出自https://blog.csdn.net/u010725283/article/details/78593410
论文阅读笔记: 2016 cvpr Convolutional Pose Machines
本博客主要学习介绍2016 cvpr的一篇文章,这篇文章用于人的姿态估计,来自卡内基梅隆大学感知计算实验室Carnegie Mellon University。
主要思想
论文设计的网络分为多个阶段(stage):前面阶段使用原始图片作为输入,后面阶段使用之前阶段生成的特征图作为输入,这样做主要是为了融合空间信息,纹理信息。
论文中,为了进一步提升精度,采用加大网络的感受野的方式来学习各个部件 parts 之间的空间几何约束关系, 保证精度的同时考虑各个部件的远距离关系.
同时,网络采用全卷机网络(FCN), 可以 end-to-end joint training, 同时为了防止梯度消失, 在各个阶段中添加监督信息, 避免网络过深难以优化的问题.
算法流程
这里讲解一下整个算法的流程。由于该算法是针对姿态检测的数据库设计的,而姿态检测数据库中存在活跃标签,即在多个人物中,最显著的单人物标记。论文称之为 center map。因此,网络考虑了 center map 的应用。
首先,网络输入图像特征, 使用较小的感受野回归各个人的关节的点, 得到各个部件的 belief map 特征谱。
接下来,融合上一阶段生成的特征谱 belief map \ 中心谱 center map 以及输入图像的图像特征, 使用较大的感受野回归各个人的关节点,这里就相当于融合了关节点的空间信息,并且去除掉了其他人的响应, 从而输出新的特征谱 belief map.
最后,在最后一个阶段stage得到各个部件的特征谱 belief map, 找出相应最大的点, 即为部件位置.
网络结构
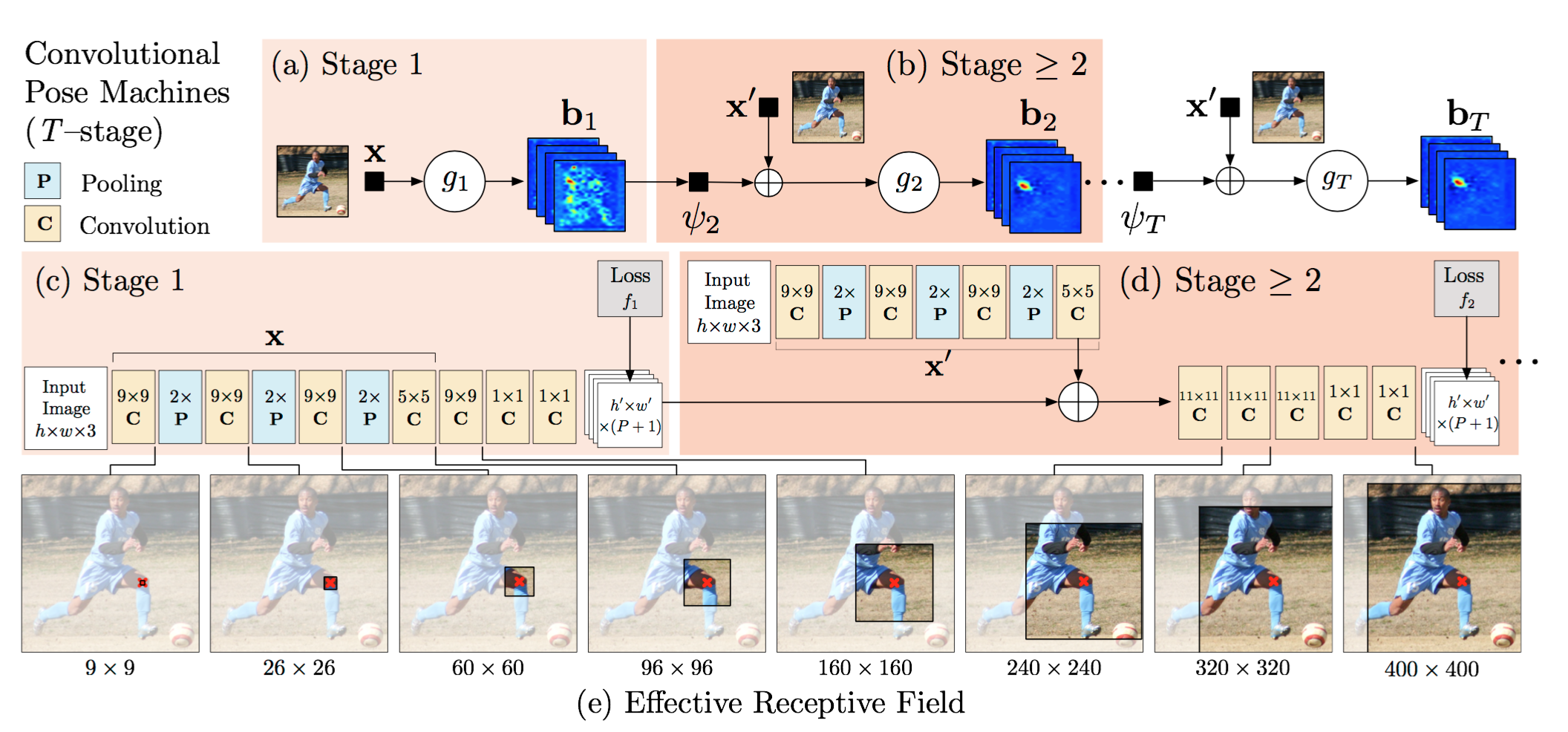
Stage 1 input是原始图像,经过全卷机网络,输出是一个P+1层的2Dmap。其中,全卷积网络中有7个卷积层,3个池化层,原始输入图片是 368*368 ,经过3次池化后得到 46*46 大小。又因为这里使用的数据库是半身结构,只有9个关节点,因此加上背景,输出的响应图大小应该是 46*46*10。
Stage 2 input是 Stage1 的 Output 响应谱,并且加上原始图像通过几层网络后的特征谱 feature map。输出是一个P+1层的2Dmap。其中,stage 2 融合了三部分的信息–一是stage1的响应图,二是原始图像的图像特征,三是高斯模版生成的中心约束。图像深度变为10+32+1 = 43。
Stage 3 及其后面各个阶段的网络结构和 Stage 2 相似
为了防止训练时出现梯度消失的问题:论文采用了中层监督(加入中层loss),加强反向传播。
注: 在cpm网络结构中,网络有一个格外的输入: center map,center map为一个高斯响应。因为cpm处理的是单人pose的问题,如果图片中有多人,那么center map可以告诉网络,目前要处理的那个人的位置。因为这样的设置,cpm也可以自底向上地处理多人pose的问题。
图像标签:ground true
论文是这样生成 ground true的:在每个关节点的位置放置一个高斯响应,来构造响应图的真值。对于一个含有多个人的图像,生成两种真值响应,一是在每个人的相应关节位置,放置高斯响应。二是只在标定的人的相应关节位置,放置高斯响应。

由于第一阶段只能考虑局部特征,故将每个人的相应关节位置用于第一阶段网络训练,标定的人的相应关节位置用于后续阶段网络训练。这部分操作由cpm_data层实现。即从标定的集合位置生成两个label数据,分别传给不同阶段的loss层。
数据预处理
为了获得较好的测试结果,论文对输入图像数据进行了数据增强操作。
- 数据增强: 对原始图片进行随机缩放,旋转,镜像,仅仅在训练时使用。这些操作在caffe层cpm_data中实现
- 多尺度: 训练时,通过cpm_data层对数据进行了尺度扩充。因此在测试时,直接从原图生成不同尺度的图像,分别送入网络。将所得相应结果求和,将会获得不错的结果

数据集及实验
论文进行了相应的实验,通过实验证明,使用大的感受野具有的良好的效果.
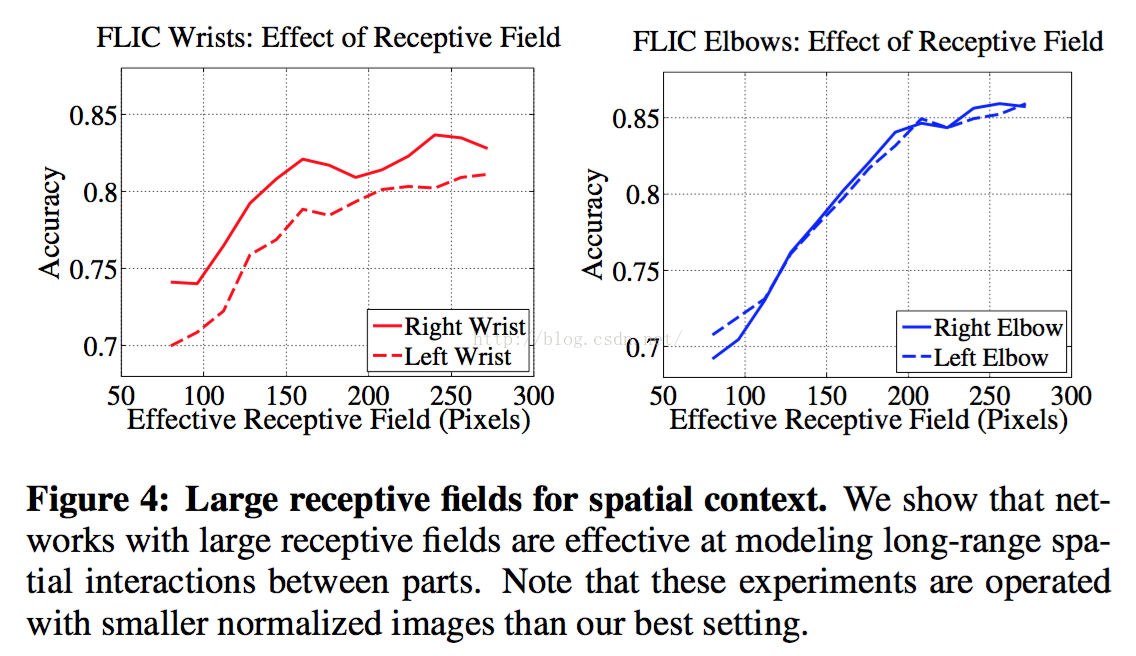
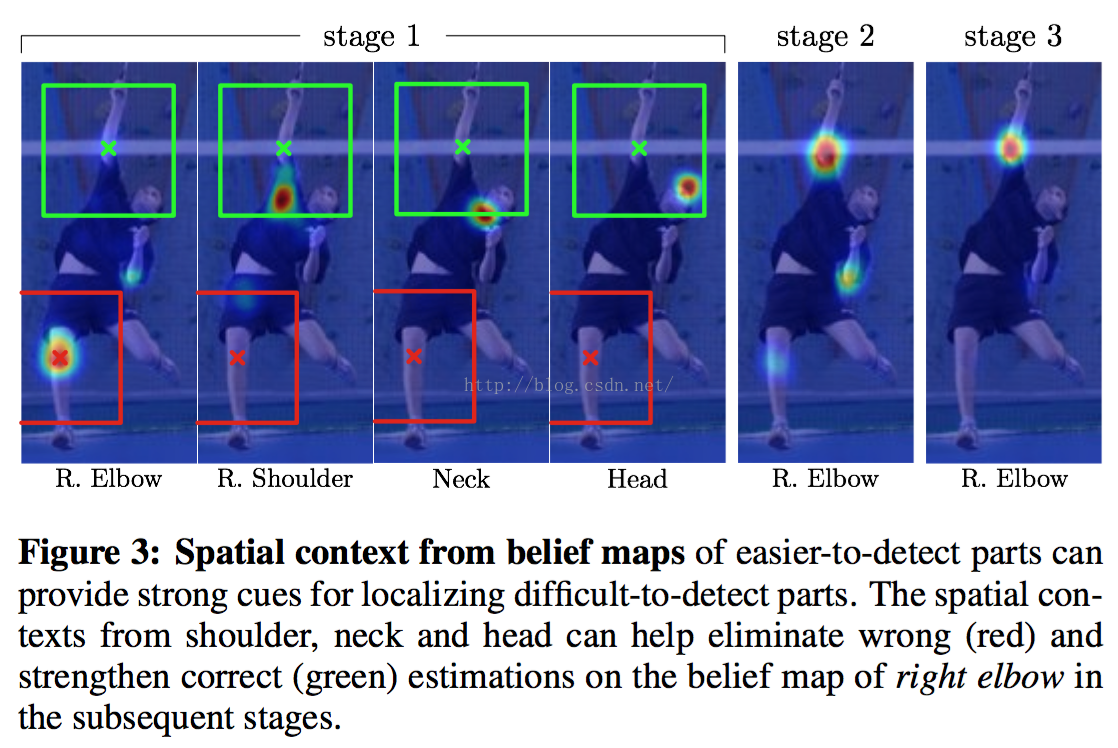
同时,随着stage的增长,CPM会学习到parts之间的空间几何约束关系来纠正容易出错的情况.
下面是论文使用的数据集,以及数据集的相关介绍。
数据集 类别 部件数 训练/测试样本数
FLIC 半身,影视 9 3987/1016
LSP 全身,体育 14 11000/1000
MPII 全身,日常 14 28000/
- 1
- 2
- 3
- 4
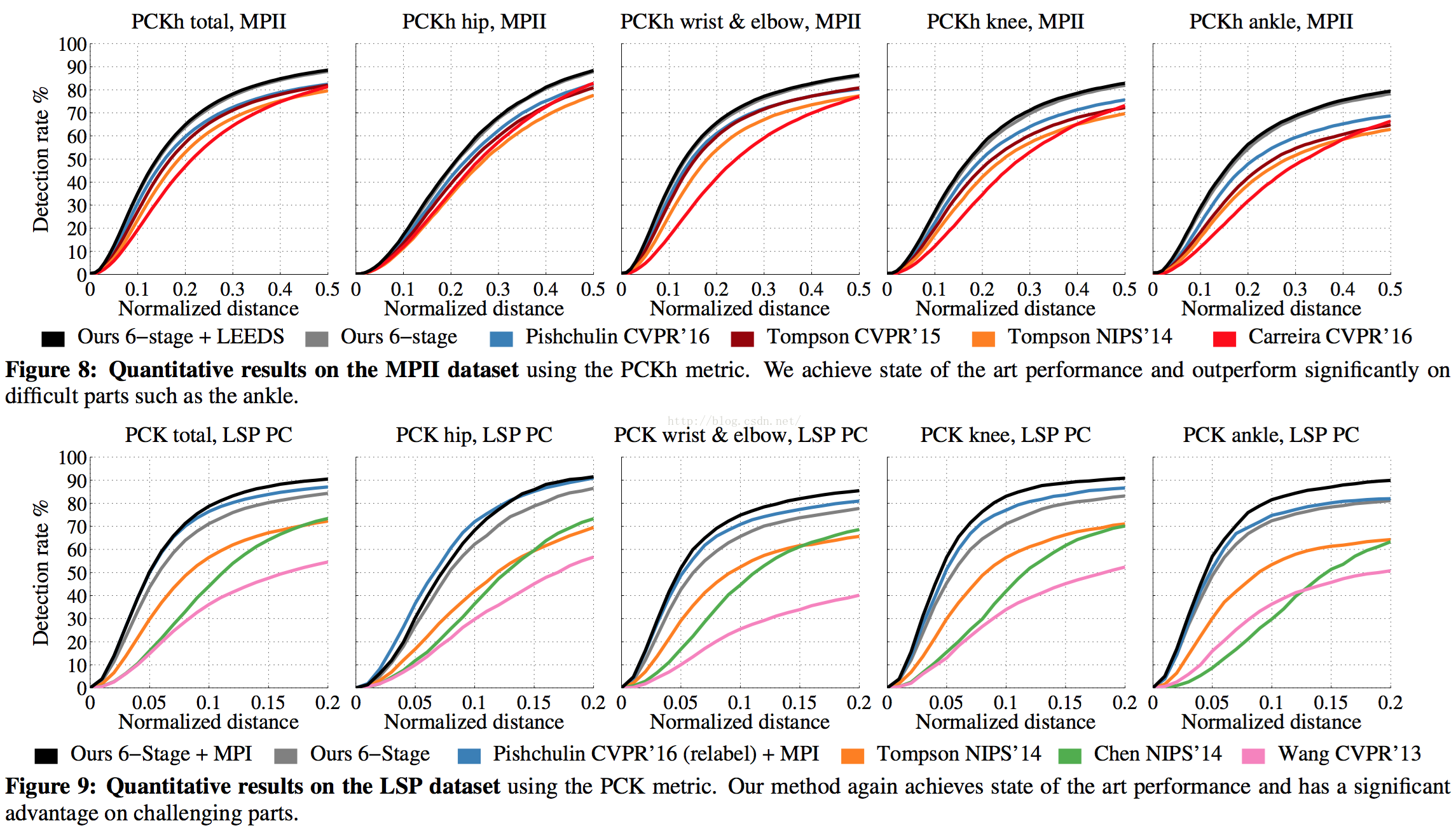
下面这个图是在不同数据库上的相关比较结果。
代码实现
该代码模型为OpenPose的前身,均来自卡内基梅隆大学感知计算实验室Carnegie Mellon University. 实现了单人的姿态检测, 效果还是不错的.
Testing
首先,从github上获取对应代码,github代码
从github上获取了对应代码之后,需要配置caffe: Copy caffePath.cfg.example to caffePath.cfg and set your own path in it. 即把我们编译的caffe路径放进去。注意, 我们的caffe需要编译matlab.
配置好之后,就可以测试代码了。在测试代码之前,需要获得训练好的模型,在终端中输入:
sudo ./testing/get_model.sh
- 1
接下来,我们可以测试程序。其中,./testing/CPM_demo.m为测试程序,该程序指定测试图片并且加载模型进行测试。测试结果如下所示:注意:需要用Matlab打开运行文件:
