eg.
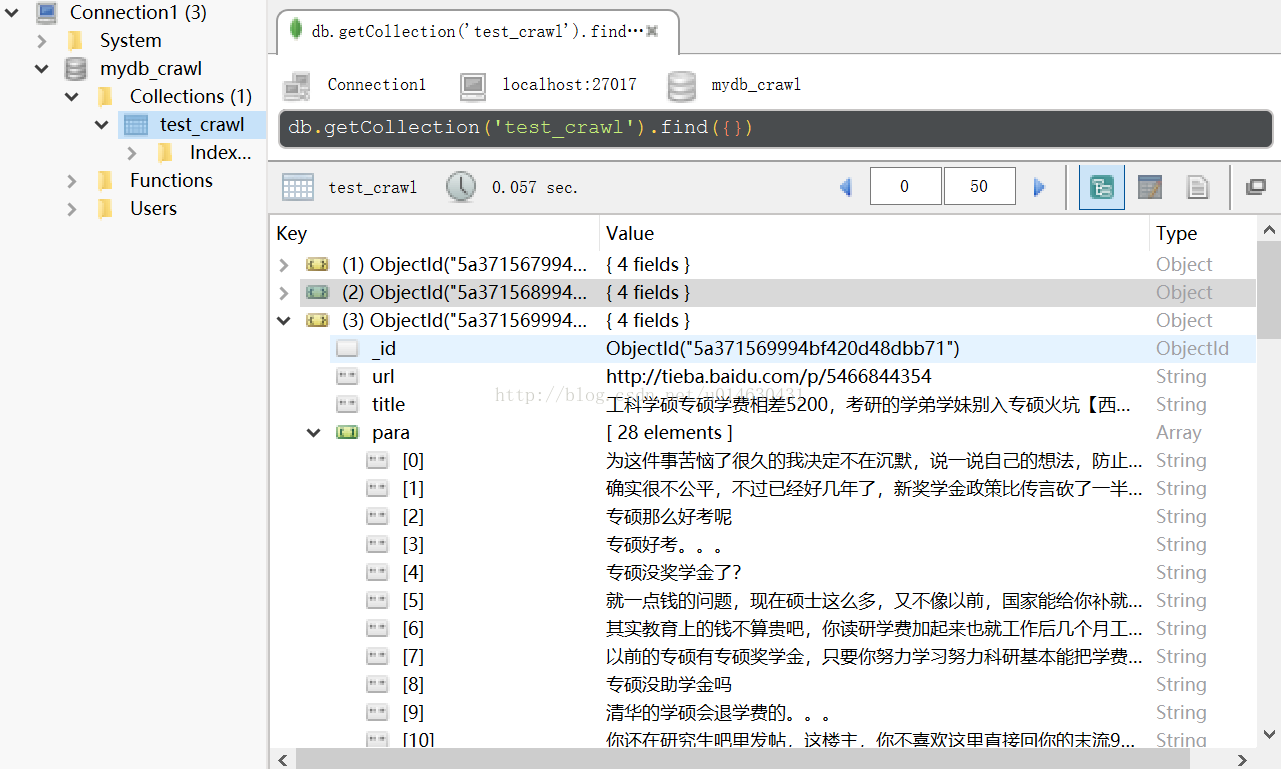
爬取西安交通大学吧内容,并以['url':page_url,'title':title,'para':reply]形式存储到MongoDB数据库。
一、相关信息介绍
爬虫是一段自动抓取互联网信息的程序。一般情况下采取人工方式从互联网上获取少量的信息,爬虫可以从一个URL出发,访问它所关联的URL,并且从每个页面中获取有价值数据。
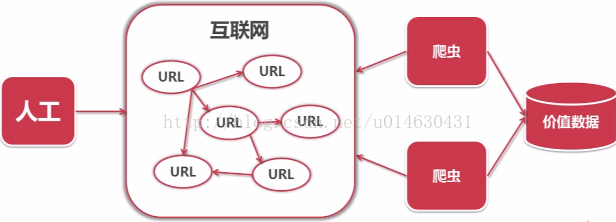
这是轻量级(无需登录和异步加载的静态网页的抓取)网络爬虫的开发,采用python语言编写,主要包括URL管理器、网页下载器(urllib2)、网页解析器(BeautifulSoup),实现百度贴吧网络爬虫相关的页面数据,简单爬虫的架构如下:

简单爬虫架构流程如下:

二、程序按照架构分为以下五个主要的py文件:
config.py -- 配置MongoDB相关信息
from pymongo import MongoClient
conn = MongoClient('127.0.0.1',27017)
db_crawl = conn.mydb_crawl #连接mydb_test数据库,没有则自动创建
my_crawl = db_crawl.test_crawl #使用test_set集合,没有则自动创建
主调度文件为TieBaCrawl.py
# coding:utf8
import html_parser
import url_manager
from Crawl import html_downloader
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtnlDownloader()
self.parser = html_parser.HtmlParser()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print ('craw %d :%s' % (count, new_url))
html_cont = self.downloader.download(new_url)
new_urls = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# if count == 100:
# break
count = count + 1
except:
print ('craw failed')
if __name__ == "__main__":
root_url = "http://tieba.baidu.com/f?kw=%E8%A5%BF%E5%AE%89%E4%BA%A4%E9%80%9A%E5%A4%A7%E5%AD%A6&traceid="
obj_spider = SpiderMain()
obj_spider.craw(root_url)
URL管理器 url_manager.py
# coding:utf8
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
html下载器 html_downloader.py
# coding:utf8
import urllib
from urllib import request
class HtnlDownloader(object):
def download(self, url):
if url is None:
print("url is None")
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200: # ==200网络请求成功的意思,返回这个状态表示已经获取到数据了
print("response.getcode():", response.getcode(),"!=200")
return
return response.read()
html解析器 html_parser.py
# coding:utf8
import re
from urllib import parse
from bs4 import BeautifulSoup
from Crawl.config import *
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a',href=re.compile(r".*\/p\/.*")) #匹配帖子的href
for link in links:
new_url = link['href']
new_full_url = parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
str_ = []
title_node = soup.find('title')#贴吧首页每个帖子都是一个title,点进去每个帖子的title也有标识
title = title_node.get_text()
# print("title:",title)
if soup.find('a',rel = r"noreferrer") is not None:
para_node = soup.find_all('a', rel=r"noreferrer")
else:
para_node = soup.find_all('div',class_="d_post_content_main")
# print(len(para_node))
for node in para_node:
try:
temp = node.get_text()
temp = str(temp).replace(" ","").replace("\n","")
if temp is not "":
if temp in title: #不能获取帖子里二级及其以后的回复内容
print(temp,"in title:",title,"跳过")
else:
str_.append(temp)
except:
pass
my_crawl.insert([{'url':page_url,'title':title,'para':str_}]) #将URL、title、para插入数据库
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
self._get_new_data(page_url,soup)
return new_urls
三、运行结果存储于MongoDB,RoBo 3T可视化显示如下: