缓存淘汰策略
常见的三种策略:先进先出策略FIFO、最少使用策略LFU、最近最少使用策略LRU
五花八门的 链表结构
(1)链表内存分布

(2)单链表
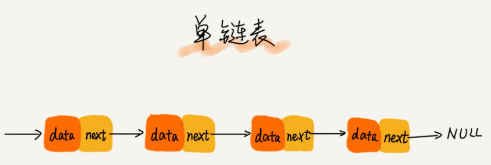
头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。尾节点特殊的地方在于:指针不是指向下一个节点,而是指向一个空地址NULL,表示这是链表的最后一个节点
针对链表的插入和删除操作,我们只需要考虑相邻节点的指针改变,所以对应的时间复杂度是O(1)
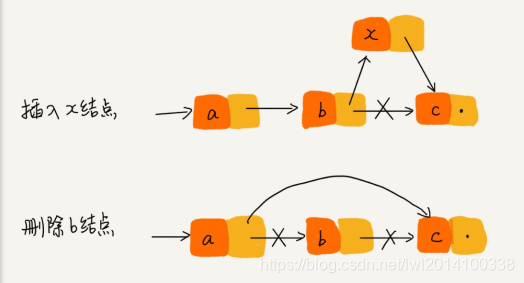
链表随机访问元素,因为链表中数据是非连续存储的,所以需要根据指针一个节点一个节点地依次遍历,直到找到相应的节点,需要O(n)的时间复杂度
(3)循环链表
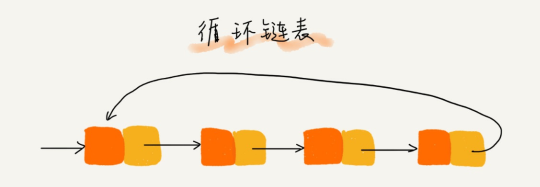
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型数据机构特点时,特别适合采用循环链表
双向链表
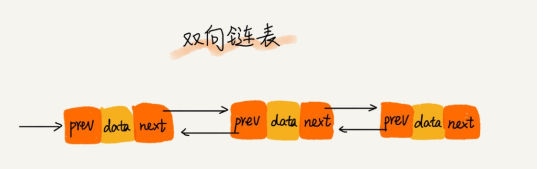
双向链表可以支持O(1)时间复杂度的 情况下找到前驱节点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表要简单、高效。
删除操作

(1) 删除节点中“值等于某个给定值”的节点
(2)删除给定指针指向的节点
对于第一种情况,不管是单链表还是双向链表,为了查找到值等于给定值的节点,都需要从头节点开始一个一个一次遍历对比,直到找到值等于给定值的节点,然后通过指针操作将其删除
对于第二种情况,我们已经找到了要删除的节点,但是删除某个节点q需要知道其前驱节点,而单链表并不支持直接获取前驱节点,所以为了找到前驱节点,我们还需要从头开始遍历链表,直到p->next=q;说明p是 q的前驱节点
但对于双向链表来说,这种情况比较有优势。因为双向链表中保存了前驱节点的指针,不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作O(n)的时间复杂度,而双链表只需要O(1)的时间复杂度即可搞定
Java中LinkedHashMap这个容器就用到了双向链表这种数据结构
设计思想:对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存消耗
链表VS数组
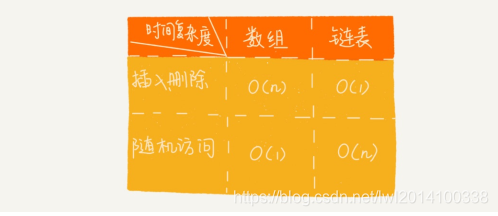
数组简单易用,在实现上使用的是连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,所以访问效率 更高。而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法有效预读
如何基于链表实现LRU缓存淘汰算法
思路:我们维护一个有序单链表,越靠近链表尾部的节点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表
(1) 如果数据之前已经被缓存在链表中,我们遍历得到这个数据对应的节点,并将其从原来的位置删除,然后再插入到链表的头部
(2)如果此数据没有缓存在链表中,又可以分为两种情况
- 如果此时缓存未满,则将此 节点直接插入到链表的头部
- 如果此时缓存已满,则链表尾节点删除,将新的数据节点插入链表的头部
(3)考虑引入散列表(Hashtable)记录每个数据位置,将缓存访问的时间复杂度降到O(1)