转载请标明出处SpringsSpace: http://springsfeng.iteye.com
1. 准备软件
CentOS 6.3 x86_64,jdk-6u37-linux-x64.bin, eclipse-jee-indigo-SR1-linux-gtk.tar.gz, hadoop-1.0.4.tar.gz
用户: kevin:NameNode、SecondNameNode、JobTracker、 DataNode、TaskTrack
2. 安装JDK与Eclipse
参考:http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/
3. 安装SSH
配置Hadoop集群时需要明确指定那个节点作为Master Node(NameNode and JobTracker),那些节点作
为DataNode(DataNode and TaskTracker), 而且MasterNode可以远程访问集群中的每一个节点。
Hadoop采用SSH来解决这个问题,SSH采用标准的公钥加密技术来创建一对密钥来进行用户验证,一个
是公钥,一 个是私钥。公钥存储于集群中所有节点上,当MasterNode访问一台远程的机器时,发送一个
私钥;远程机器将根据公钥和私钥来验证用户的访问权限。
(1) 定义一个公共的账户
针对Hadoop集群, 对集群中所有的节点应该使用相同的用户名(例如: fdc);若为了进一步加强安全,推
荐使用user-level的账户,这个账户只用于管理Hadoop集群。
(2) 验证已经安装的SSH
$ which ssh
$ which sshd
$ which ssh-keygen
如果执行上述命令获取到下面的提示信息:
/usr/bin/which: no ssh in (/usr/bin:/bin:/usr/sbin...
则需要自己动手安装SSH,可安装OpenSSH(www.openssh.com).
$ sudo apt-get install ssh
$ sudo apt-get install rsync
(3) 生成SSH 键值对
A. 生成密钥:[kevin@linux-fdc ~]$ ssh-keygen
B. 查看生成的公钥:[kevin@linux-fdc ~]$ ~/.ssh$ more id_rsa.pub
如果MasterNode和DataNode在同一台机器上时(Local Mode):
C. 加入受信列表: [kevin@linux-fdc ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(4) 验证SSH
//第一次需输入kevin账目密码
[kevin@linux-fdc ~]$ ssh localhost
(5) SSH服务配置文件
/etc/ssh/sshd_config ,如果该配置文件修改了,SSH服务需要重启:
sudo /etc/init.d/ssh reload
系统启动时启动sshd服务:chkconfig sshd on
(6) 关闭IPv6
A. 首先检查IPv6是否启动:
[kevin@linux-fdc ~]$ cat /proc/sys/net/ipv6/conf/all/disable_ipv6
0
返回值为:0,意味者IPv6启动,返回:1意味着IPv6没启动。
(7) 若执行上述操作之后,每次执行ssh localhost 都需要输入密码,解决方法如下:
cd /home/kevin/.ssh
[kevin@linux-fdc ~]$ chmod 600 authorized_keys
B. 系统全局停止IPv6:
修改系统文件:[kevin@linux-fdc ~]$ sudo gedit /etc/sysctl.conf ,添加:
#disable ipv6
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
重启电脑,配置生效。
C. 至针对Hadoop关闭IPv6:
修改文件:conf/hadoop-env.sh ,添加:
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
D. 关闭IPv6:
chkconfig iptable off
chkconfig ip6tables off
4. 安装配置Hadoop
(1) 解压Hadoop
tar -zxvf hadoop-1.0.4.tar.gz /usr/custom/hadoop-1.0.4 //将压缩包解压到:
/usr/customize/hadoop-1.0.4
请确保 /usr/custom/hadoop-1.0.4文件夹的属主和属组是当前用户:kevin.
(2) 设置Hadoop环境变量
[kevin@linux-fdc ~]$ sudo gedit /etc/profile
export HADOOP_HOME= /usr/custom/hadoop-1.0.4
export PATH=$PATH:$HADOOP_HOME/bin
(3) Hadoop中设置JDK
编辑Hadoop目录下的conf文件夹下的hadoop-env.sh文件,添加:
export JAVA_HOME=/usr/jdk/1.6.0_37
启用当前的修改:cd /usr/custom/hadoop-1.0.4
# source conf/hadoop-env.sh
环境变量设置参考:
# Set Java Environment
JAVA_HOME=/usr/custom/jdk1.6.0_37
HADOOP_HOME=/usr/custom/hadoop-1.0.4
M2_HOME=/usr/custom/apache-maven-3.0.4
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$M2_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME HADOOP_HOME M2_HOME PATH CLASSPATH LD_LIBRARY_PATH
(4) 配置文件
hadoop-env.sh
core-site.xml 配置:(hadoop.tmp.dir, fs.default.name,
mapred-site.xml配置 :mapred.job.tracker,
hdfs-site.xml 配置: dfs.replication.
hadoop-env.sh: 增加下面红色的两行:
# Set Hadoop-specific environment variables here. ...... # The java implementation to use. Required. # export JAVA_HOME=/usr/lib/j2sdk1.5-sun export JAVA_HOME=/usr/custom/jdk1.6.0_37 # Extra Java CLASSPATH elements. Optional. # export HADOOP_CLASSPATH= ...... # The scheduling priority for daemon processes. See 'man nice'. # export HADOOP_NICENESS=10 export HADOOP_HOME_WARN_SUPPRESS=TRUE
core-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>
The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.
</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/kevin/workspace-hadoop</value>
<description>A base for other temporary directories.</description>
<!--需要将home/kevin/workspace-hadoop目录的属主和属组改为当前用户,否则格式化
NameNode时报异常:java.io.IOException
-->
</property>
</configuration>
mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<description>
The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/kevin/workspace-hadoop/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/home/kevin/workspace-hadoop/mapred/system</value>
</property>
</configuration>
hdfs-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>
Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/kevin/workspace-hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/kevin/workspace-hadoop/hdfs/name</value>
<!--需要用当前账户手工建立目录:/home/kevin/workspace-hadoop/hdfs/name,执行
hadoop namenode -format时会格式化该目录,但不先建立该目录时会报告异常。 -->
</property>
</configuration>
(5) 验证Hadoop环境变量设置成功
执行命令:hadoop
将显示Hadoop文件操作命令。
(6) 验证masters和slaves文件:
cat masters
cat slaves
文件的内容均为localhost
5. 启动Hadoop
(1) 启动之前要先格式化NameNode,进入/usr/custom/hadoop-1.0.4目录,执行下面的
命令:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop namenode -format
(2) 启动Hadoop
[kevin@linux-fdc hadoop-1.0.4]$ bin/start-all.sh
(3) 查看后台程序
[kevin@linux-fdc hadoop-1.0.4]$ jps
查看监听的端口号:
[kevin@linux-fdc hadoop-1.0.4]$ sudo netstat -plten | grep java
或[kevin@linux-fdc hadoop-1.0.4]$ sudo netstat -nat
(4) 关闭Hadoop
[kevin@linux-fdc hadoop-1.0.4]$ bin/stop-all.sh
6. 查看NameNode状态和JobTracker状态
http://localhost:50070/dfshealth.jsp – Web UI of the NameNode daemon
http://localhost:50030/jobtracker.jsp – Web UI of the JobTracker daemon
http://localhost:50060/tasktracker.jsp – Web UI of the TaskTracker daemon
7. 安装Hadoop-Eclipse-Plugin
因为当前选择的Eclipse版本是3.7.2的,直接将hadoop-0.20.203.0rc1.tar.gz包中的
hadoop-eclipse-plugin-0.20.203.0.jar拷贝至eclipse的plugins目录下,在连接DFS时会
出现错误,提示信息为: "error: failure to login", 弹出的错误提示框内容为:"An
internal error occurred during: "Connecting to DFS hadoop".
org/apache/commons/configuration/Configuration".
网上针对该问题有已经有了解决方案,再次做个记录,方便自己以后查看,可参考:
http://blog.csdn.net/matraxa/article/details/7182382
解决方法:
首先要对hadoop-eclipse-plugin-0.20.203.0.jar进行修改。
用归档管理器打开该包 ,发现只有commons- cli-1.2.jar 和hadoop-core.jar两个包。
将HADOOP_HOME/lib目录下的 commons-configuration-1.6.jar ,
commons-httpclient-3.0.1.jar , commons-lang-2.4.jar , jackson-core-asl-1.0.1.jar
和 jackson-mapper-asl-1.0.1.jar 5个包通过归档管理器上的添加按钮添加到
hadoop-eclipse-plugin-0.20.203.0.jar的lib目录下;
然后,修改该包META-INF目录下的MANIFEST.MF,将classpath修改为一下内容:
Bundle-ClassPath: classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,
lib/commons-httpclient- 3.0.1.jar,lib/jackson-core-asl-1.8.8.jar,
lib/jackson-mapper-asl-1.8.8.jar,lib/commons-configuration-1.6.jar,
lib/commons-lang-2.4.jar
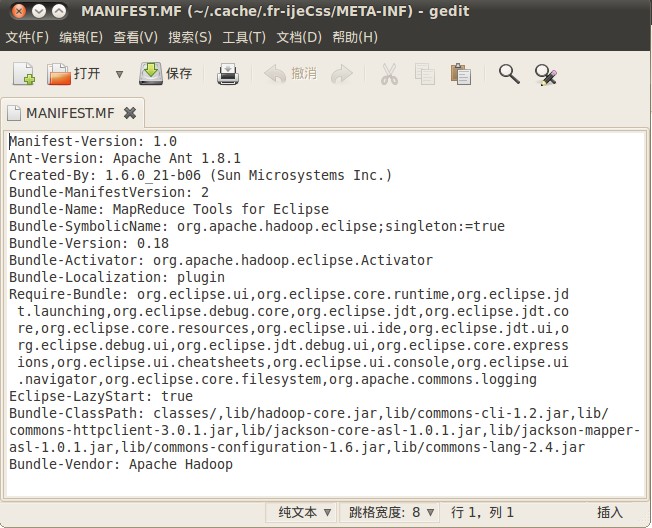
至此完成了对hadoop-eclipse-plugin-0.20.203.0.jar的修改。再将hadoop-eclipse-plugin-0.20.203.0.jar复制到
Eclipse的plugins目录下,重启Eclipse即可。
8. 配置Hadoop-Eclipse-Plugin
(1) Eclipse中打开Window-->Preferens,发现Hadoop Map/Reduce选项,在这个选项里配置
Hadoop installation directory。
(2) 配置Map/Resuce Locations:
在Window-->Show View->other...,在MapReduce Tools中选择Map/Reduce Locations。
在Map/Reduce Locations(Eclipse界面的正下方)中新建一个Hadoop Location。
在这个View中,点击鼠标右键-->New Hadoop Location。在弹出的对话框中你需要配置:
Location Name :此处为参数设置名称,可以任意填写。
Map/Reduce Master (此处为Hadoop集群的Map/Reduce地址, 应该和mapred-site.xml中的.
mapred.job.tracker设置相同)
Host: localhost
port: 9001
DFS Master (此处为Hadoop的master服务器地址,应该和core-site.xml中的 fs.default.name
设置相同).
Host: localhost
Port: 9000
设置完成后,点击Finish就应用了该设置。
附件hadoop-eclipse-plugin-1.0.1.jar位经过修改后可在Eclipse3.7.2中运行的插件。
9. 测试项目
运行hadoop-examples-1.0.4.jar例子。
(1) 准备输入数据
下载下面3个Plain Text UTF-8文件:
http://www.gutenberg.org/ebooks/4300
http://www.gutenberg.org/ebooks/5000
http://www.gutenberg.org/ebooks/20417
上述文件放在本机系统:/home/kevin/Documents/input/下。
(2) 将上述3个文件Copy至HDFS目录下的inputt文件夹下:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop fs -put /home/kevin/Documents/input/ input
查看:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop fs -lsr
(2) 运行示例程序:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop jar hadoop-examples-1.0.4.jar wordcount input output
此处hadoop-examples-1.0.4.jar需要写全称,否则会报异常:
Exception in thread "main" java.io.IOException: Error opening job jar: hadoop-examples-1.0.4.jar.
如果需要自定义Reduce任务的数量,可添加-D参数:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop jar hadoop-examples-1.0.3.jar wordcount
-D mapred.reduce.tasks=16 /home/fdc/temp/test /home/fdc/temp/test/test-output
此时可通过web interface查看运行情况。
(3) 查看运行结果:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop fs -lsr
输出结果:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop fs -lsr drwxr-xr-x - kevin supergroup 0 2012-11-24 14:50 /user/kevin/input -rw-r--r-- 1 kevin supergroup 674566 2012-11-24 14:50 /user/kevin/input/PG20417.txt -rw-r--r-- 1 kevin supergroup 1573150 2012-11-24 14:50 /user/kevin/input/PG4300.txt -rw-r--r-- 1 kevin supergroup 1423801 2012-11-24 14:50 /user/kevin/input/PG5000.txt drwxr-xr-x - kevin supergroup 0 2012-11-24 15:02 /user/kevin/output -rw-r--r-- 1 kevin supergroup 0 2012-11-24 15:02 /user/kevin/output/_SUCCESS drwxr-xr-x - kevin supergroup 0 2012-11-24 15:02 /user/kevin/output/_logs drwxr-xr-x - kevin supergroup 0 2012-11-24 15:02 /user/kevin/output/_logs/history -rw-r--r-- 1 kevin supergroup 19549 2012-11-24 15:02 /user/kevin/output/_logs/history/job_201211241400_0001_1353740545016_kevin_word+count -rw-r--r-- 1 kevin supergroup 20445 2012-11-24 15:02 /user/kevin/output/_logs/history/job_201211241400_0001_conf.xml -rw-r--r-- 1 kevin supergroup 880838 2012-11-24 15:02 /user/kevin/output/part-r-00000
将生成的part-r-00000文件Copy至本地查看:
[kevin@linux-fdc hadoop-1.0.4]$ bin/hadoop fs -getmerge /user/kevin/output/ /home/kevin/Documents/output
12/11/24 16:06:37 INFO util.NativeCodeLoader: Loaded the native-hadoop library
[kevin@linux-fdc hadoop-1.0.4]$ head /home/kevin/Documents/output/output
"(Lo)cra" 1
"1490 1
"1498," 1
"35" 1
"40," 1
"A 2
"AS-IS". 1
"A_ 1
"Absoluti 1
"Alack! 1