网页爬取主要的是对网页内容进行分析,这是进行数据爬取的先决条件,因此博客主要对爬取思路进行下解析,自学的小伙伴们可以一起来学习,有什么不足也可以指出,都是在自学Ing,回归正题今天我们要来爬取百度搜索相关的网页。
首先我们打开度娘,进行搜索
首页网址为:https://www.baidu.com/s?wd=%E6%95%B0%E6%8D%AE&rsv_spt=1&rsv_iqid=0x93e76171000312b4&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=7&rsv_sug1=6&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&inputT=778&rsv_sug4=1116

接着我们点击第二页可以看到网址变更为:https://www.baidu.com/s?wd=数据&pn=10&oq=%E6%95%B0%E6%8D%AE&tn=baiduhome_pg&ie=utf-8&usm=2&rsv_idx=2&rsv_pq=f30ff13f00000cf7&rsv_t=4810mKq3P%2BTmHDnRmpF1eE9P0PvsFC5IpcU%2BHHNq51IATNTDhmKSM1%2Bbr%2BiWFPGYJALE

可以看出搜索栏的数据由wd=数据控制,接着进行第三页、四页、五页点击可以看到pn从第二页的10变成20、30、40,我们可以进行验证:
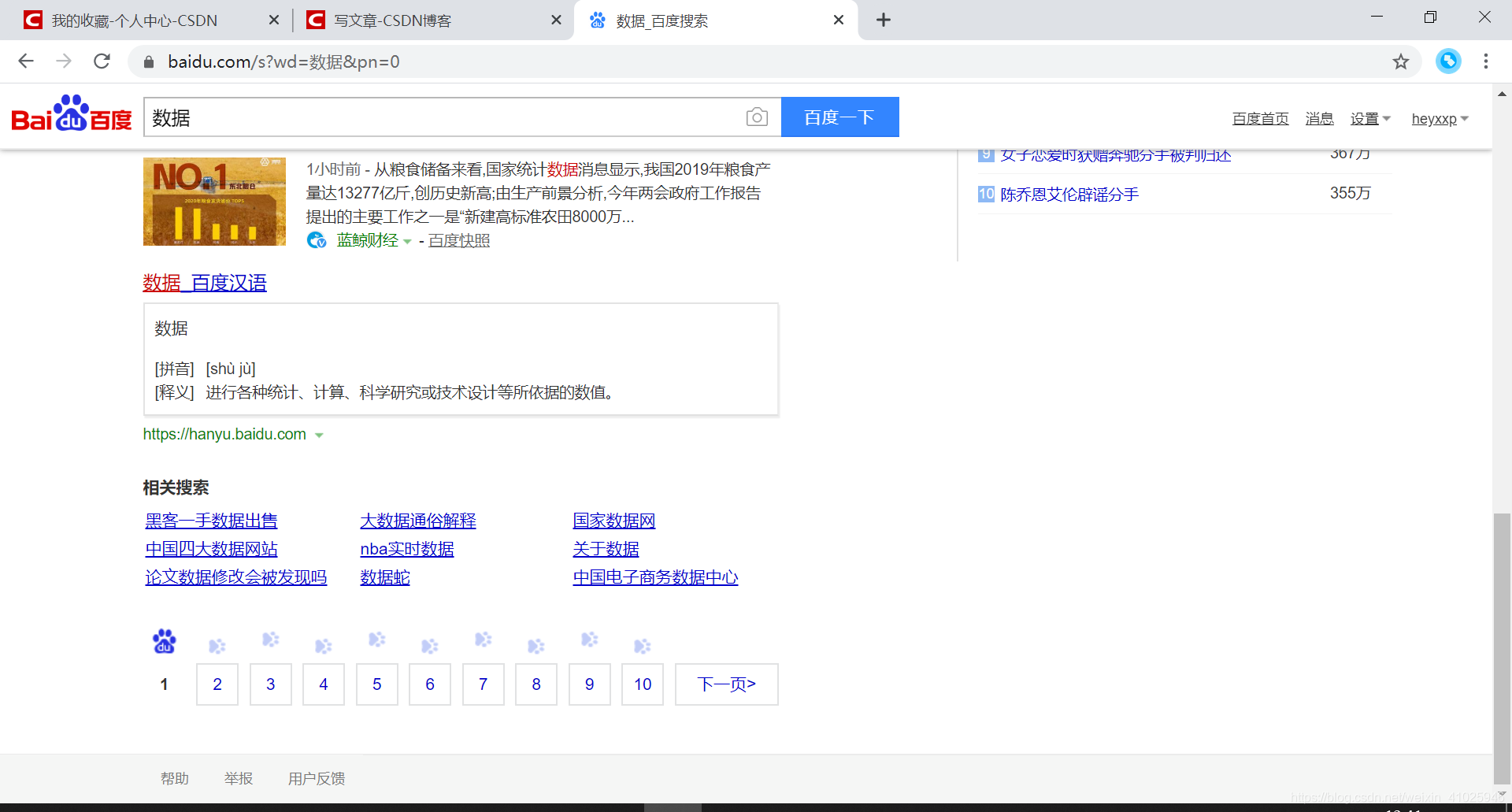
删掉多余的后缀变为https://www.baidu.com/s?wd=数据&pn=0,可以看到输入wd=数据&pn=0时候为第一页,可以多试一些数,发现只要小于10的数,即为首页,
因此可以得出 页数=页数*10-10为搜索对应页码的pn码,
可以写出相应代码获取不同页面:
def get_url(wd,num):
s = requests.session()
#第1页为小于10的数字 10为第2页,20为第三页,30为第四页,以此类推
num=num*10-10
for i in range(-10, num, 10):
url = 'https://www.baidu.com/s'# 点击界面第二页可以看到网页变化截取关键部分 https://www.baidu.com/s?wd=python&pn=10
params = {
"wd": wd,
"pn": i,
}
r = s.get(url=url, headers=headers, params=params)
print("返回状态码:",r.status_code) #可以看对应Js 正常网页访问时候 status状态码 为200
time.sleep(1 + (i / 10))
print("当前页码:",(i+10)/10+1)
if __name__ == '__main__':
while True:#循环
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Host": "www.baidu.com",
}#后续调用
wd = input("输入搜索内容:")
num =int(input("输入页数:"))
get_url(wd,num)
我们再看网页数据传输,
可以看出并没有页面的数据只有搜索栏历史数据的,数据为接口调用。
因此我们考虑从网页元素入手,考虑直接扒拉数据:
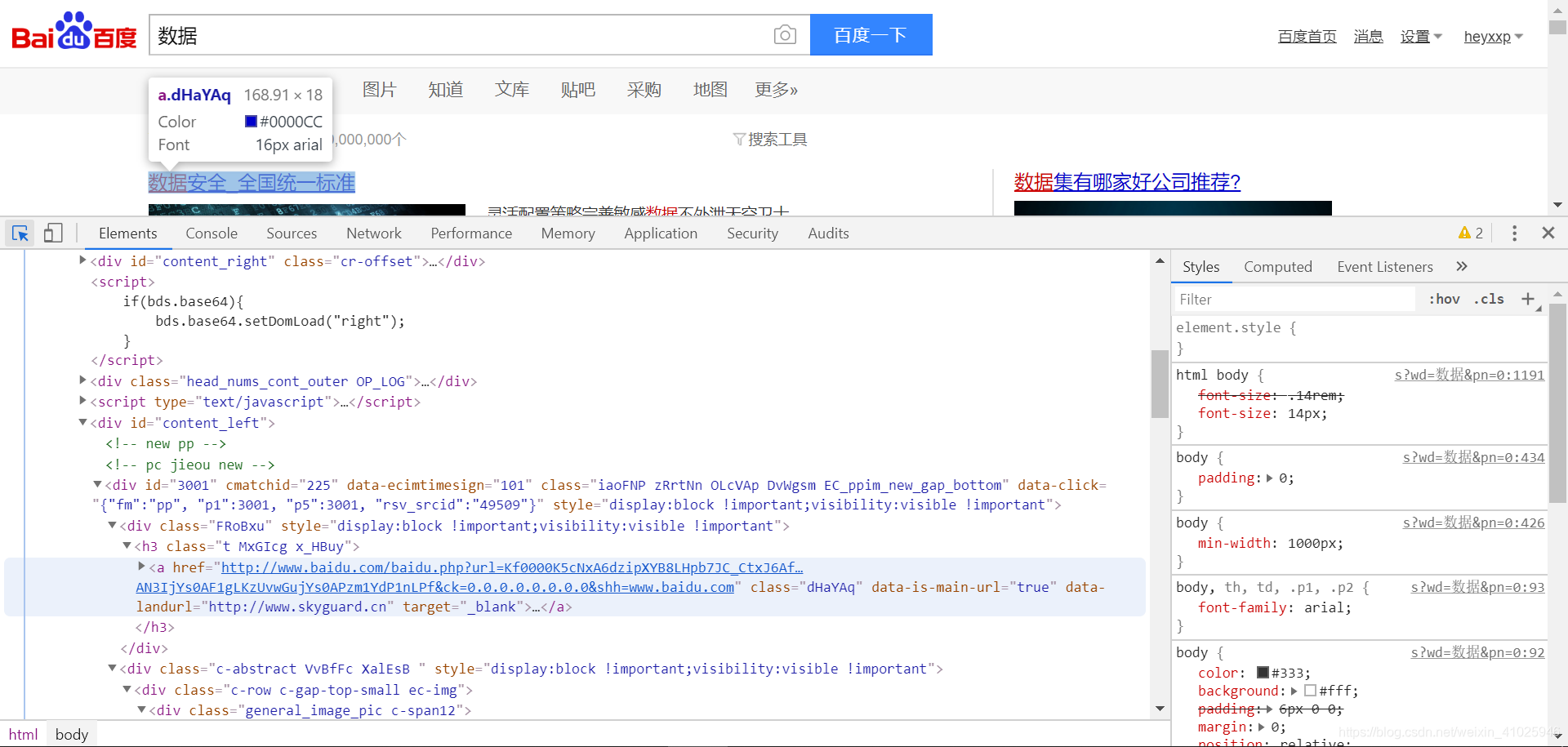
从大方向入手,整个搜索栏下页面布局为:
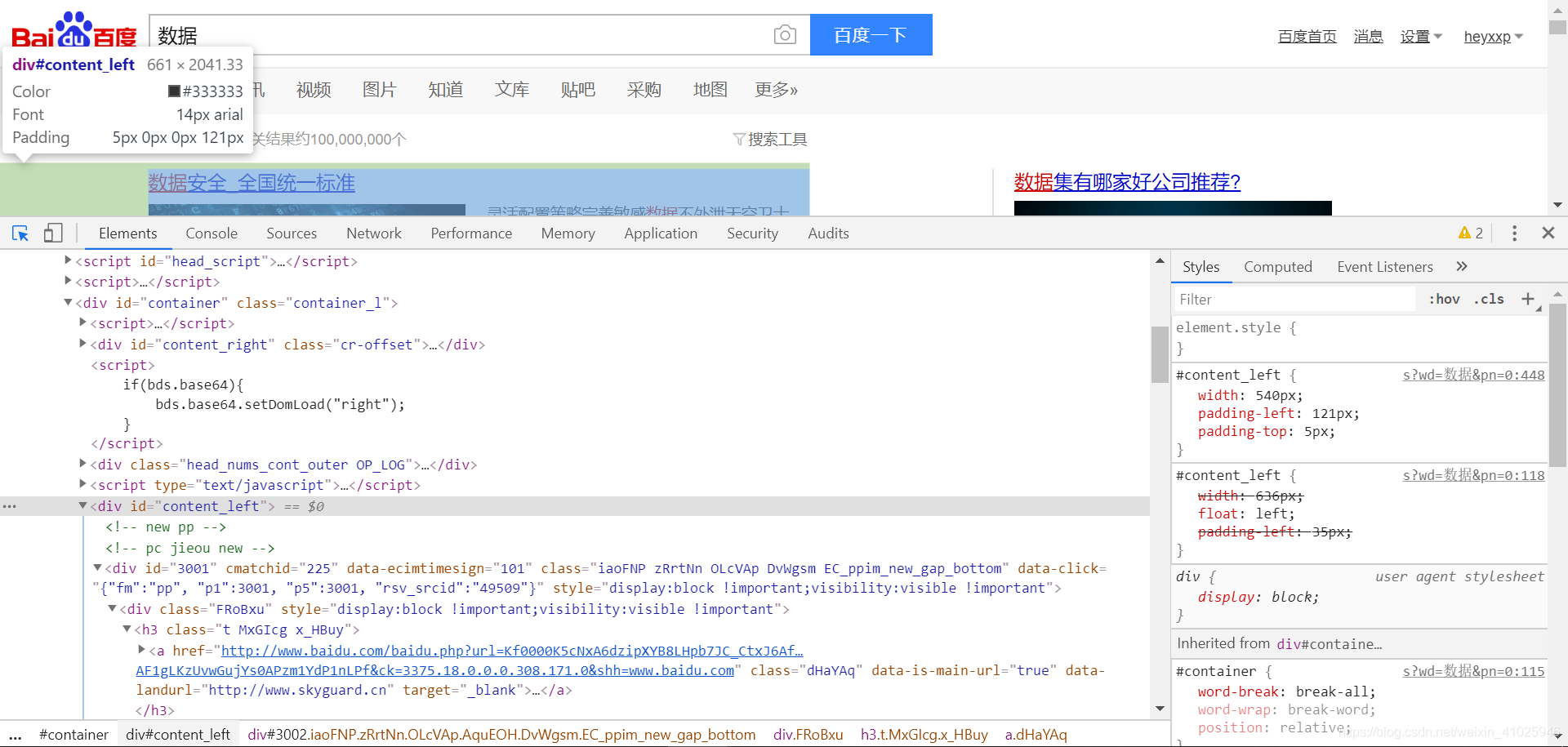

页面的标题数据和Url数据在div id=content_left下方,接着继续用左上角select工具
查看对应标题的网页元素位置

可以看到 class 为t的类名中 a 元素也就是标签可定义锚,
(1、通过使用 href 属性,创建指度向另外一个问文档的链接(或超链接)
2、通过使用 name 或 id 属性,创建一个文档内部的书签(也就是说,可以创建指向文档片段的链接))
中的href为对应搜索网页跳转链接。
但这时候我们会发现比较棘手的事情,对应的搜索标题被分割成搜索关键字(em为网页强调元素)等部分,所以这时候考虑获取当前类下的文本属性即可。
因此可以从对应分析中编写代码:
soup = BeautifulSoup(r.text, 'lxml')
for so in soup.select('#content_left .t a'):
g_url = so.get('href')
g_title=so.get_text().replace('\n','').strip()#根据分析标题无对应标签 只能获取标签内文字 去掉换行和空格
但我们从element分析中得知百度网页获取的url一般为他自己加密的url,因此我们需要进行真实Url获取
#从element里面进行分析,可以知道百度会给一个自己加密的Url
def convert_url(url):
resp = requests.get(url=url,
headers=headers,
allow_redirects=False
)
return resp.headers['Location']
#
#获取url
对应搜索网页页码跳转、数据的获取,真实Url转换3个步骤思路的整合,面向过程的思考模式过后:
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
#从element里面进行分析,可以知道百度会给一个自己加密的Url
def convert_url(url):
resp = requests.get(url=url,
headers=headers,
allow_redirects=False
)
return resp.headers['Location']
#
#获取url
def get_url(wd,num):
s = requests.session()
total_title=[]
total_url=[]
total_info=[]
#第1页为小于10的数字 10为第2页,20为第三页,30为第四页,以此类推
num=num*10-10
for i in range(-10, num, 10):
url = 'https://www.baidu.com/s'# 点击界面第二页可以看到网页变化截取关键部分 https://www.baidu.com/s?wd=python&pn=10
params = {
"wd": wd,
"pn": i,
}
r = s.get(url=url, headers=headers, params=params)
print("返回状态码:",r.status_code) #可以看对应Js 正常网页访问时候 status状态码 为200
soup = BeautifulSoup(r.text, 'lxml')
for so in soup.select('#content_left .t a'):
g_url = convert_url(so.get('href'))#对界面获取的url进行进行访问获取真实Url
g_title=so.get_text().replace('\n','').strip()#根据分析标题无对应标签 只能获取标签内文字 去掉换行和空格
print(g_title,g_url)
total_title +=[g_title]
total_url +=[g_url]
time.sleep(1 + (i / 10))
print("当前页码:",(i+10)/10+1)
try:
total_info=zip(total_title,total_url)
df=pd.DataFrame(data=total_info,columns=['标题','Url'])
df.to_csv(r'C:\Users\xxp\.spyder-py3\testcode\web_data.csv',index=False,encoding='utf_8_sig')
print("保存成功")
except:
return 'FALSE'
if __name__ == '__main__':
while True:#循环
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Host": "www.baidu.com",
}
wd = input("输入搜索内容:")
num =int(input("输入页数:"))
get_url(wd,num)
这样子我们就大功告成啦~,博主这里还有之前写的ajax动态求职网站的数据爬取感兴趣的也可以看下哦