SVM
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。
参考:https://blog.csdn.net/v_july_v/article/details/7624837
本文仅仅是对参考博文的学习,拜读之后,只觉奥秘精深。以下内容为选摘,还请阅读原文档。
一、SVM的追根溯源
1.分类标准的起源:Logisitic回归
2.线性分类举例
如下图所示,现在有一个二维平面,平面上有两种不同的数据,分别用圈和叉表示。由于这些数据是线性可分的,所以可以用一条直线将这两类数据分开,这条直线就相当于一个超平面,超平面一边的数据点所对应的y全是-1 ,另一边所对应的y全是1。
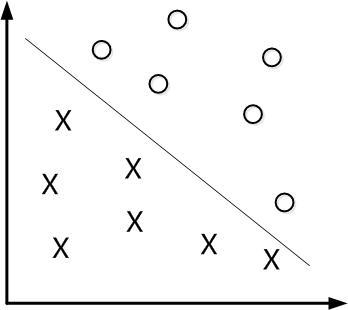
这个超平面可以用分类函数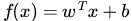
在进行分类的时候,遇到一个新的数据点x,将x代入f(x) 中,如果f(x)小于0则将x的类别赋为-1,如果f(x)大于0则将x的类别赋为1。
接下来的问题是,如何确定这个超平面呢?从直观上而言,这个超平面应该是最适合分开两类数据的直线。而判定“最适合”的标准就是这条直线离直线两边的数据的间隔最大。即寻找有着最大间隔的超平面。
3.函数间隔Functional margin与几何间隔Geometrical margin
在超平面w*x+b=0确定的情况下,|w*x+b|能够表示点x到距离超平面的远近,而通过观察w*x+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用(y*(w*x+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔(functional margin)的概念。
定义函数间隔(用表示)为:
而超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值(其中,x是特征,y是结果标签,i表示第i个样本),便为超平面(w, b)关于训练数据集T的函数间隔:
= mini (i=1,...n)
但这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(虽然此时超平面没有改变),所以只有函数间隔还远远不够。
事实上,我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离--几何间隔(geometrical margin)的概念。
假定对于一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直于超平面的一个向量,为样本x到超平面的距离,如下图所示:

根据平面几何知识,有
其中||w||为w的二阶范数(范数是一个类似于模的表示长度的概念),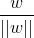
又由于x0 是超平面上的点,满足 f(x0)=0,代入超平面的方程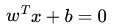
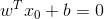
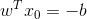
随即让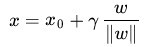
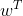
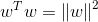
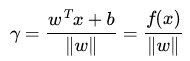
为了得到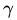
从上述函数间隔和几何间隔的定义可以看出:几何间隔就是函数间隔除以||w||,而且函数间隔y*(wx+b) = y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量,而几何间隔|f(x)|/||w||才是直观上的点到超平面的距离。
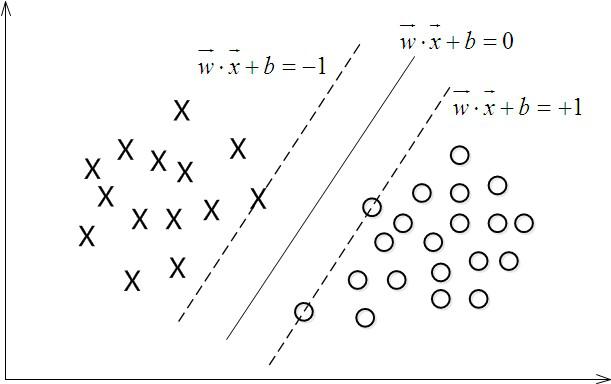
4.最大间隔分类器Maximum Margin Classifier的定义
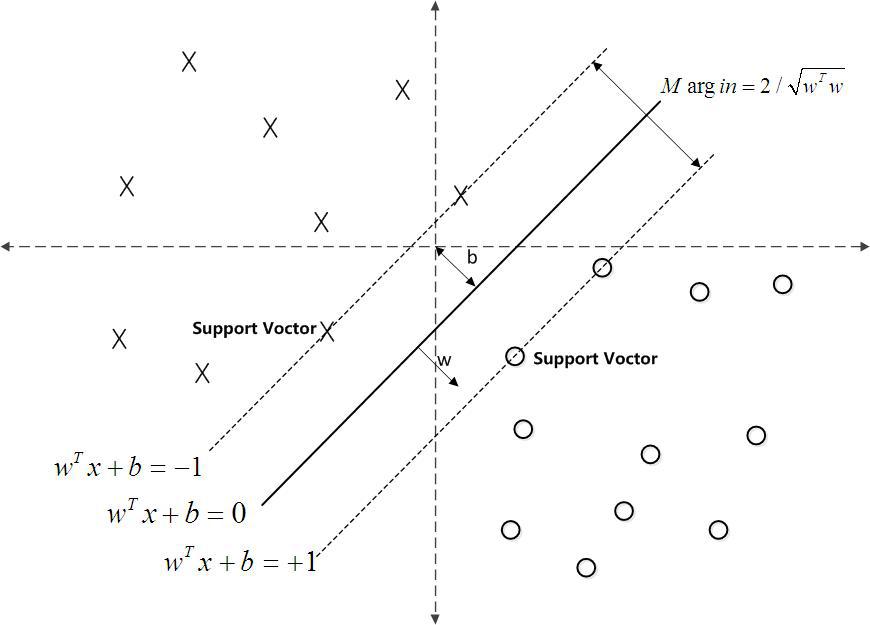
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。
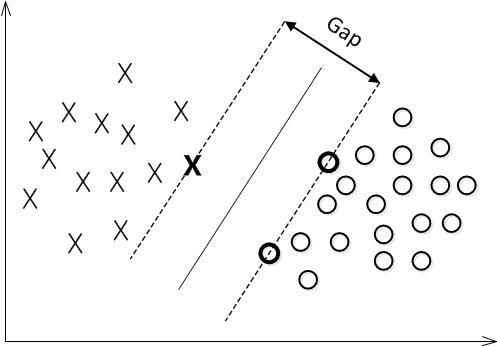
最大间隔分类超平面中的“间隔”指的是几何间隔。于是最大间隔分类器(maximum margin classifier)的目标函数可以定义为:
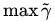
同时需满足一些条件,根据间隔的定义,有

回顾下几何间隔的定义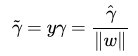
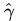
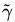
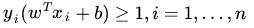

相当于在相应的约束条件
如下图所示,中间的实线便是寻找到的最优超平面(Optimal Hyper Plane),其到两条虚线边界的距离相等,这个距离便是几何间隔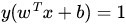
二、深入SVM
1.从线性可分到线性不可分
2.核函数Kernel
3.使用松弛变量处理 outliers 方法
三、证明SVM
1.线性学习器
2.非线性学习器
3.损失函数
4.最小二乘法
5.SMO算法
四、SVM的代码实现
1.Python1
import numpy as np
import operator
from os import listdir
from sklearn.svm import SVC
def img2Vector(filename):
"""
将32*32的二进制图像转换为1*1024的向量
:param filename: 文件名
:return: 返回的二进制图像的1*1024向量
"""
# 创建1*1024零向量
returnVect = np.zeros((1, 1024))
# 打开文件
fr = open(filename)
# 按行读取
for i in range(32):
# 读取一行数据
lineStr = fr.readline()
# 每一行的前32个元素依次添加到returnVect中
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
# 返回转换后的1*1024向量
return returnVect
def handwritingClassTest():
"""
手写数字分类测试
:return: 无
"""
# 测试集的Labels
hwLabels = []
# 返回trainingDigits目录下的文件名
trainingFileList = listdir('E:/python/machine learning in action/My Code/chap 06/trainingDigits')
# 返回文件夹下文件的个数
m = len(trainingFileList)
# 初始化训练的Mat矩阵,测试集
trainingMat = np.zeros((m, 1024))
# 从文件名中解析出训练的类别
for i in range(m):
# 获得文件的名字
fileNameStr = trainingFileList[i]
# 获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
# 将获得的类别添加到hwlabels中
hwLabels.append(classNumber)
# 将每个文件的1*1024数据存储到trainingMat矩阵中
trainingMat[i, :] = img2Vector('E:/python/machine learning in action/My Code/chap 06/trainingDigits/%s' % (fileNameStr))
clf = SVC(C=200, kernel='rbf')
clf.fit(trainingMat, hwLabels)
# 返回testDigits目录下的文件列表
testFileList = listdir('testDigits')
# 错误检测技术
errorCount = 0.0
# 测试数据的数量
mTest = len(testFileList)
# 从文件中解析出测试集的类别并进行分类测试
for i in range(mTest):
fileNameStr = testFileList[i]
classNumber = int(fileNameStr.split('_')[0])
# 获得测试集的1*1024向量,用于训练
vectorUnderTest = img2Vector(
'E:/python/machine learning in action/My Code/chap 06/testDigits/%s' % (fileNameStr))
# 获得预测结果
classfierResult = clf.predict(vectorUnderTest)
print("分类返回结果为 %d \t 真实结果为%d " % (classfierResult, classNumber))
if (classfierResult != classNumber):
errorCount += 1.0
print("总共错了%d个数据 \n 错误率为%f%%" % (errorCount, errorCount / mTest * 100))
if __name__ == '__main__':
handwritingClassTest()
---------------------
作者:呆呆的猫
来源:CSDN
原文:https://blog.csdn.net/jiaoyangwm/article/details/79579784
版权声明:本文为博主原创文章,转载请附上博文链接!2.Python2
https://github.com/Jack-Cherish/Machine-Learning/tree/master/SVM
3.Python3
https://www.ibm.com/developerworks/cn/analytics/library/machine-learning-hands-on1-svn/index.html
4.Java1
package com.linger.svm;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.StringTokenizer;
public class SimpleSvm
{
private int exampleNum;
private int exampleDim;
private double[] w;
private double lambda;
private double lr = 0.001;//0.00001
private double threshold = 0.001;
private double cost;
private double[] grad;
private double[] yp;
public SimpleSvm(double paramLambda)
{
lambda = paramLambda;
}
private void CostAndGrad(double[][] X,double[] y)
{
cost =0;
for(int m=0;m<exampleNum;m++)
{
yp[m]=0;
for(int d=0;d<exampleDim;d++)
{
yp[m]+=X[m][d]*w[d];
}
if(y[m]*yp[m]-1<0)
{
cost += (1-y[m]*yp[m]);
}
}
for(int d=0;d<exampleDim;d++)
{
cost += 0.5*lambda*w[d]*w[d];
}
for(int d=0;d<exampleDim;d++)
{
grad[d] = Math.abs(lambda*w[d]);
for(int m=0;m<exampleNum;m++)
{
if(y[m]*yp[m]-1<0)
{
grad[d]-= y[m]*X[m][d];
}
}
}
}
private void update()
{
for(int d=0;d<exampleDim;d++)
{
w[d] -= lr*grad[d];
}
}
public void Train(double[][] X,double[] y,int maxIters)
{
exampleNum = X.length;
if(exampleNum <=0)
{
System.out.println("num of example <=0!");
return;
}
exampleDim = X[0].length;
w = new double[exampleDim];
grad = new double[exampleDim];
yp = new double[exampleNum];
for(int iter=0;iter<maxIters;iter++)
{
CostAndGrad(X,y);
System.out.println("cost:"+cost);
if(cost< threshold)
{
break;
}
update();
}
}
private int predict(double[] x)
{
double pre=0;
for(int j=0;j<x.length;j++)
{
pre+=x[j]*w[j];
}
if(pre >=0)//这个阈值一般位于-1到1
return 1;
else return -1;
}
public void Test(double[][] testX,double[] testY)
{
int error=0;
for(int i=0;i<testX.length;i++)
{
if(predict(testX[i]) != testY[i])
{
error++;
}
}
System.out.println("total:"+testX.length);
System.out.println("error:"+error);
System.out.println("error rate:"+((double)error/testX.length));
System.out.println("acc rate:"+((double)(testX.length-error)/testX.length));
}
public static void loadData(double[][]X,double[] y,String trainFile) throws IOException
{
File file = new File(trainFile);
RandomAccessFile raf = new RandomAccessFile(file,"r");
StringTokenizer tokenizer,tokenizer2;
int index=0;
while(true)
{
String line = raf.readLine();
if(line == null) break;
tokenizer = new StringTokenizer(line," ");
y[index] = Double.parseDouble(tokenizer.nextToken());
//System.out.println(y[index]);
while(tokenizer.hasMoreTokens())
{
tokenizer2 = new StringTokenizer(tokenizer.nextToken(),":");
int k = Integer.parseInt(tokenizer2.nextToken());
double v = Double.parseDouble(tokenizer2.nextToken());
X[index][k] = v;
//System.out.println(k);
//System.out.println(v);
}
X[index][0] =1;
index++;
}
}
public static void main(String[] args) throws IOException
{
// TODO Auto-generated method stub
double[] y = new double[400];
double[][] X = new double[400][11];
String trainFile = "E:\\project\\workspace\\Algorithms\\bin\\train_bc";
loadData(X,y,trainFile);
SimpleSvm svm = new SimpleSvm(0.0001);
svm.Train(X,y,7000);
double[] test_y = new double[283];
double[][] test_X = new double[283][11];
String testFile = "E:\\project\\workspace\\Algorithms\\bin\\test_bc";
loadData(test_X,test_y,testFile);
svm.Test(test_X, test_y);
}
}
5.Java2
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
import libsvm.svm;
import libsvm.svm_model;
import libsvm.svm_node;
import libsvm.svm_parameter;
import libsvm.svm_problem;
public class SVM {
public static void main(String[] args) {
// 定义训练集点a{10.0, 10.0} 和 点b{-10.0, -10.0},对应lable为{1.0, -1.0}
List<Double> label = new ArrayList<Double>();
List<svm_node[]> nodeSet = new ArrayList<svm_node[]>();
getData(nodeSet, label, "file/train.txt");
int dataRange=nodeSet.get(0).length;
svm_node[][] datas = new svm_node[nodeSet.size()][dataRange]; // 训练集的向量表
for (int i = 0; i < datas.length; i++) {
for (int j = 0; j < dataRange; j++) {
datas[i][j] = nodeSet.get(i)[j];
}
}
double[] lables = new double[label.size()]; // a,b 对应的lable
for (int i = 0; i < lables.length; i++) {
lables[i] = label.get(i);
}
// 定义svm_problem对象
svm_problem problem = new svm_problem();
problem.l = nodeSet.size(); // 向量个数
problem.x = datas; // 训练集向量表
problem.y = lables; // 对应的lable数组
// 定义svm_parameter对象
svm_parameter param = new svm_parameter();
param.svm_type = svm_parameter.EPSILON_SVR;
param.kernel_type = svm_parameter.LINEAR;
param.cache_size = 100;
param.eps = 0.00001;
param.C = 1.9;
// 训练SVM分类模型
System.out.println(svm.svm_check_parameter(problem, param));
// 如果参数没有问题,则svm.svm_check_parameter()函数返回null,否则返回error描述。
svm_model model = svm.svm_train(problem, param);
// svm.svm_train()训练出SVM分类模型
// 获取测试数据
List<Double> testlabel = new ArrayList<Double>();
List<svm_node[]> testnodeSet = new ArrayList<svm_node[]>();
getData(testnodeSet, testlabel, "file/test.txt");
svm_node[][] testdatas = new svm_node[testnodeSet.size()][dataRange]; // 训练集的向量表
for (int i = 0; i < testdatas.length; i++) {
for (int j = 0; j < dataRange; j++) {
testdatas[i][j] = testnodeSet.get(i)[j];
}
}
double[] testlables = new double[testlabel.size()]; // a,b 对应的lable
for (int i = 0; i < testlables.length; i++) {
testlables[i] = testlabel.get(i);
}
// 预测测试数据的lable
double err = 0.0;
for (int i = 0; i < testdatas.length; i++) {
double truevalue = testlables[i];
System.out.print(truevalue + " ");
double predictValue = svm.svm_predict(model, testdatas[i]);
System.out.println(predictValue);
err += Math.abs(predictValue - truevalue);
}
System.out.println("err=" + err / datas.length);
}
public static void getData(List<svm_node[]> nodeSet, List<Double> label,
String filename) {
try {
FileReader fr = new FileReader(new File(filename));
BufferedReader br = new BufferedReader(fr);
String line = null;
while ((line = br.readLine()) != null) {
String[] datas = line.split(",");
svm_node[] vector = new svm_node[datas.length - 1];
for (int i = 0; i < datas.length - 1; i++) {
svm_node node = new svm_node();
node.index = i + 1;
node.value = Double.parseDouble(datas[i]);
vector[i] = node;
}
nodeSet.add(vector);
double lablevalue = Double.parseDouble(datas[datas.length - 1]);
label.add(lablevalue);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}训练数据
17.6,17.7,17.7,17.7,17.8
17.7,17.7,17.7,17.8,17.8
17.7,17.7,17.8,17.8,17.9
17.7,17.8,17.8,17.9,18
17.8,17.8,17.9,18,18.1
17.8,17.9,18,18.1,18.2
17.9,18,18.1,18.2,18.4
18,18.1,18.2,18.4,18.6
18.1,18.2,18.4,18.6,18.7
18.2,18.4,18.6,18.7,18.9
18.4,18.6,18.7,18.9,19.1
18.6,18.7,18.9,19.1,19.3
测试数据
18.7,18.9,19.1,19.3,19.6
18.9,19.1,19.3,19.6,19.9
19.1,19.3,19.6,19.9,20.2
19.3,19.6,19.9,20.2,20.6
19.6,19.9,20.2,20.6,21
19.9,20.2,20.6,21,21.5
20.2,20.6,21,21.5,22