排序平均时间复杂度:平均情况下,在子数组A[1..j-1]中的一半元素小于A[j],一半元素大于A[j],所以我们检查子数组A[1..j-1]的一半,假设最坏情况下检查比较的次数为tj=j,则在这里我们的比较次数为tj=j/2,所以平均情况和最坏情况同属于O(n2)。
四、归并排序
算法伪代码:
Merge_Sort(data,low,high){
mid=(low+high)/2
if low< high{
Merge_Sort(data,low,mid)
Merge_Sort(data,mid+1,high)
Merge(data,low,mid,high)
}
}
Merge(data,low,mid,high){
i=low,j=mid+1
k=0
while i<=mid and j<=high{
if data[i]<data[j]
put data[i] into temp[k]
k++,i++
else
put data[j] into temp[k]
k++,j++
}
Put all rest elements into temp in order
}算法思路:
将有n个待排元素的表看成n个已排好序的子表,然后进行两两归并得到n/2个长度为2的有序子表,不断两两归并,直到归并成一个长度为n的有序表。

数据分析:
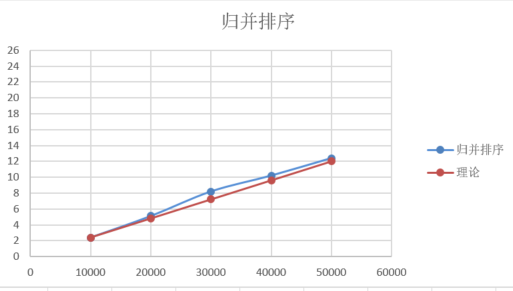
选取以n=10000的实际时间t1作为理论时间的基准。
当n=20000时,t2≈t1*2
当n=30000时,t3≈t1*3,以此类推做出表6
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
2.4 |
5.1 |
8.2 |
10.2 |
12.4 |
| 理论时间 (ms) |
2.4 |
4.8 |
7.2 |
9.6 |
12 |
表6.归并排序
时间复杂度分析:
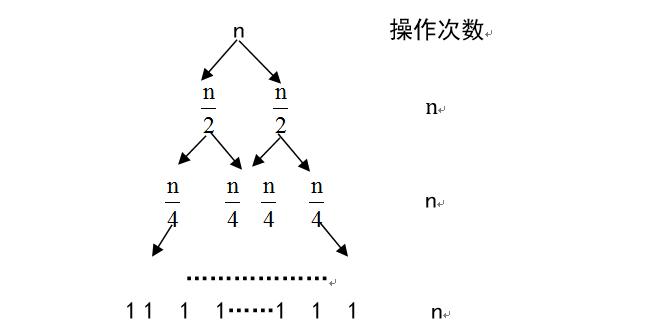
归并排序的递归树形式如上图所示,在自底向上的归并过程中每一层需要进行n次的比较归并操作。而树的深度为nlogn,所以归并排序的时间复杂度为O(nlogn)。
五、快速排序
算法伪代码:
Quick_Sort(data,low,high){
If low>=high
return;
index=partition(data,low,high) #index是基准的下标
Quick_Sort(data,low,index-1)
Quick_Sort(data,index,high-1)
}
Int partition(data,low,high){
key=data[low]
While low<high{
While data[high]>=key and low<=high
high-- #直到遍历完或者找到比基准小的值
data[low]=data[high] #把这个小值放到基准左边
while data[low]<=key and low<=high
low++ #直到遍历完或者找到比基准大的值
data[high]=data[low] #把这个大值放到基准右边
}
data[high]=key
return high #返回基准值的位置
}算法思路:
选取一个基准值,将比基准值大的元素移到基准右边,比基准值小的移动到左边,然后在左右两个子集中,重复上述操作直到所有子集仅有一个元素。
数据分析:
选取以n=10000的实际时间t1作为理论时间的基准。
当n=20000时,t2≈t1*2
当n=30000时,t3≈t1*3,以此类推做出表7
| 数据规模 |
10000 |
20000 |
30000 |
40000 |
50000 |
| 实际时间(ms) |
1.32 |
2.3 |
4.05 |
5.3 |
7.4 |
| 理论时间 (ms) |
1.32 |
2.64 |
3.96 |
5.28 |
6.6 |
表7.10000为基准
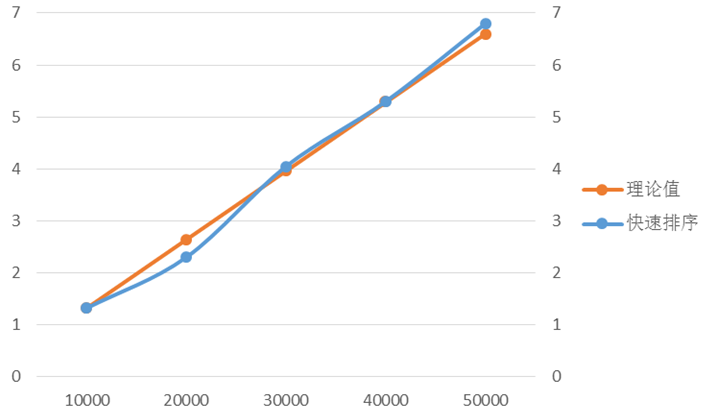
由图五可以看出快速排序的时间增长基本符合线性增长的规律,且实测时间与理论时间曲线基本吻合,误差都在0.1ms级别。
时间复杂度分析:
快速排序的最好情况:每一次选取的基准都恰好为子集的中间值,则左右子集的元素个数基本一样,则此时递归树的深度为logn,在每一层中的比较次数都小于等于n,此时时间复杂度为O(nlogn)
快速排序的最坏情况:每一次选取的基准都恰好为子集中的最大或最小值,则子集的规模仅比原规模小1,所以需要做n-1次划分。第i次划分开始时,区间长度为n-i+1,所需的比较次数为 n-i。所以这种情况下比较次数达到最大值n(n-1)/2,所以此时时间复杂度为O(n2)。
快速排序的平均时间复杂度:最坏情况的产生与算法或者是原待排数组无关,所以快速排序的平均时间复杂度由递归树方法可得为O(nlogn)。不考虑最坏情况的理由如下:每次划分后左右两个子集是无序的,每次选取子集第一个元素作为基准时,每一次此元素恰好是子集中的最值的概率非常小。
六、五种排序算法的比较
当数据规模从n=100变化到n=100W时,每种算法的时间增长折线图如下:
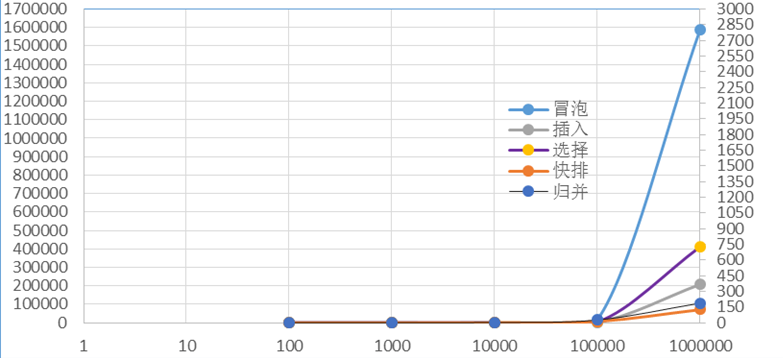
由图可知:快排>归并>插入>选择>冒泡。
(1) 时间复杂度同为O(n2),为什么又分快慢?
答:选择排序快于冒泡排序是因为,冒泡排序的移动次数很多,每当发现前者大于后者的时候就需要进行交换,移动次数可以达到n2级别,而选择排序最坏的情况下的移动次数也仅为3(n-1)次。
而插入排序比选择排序要快的原因则是每一趟选择排序要在剩下的数据中找到最小元素,则第i趟排序必须需要进行n-i次的比较。而插入排序将新元素插入到已排好序列中时,不一定每一次都要与前面的每一个元素进行比较,除非每一次要插入的元素比已排好序列中的每个值都小,所以插入排序要快于选择排序。
(2) 时间复杂度同为O(nlogn),为什么快排更快呢?
答:快速排序快在数据赋值操作少。在归并排序中,每两个子集合并时都要将两子集中所有元素写入到新数组中保存。则在每一层的归并中数据的写入操作一定为n。而在快速排序中,每一个子集中,并不需要移动每一个元素,因为很多比基准小的元素本来就在基准左边,比基准大的元素本来就在基准右边。所以同为O(nlogn),快速排序又更胜一筹。