最近在解析百度词库https://shurufa.baidu.com/dict。说一下解决思路吧。
把文件下载下来会发现是字节流。而计算机存储数据有两种方式,大端字节序,小端字节序。
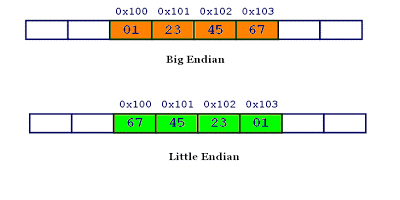
计算机的内部处理都是小端字节序。人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
而百度词库在存储的时候使用了大端存储,但如果想要解析出汉字,需要先将大端存储转为小端存储
def be2le(self):
of = open(self.originfile,'rb')
lef = open(self.lefile, 'wb')
contents = of.read()
contents_size = contents.__len__()
mo_size = (contents_size % 2)
#保证是偶数
if mo_size > 0:
contents_size += (2-mo_size)
contents += contents + b'0000'
#大小端交换
for i in range(0, contents_size, 2):
self.buf[1] = contents[i]
self.buf[0] = contents[i+1]
le_bytes = struct.pack('2B', self.buf[0], self.buf[1])
lef.write(le_bytes)
print('写入成功转为小端的字节流')
of.close()
lef.close()之后再读取字节流,每4位解析成一个汉字字母或者字符。注意百度词库解析是从0x350这个位置开始。再根据规律拼接。经实测搜狗词库的解析上面代码同样适用起始位置改为0x2628.
详情在我的git上https://github.com/zhao-dapeng/Lexicon-analysis/blob/master/baidudict.py好用的话记得点个start