冒泡排序
最简单的排序,原理非常简单,只要当前数比后面的数大,就把当前数往后移,直到数组末尾。
def bubble_sort(arr):
if len(arr) < 2:
return arr
j = len(arr) - 1
while j > 0:
for i in range(j):
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
j -= 1
return arr
选择排序
假设当前数是最小的数,找到之后最小的数,并将当前数和找到的最小的数互换,相对于先找最小,在慢慢往后找。
# 选择排序
def selectionSort(arr):
if len(arr) < 2:
return arr
for i in range(len(arr) - 1):
min_index = i
for j in range(i + 1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
插入排序
假设当前数及之前已经排好序,判断下一个数应该插入到之前排好序的中间那个位置,相对于从已经排好序的区间尾部开始判断,依次交换顺序,直到满足排序顺序。
# 插入排序
def insert_sort(arr):
if len(arr) < 2: return arr
for i in range(len(arr) - 1):
j = i + 1
while j > 0 and arr[j] < arr[j - 1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
j -= 1
return arr
归并排序
基本思想是,利用递归,将每个递归后排序完成的小区间合并,最终形成完整的排序
# 归并排序
def merge_sort(arr):
if len(arr) < 2: return arr
def process(arr, left, right):
if left == right: return
mid = left + (right - left) >> 1
process(arr, left, mid)
process(arr, mid + 1, right)
tmp = []
p1, p2 = left, mid + 1
while p1 <= mid and p2 <= right:
if arr[p1] < arr[p2]:
tmp.extend(arr[p1])
p1 += 1
else:
tmp.extend(arr[p2])
p2 += 1
while p1 <= mid:
tmp.extend(arr[p1])
p1 += 1
while p2 <= right:
tmp.extend(arr[p2])
p2 += 1
arr[left:right + 1] = tmp
return arr
return process(arr, 0, len(arr) - 1)
快速排序
基本思想是,按照某个值将数组划分,大于它的放右边,小于它的放左边,等于在中间。
递归划分每个区间,直到当前区间只有一个数,划分值选取当前区间的最后一个值。
# 快速排序
def quick_sort(arr, left, right):
def partition(arr, left, right):
# left, right = -1, len(arr)
index = left
left -= 1
tmp = arr[right]
while index <= right:
if arr[index] > tmp:
arr[index], arr[right] = arr[right], arr[index]
right -= 1
elif arr[index] < tmp:
arr[index], arr[left + 1] = arr[left + 1], arr[index]
left += 1
index += 1
else:
index += 1
# arr[-1], arr[right] = arr[right], arr[-1]
return [left + 1, right] # 返回等于的区间位置
if left < right:
tmp = partition(arr, left, right)
quick_sort(arr, left, tmp[0] - 1)
quick_sort(arr, tmp[1] + 1, right)
return arr
堆排序
首先将数组中的所有数建立成一个大跟堆,大跟堆的结构类似于完全二叉树,而且每个子树的中最大值都是根节点的值,而当前节点的根节点在数组中位置为 (i- 1)/ 2,所以只要判断新进的数是否比根节点的数大,大就交换位置,否则不换。依次从头到尾建立大跟堆结构。
建立好大跟堆结构后,数组中第一个数必然是最大的数,将它和数组中最后一个数交换,等于是从尾部开始排序,先找到最大的放末尾。但交换之后,一定不满足大跟堆结构,所以需要重新调整结构。调整结束后再次交换,不断重复。直到大跟堆的大小为0.
调整结构中,由于是从上开始调整,因此需要判断当前值和它的左右节点中,哪个最大就和谁交换位置,左节点的位置为 2*i + 1, 如果最大值是自己,则交换调整结束。
每一次调整之前,都要注意当前还需要调整的范围,因为数组的后面在之前操作中已经排好序,所以要注意边界。
# 堆排序
def heap_sort(arr):
if len(arr) < 2: return arr
for i in range(len(arr)):
heapInsert(arr, i)
arr[0], arr[-1] = arr[-1], arr[0]
heap_size = len(arr) - 1 # 需要调整的边界
while heap_size > 0:
heapify(arr, heap_size, 0)
arr[heap_size - 1], arr[0] = arr[0], arr[heap_size - 1]
heap_size -= 1
return arr
# 插入新值过程
def heapInsert(arr, index):
root = (index - 1) >> 1
while arr[root] < arr[index]:
arr[root], arr[index] = arr[index], arr[root]
index = root
root = (index - 1) >> 1
# 调整过程
def heapify(arr, heap_size, index):
left = 2 * index + 1 # 左节点
while left < heap_size:
largest = left + 1 if left + 1 < heap_size and arr[left + 1] > arr[left] else left
largest = largest if arr[largest] > arr[index] else index
if largest == index:
break
arr[largest], arr[index] = arr[index], arr[largest]
index = largest
left = 2 * index + 1
堆排序是在原数组上操作,因此空间复杂度为O(1),时间复杂度为O(NlogN)
计数排序
根据所给的数组,准备一个辅助数组,辅助数组的大小是待排序数组的中的最大数。遍历待排序数组,将每个数出现的次数记录在辅助数组相应的位置上,比如说4出现了3次,就在辅助数组4的位置上记3,没有出现过就是0.遍历结束后,按照辅助数组中的值恢复即可。
虽然计数排序很简单,速度也很快。时间复杂度为O(N),但实际运用的不多,因为它不能用于带小数的、或者为负数的,而且空间复杂度依赖于数据状况,因此缺陷也很大。
各种排序的时间复杂度和空间复杂度
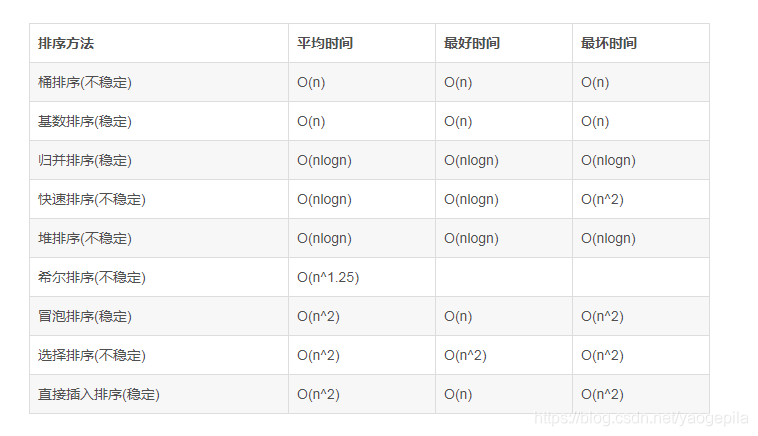
冒泡排序,选择排序,堆排序,插入排序,的空间复杂度为O(1)
快速排序空间复杂度为logn(因为递归调用了) ,
归并排序空间复杂是O(n),需要一个大小为n的临时数组