知乎是个好东西,深入理解一些理念,靠博客是不行的。
感受野计算和理解的内容参考自:https://zhuanlan.zhihu.com/p/44106492 / https://zhuanlan.zhihu.com/p/40267131
后两个卷积的内容参考自: https://www.zhihu.com/question/54149221
目录
五、从 感受野 分析 典型网络(vgg、resnet、rpn结构)
一、卷积后特征图维度的公式
首先,补充下计算卷积后特征图维度的公式:
N = (W − F + 2P )/S+1 (原图大小-kenal+2pad)/步长 +1
- 输出图片大小为 N×N
- 输入图片大小 W×W
- Filter大小 F×F
- padding: P
- 步长 S
二:感受野介绍:
stride : 网络中的每一个层有一个strides,该strides是之前所有层stride的乘积,即:
感受野:cnn中的特征图上一点,相对于原图的大小。
三、感受野的直观感受 和 作用
下图(该图为了方便,将二维简化为一维),这个三层的神经卷积神经网络,每一层卷积核的 ,
,那么最上层特征所对应的感受野就为如图所示的7x7。*(看箭头的时候从上往下反着看)
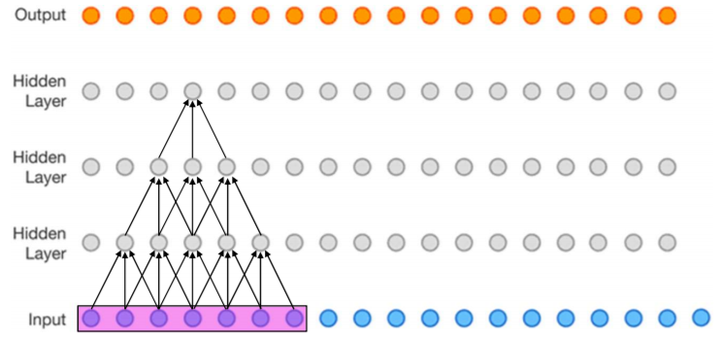
作用:这个重要的思想是在VGG的主要contribution( 3 个 3 x 3 的卷积层的叠加可以替代7*7的卷积,而这样的设计不仅可以大幅度的减少参数,其本身带有多次正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。)
- 小卷积可以代替大卷积层
- 密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
- 一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
- 目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
用这种等效的思想从感受野上看:两个堆叠的conv3x3感受野可以等于一个conv5x5,推广之,一个多层卷积构成的FCN感受野等于一个conv r*r,即一个卷积核很大的单层卷积,其kernelsize=r,padding=P,stride=S。cnn从gap划开,看成是FCN (全卷积网络)+MLP (多层感知机),前面提取特征后面加个分类器,可以理解成sobel+svm呗~CNN是不是就没那么神秘了~)
再来一个二维的图:

这里面有两个 3 x 3的的卷积,可以替代一个5*5的卷积。
四、感受野大小计算方式
其中 表示特征感受野大小,
表示层数,
,
输入层的: ,
,
。
- 第一层特征,感受野为3

第1层感受野[1]
- 第二层特征,感受野为5

第2层感受野[1]
- 第三层特征,感受野为7
第3层感受野[1]
如果有dilated conv的话,计算公式为
五、从 感受野 分析 典型网络(vgg、resnet、rpn结构)
计算Faster R-CNN(vgg16)中conv5-3+RPN的感受野,RPN的结构是一个conv3x3+两个并列conv1x1:

声明: 输入图片224*224, r表示感受野 , S表示stride, P表示padding, P的计算可以通过反推 N = (W − F + 2P )/S+1
r = 1 +2 +2 )x2 +2+2 )x2 +2+2+2 )x2 +2+2+2 )x2 +2 = 156
S = 2x2x2x2 = 16
P = ((14-1)x16-224+228)/2 = 106
分布方式为在paddding=106的输入224x224图像上,大小为156x156的正方形感受野区域以stride=16平铺。
接下来是Faster R-CNN+++和R-FCN等采用的重要backbone的ResNet,常见ResNet-50和ResNet-101,结构特点是block由conv1x1+conv3x3+conv1x1构成,下采样block中conv3x3 s2影响感受野。先计算ResNet-50在conv4-6 + RPN的感受野 (为了写起来简单堆叠卷积层合并在一起):
r = 1 +2 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 299
S = 2x2x2x2 = 16
P = ((14-1)x16-224+299)/2 = 141.5
P不是整数,表示conv7x7 s2卷积有多余部分。分布方式为在paddding=142的输入224x224图像上,大小为299x299的正方形感受野区域以stride=16平铺。
ResNet-101在conv4-23 + RPN的感受野:
r = 1 +2 +2x22 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 843
S = 2x2x2x2 = 16
P = ((14-1)x16-224+843)/2 = 413.5
分布方式为在paddding=414的输入224x224图像上,大小为843x843的正方形感受野区域以stride=16平铺。
以上结果都可以反推验证,并且与后一种方法结果一致。从以上计算可以发现一些的结论:
- 步进1的卷积层线性增加感受野,深度网络可以通过堆叠多层卷积增加感受野
- 步进2的下采样层乘性增加感受野,但受限于输入分辨率不能随意增加
- 步进1的卷积层加在网络后面位置,会比加在前面位置增加更多感受野,如stage4加卷积层比stage3的感受野增加更多
- 深度CNN的感受野往往是大于输入分辨率的,如上面ResNet-101的843比输入分辨率大3.7倍
- 深度CNN为保持分辨率每个conv都要加padding,所以等效到输入图像的padding非常大
六、 有效感受野
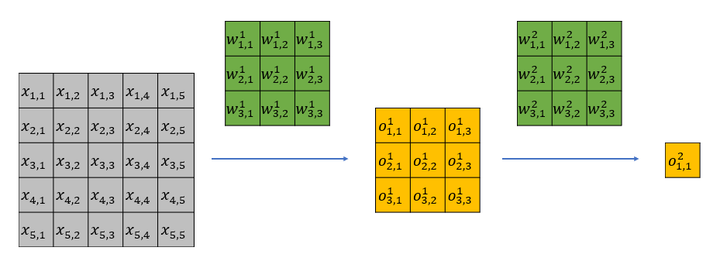
NIPS 2016论文Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出了有效感受野(Effective Receptive Field, ERF)理论,论文发现并不是感受野内所有像素对输出向量的贡献相同,在很多情况下感受野区域内像素的影响分布是高斯,有效感受野仅占理论感受野的一部分,且高斯分布从中心到边缘快速衰减,下图第二个是训练后CNN的典型有效感受野。



下面我从直观上解释一下有效感受野背后的原因。以一个两层 ,
的网络为例,该网络的理论感受野为5,计算流程可以参加下图。其中
为输入,
为卷积权重,
为经过卷积后的输出特征。
很容易可以发现, 只影响第一层feature map中的
;而
会影响第一层feature map中的所有特征,即
。
第一层的输出全部会影响第二层的 。
于是 只能通过
来影响
;而
能通过
来影响
。显而易见,虽然
和
都位于第二层特征感受野内,但是二者对最后的特征
的影响却大不相同,输入中越靠感受野中间的元素对特征的贡献越大。
七、 论文中用法
ECCV2016的SSD论文指出更好的anchar的设置应该依据感受野:

ICCV2017的SFD依据有效感受野设置anchor并使其密集化,这一做法在RefineNet中延续:


DeepLab提出Atrous conv (带孔卷积)高效控制感受野,而不增加参数数量和计算量:
- 分类
Xudong Cao写过一篇叫《A practical theory for designing very deep convolutional neural networks》的technical report,里面讲设计基于深度卷积神经网络的图像分类器时,为了保证得到不错的效果,需要满足两个条件:
Firstly, for each convolutional layer, its capacity of learning more complex patterns should be guaranteed; Secondly, the receptive field of the top most layer should be no larger than the image region.
其中第二个条件就是对卷积神经网络最高层网络特征感受野大小的限制。
- 目标检测
现在流行的目标检测网络大部分都是基于anchor的,比如SSD系列,v2以后的yolo,还有faster rcnn系列。
基于anchor的目标检测网络会预设一组大小不同的anchor,比如32x32、64x64、128x128、256x256,这么多anchor,我们应该放置在哪几层比较合适呢?这个时候感受野的大小是一个重要的考虑因素。
放置anchor层的特征感受野应该跟anchor大小相匹配,感受野比anchor大太多不好,小太多也不好。如果感受野比anchor小很多,就好比只给你一只脚,让你说出这是什么鸟一样。如果感受野比anchor大很多,则好比给你一张世界地图,让你指出故宫在哪儿一样。
《S3FD: Single Shot Scale-invariant Face Detector》这篇人脸检测器论文就是依据感受野来设计anchor的大小的一个例子,文中的原话是
we design anchor scales based on the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》这篇论文在设计多尺度anchor的时候,依据同样是感受野,文章的一个贡献为
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via enriching
receptive fields and discretizing anchors over layers

